
Questo è il primo articolo che si basa su una competizione Kaggle. Nonostante non abbia raggiunto il top della ladder nella competizione, il notebook di riferimento ha ricevuto una medaglia d'oro, che è comunque un ottimo risultato.
Per chi non lo sapesse, Kaggle è una delle piattaforme di riferimento non solo per l'apprendimento e la condivisione di materiale intorno alla data science e al machine learning, ma anche per proporre competizioni basate sui dati.
Aziende importanti, del calibro di Google e Facebook, creano competizioni a premi per chiamare e riunire la community dell'IA ad aiutarli a risolvere problemi importanti che richiedono soluzioni basate sulla IA.
In questa competizione, l'obiettivo è di creare un modello in grado di valutare la competenza linguistica di studenti liceali che studiano l'inglese.
Condividerò con voi come ho modellato i dati e la strategia generale di risoluzione al problema, andando commentare il codice scritto e il suo output in modo che possiate integrare parti della pipeline in un vostro progetto simile.
Trovate il link alla competizione qui

Mentre trovate qui il link al notebook Kaggle.
Contesto
Partiamo dal problema che vogliamo risolvere. Tradotto dalla scheda descrizione della competizione
L'obiettivo di questa competizione è valutare la competenza linguistica degli studenti di lingua inglese di grado 8-12 (ELL). L'utilizzo di un set di dati di saggi scritti da ELL aiuterà a sviluppare modelli di competenza che supportino meglio tutti gli studenti.
Il tuo lavoro aiuterà gli ELL a ricevere un feedback più accurato sul loro sviluppo linguistico e ad accelerare il ciclo di valutazione per gli insegnanti. Questi risultati potrebbero consentire agli ELL di ricevere compiti di apprendimento più appropriati che li aiuteranno a migliorare la loro conoscenza della lingua inglese.
Il nostro obiettivo è chiaro: sviluppare un modello che aiuta gli enti formativi a sviluppare percorsi formativi più chiari per migliorare la competenza linguistica degli studenti.
Il dataset
Il dataset comprende saggi argomentativi scritti da studenti di lingua inglese di grado 8-12 (ELL). I saggi sono stati valutati secondo sei misure analitiche:
- coesione
- sintassi
- vocabolario
- fraseologia
- grammatica
- convenzioni
Ogni misura rappresenta una componente di competenza nella scrittura, con punteggi maggiori corrispondenti a una maggiore competenza in quella misura.
I punteggi vanno da 1 a 5 con incrementi di 0,5.
Il nostro compito è prevedere il punteggio di ciascuna delle sei misure per i saggi forniti nel set di test.
Come spesso si vede nelle competizioni Kaggle, i dataset forniti sono divisi in train e test.
Ecco come si presenta il dataset
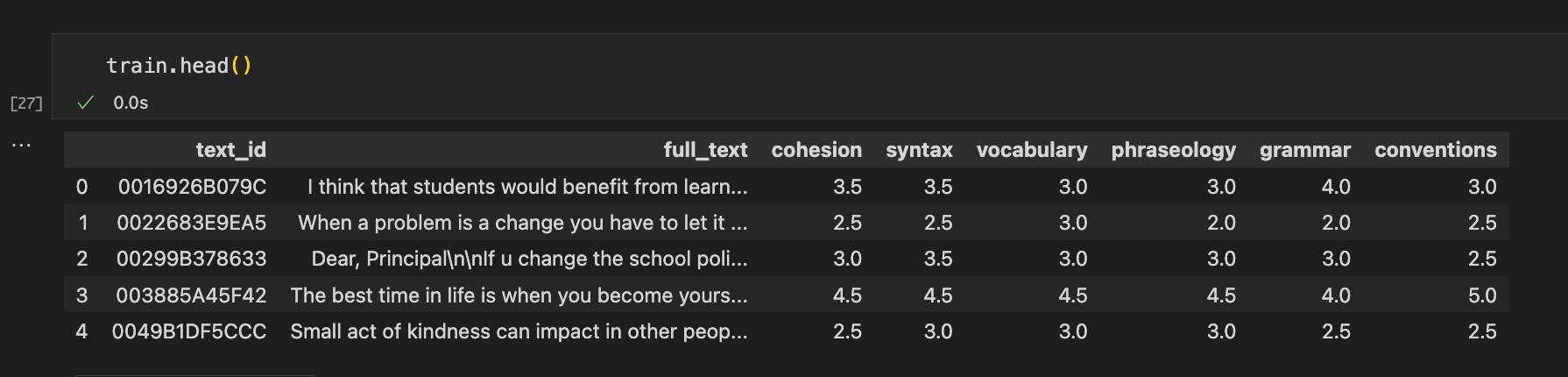
- text_id: identificativo del testo scritto dallo studente
- full_text: testo scritto dallo studente
- cohesion: punteggio di valutazione della coesione del testo
- syntax: punteggio di valutazione della sintassi del testo
- vocabulary: punteggio di valutazione della del vocabolario usato nel testo
- phraseology: punteggio di valutazione della fraseologia del testo
- grammar: punteggio di valutazione della grammatica del testo
- conventions: punteggio di valutazione della convenzioni del testo
Setup del progetto
Iniziamo ad importare le dipendenze del progetto. Ci serviranno
- pandas e numpy
- Sklearn, PyTorch e SentenceTransformer
- Matplotlib e seaborn
- NLTK
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
tqdm.pandas()
from sklearn import model_selection
from sklearn import metrics
import string
from nltk.corpus import stopwords
from sentence_transformers import SentenceTransformerImportiamo i nostri dati e stabiliamo le feature e etichette
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')
sample_submission = pd.read_csv('./data/sample_submission.csv')
features = ["full_text"]
labels = ["cohesion", "syntax", "vocabulary", "phraseology", "grammar", "conventions"]Analisi esplorativa del dato (EDA)
Uno degli step fondamentali in qualsiasi progetto di analisi e di modellazione predittiva è quello dell'esplorazione del dato.
Questa attività permette di comprendere meglio il dato e scoprire se esistono errori, associazioni, correlazioni e altre dinamiche nei dati.
Per chi è interessato a leggere un articolo dedicato alla analisi esplorativa, linko un articolo qui in basso.
 Andrea D’Agostino
Andrea D’Agostino
Per questo progetto la terremo facile - andremo solo a disegnare le distribuzioni delle variabili e la heatmap di correlazioni.
# Creiamo righe e colonne per disegnare i grafici
plt.figure(figsize=(16, 6))
for i, label in enumerate(labels):
plt.subplot(2, 3, i + 1)
plt.hist(train[label], bins=20)
plt.title(label)
plt.suptitle("Label distributions")
plt.show()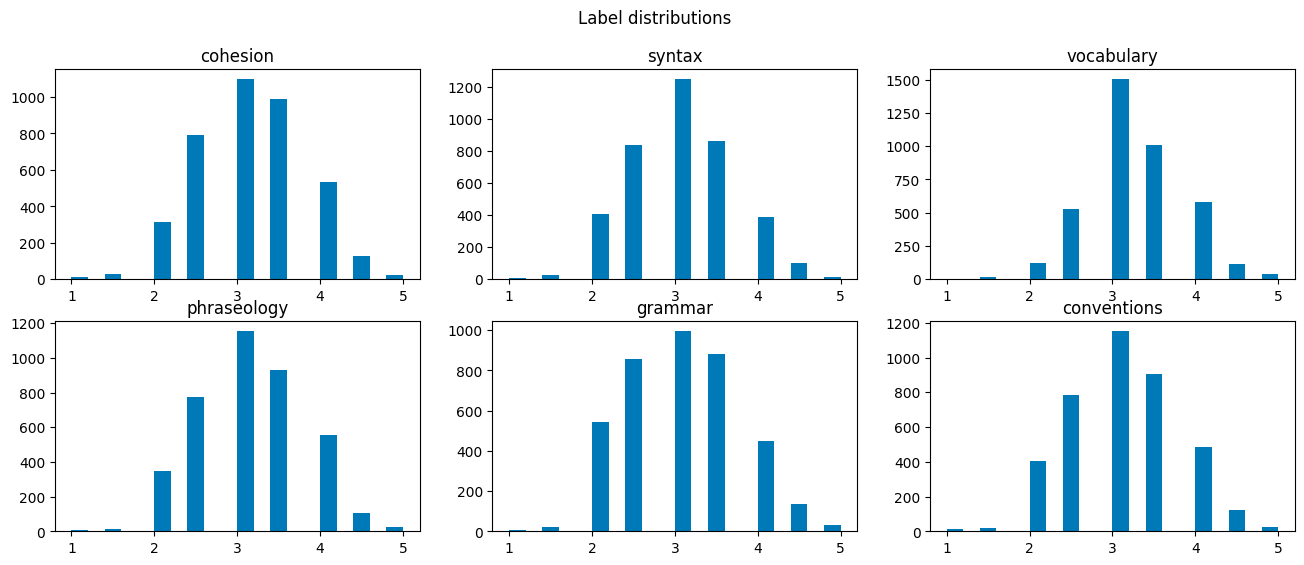
Le distribuzioni sono abbastanza simili - questo ci informa che non ci sono anomalie e correzioni da fare.
plt.figure(figsize=(10, 5))
sns.heatmap(train[labels].corr(), annot=True, square=False, vmin=-1, vmax=1)
plt.title("Correlation between labels")
plt.show()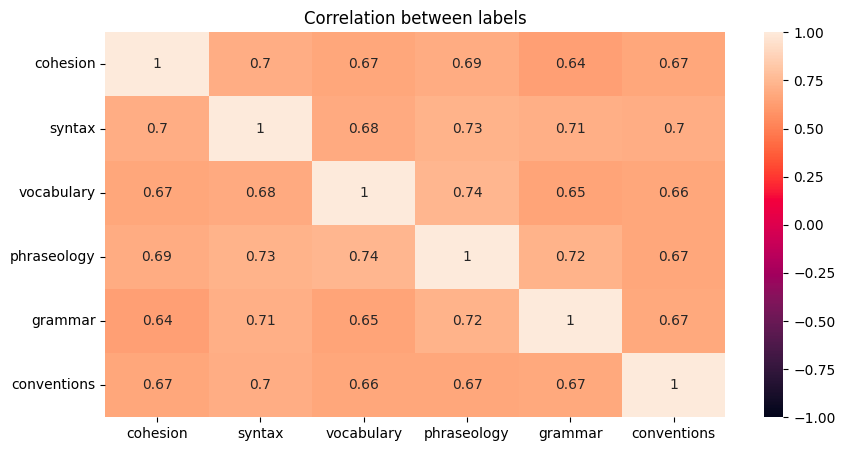
La matrice di correlazione evidenzia che le variabili sono generalmente associate tra di loro. Quando un testo è scritto bene per una variabile, allora tale testo tende a mostrare la stessa performance anche per un'altra.
Un modello predittivo potrebbe riuscire ad imparare in maniera efficiente a generalizzare su questi dati. Dobbiamo quindi lavorare sull'encoding del testo.
La motivazione è da trovarsi proprio nel compito da risolvere: per valutare la coesione, sintassi, vocabolario, etc. è importante valutare completamente il testo, senza trasformazioni.
L'utilizzo di punteggiatura e termini specifici contribuiscono alla predizione dei target, e vanno quindi ritenuti.
Approccio alla modellazione
L'idea è di creare una rete neurale in grado di imparare dagli embedding del testo scritto dagli studenti per predire le variabili target.
È utile ragionare su questo step prima di lavorare sui dati, la pipeline di preparazione richiede una idea chiara su come dev'essere fornito il dato al modello.
Il modello può essere disegnato così
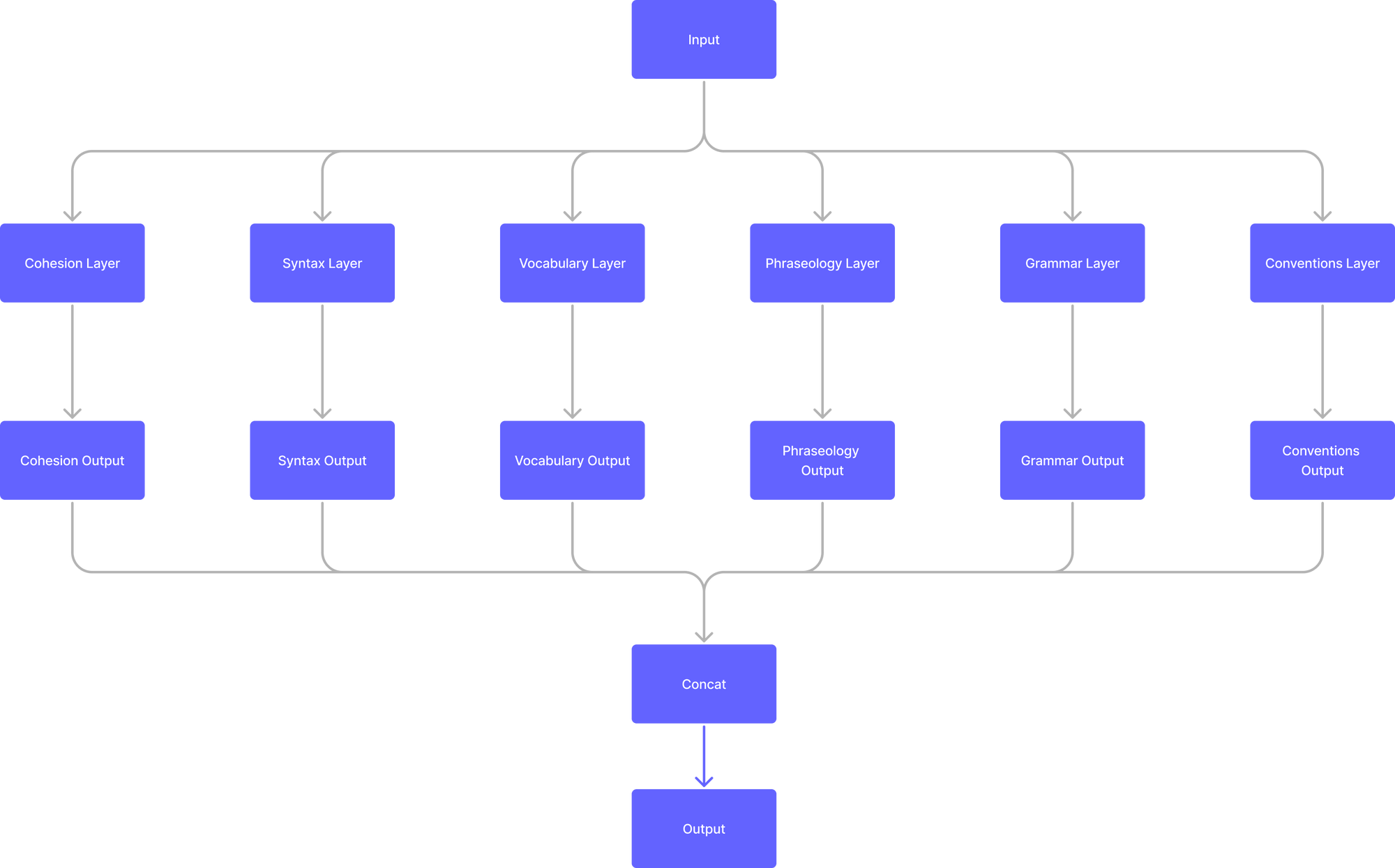
L'idea è quindi che ci siano dei rami nel modello dedicati alla predizione di ogni variabile e che poi questi convergano in un singolo output concatenato.
Ora passiamo all'approccio pratico: esplorazione, split in set di addestramento e validazione, caricamento dei dati nel modello e scrittura del modello stesso.
Split in set di addestramento e validazione
Useremo sklearn.model_selection per dividere preparare i nostri dati in set di addestramento e validazione.
x_train, x_val, y_train, y_val = model_selection.train_test_split(train[features].values, train[labels].values, test_size=0.2, random_state=42)
print(x_train.shape, x_val.shape, y_train.shape, y_val.shape)
>> (3128, 1) (783, 1) (3128, 6) (783, 6)
Encoding del testo in embedding
Useremo il modello all-MiniLM-L6-v2 di SentenceTransformer per convertire i testi scritti dagli studenti in tensori.
Gli embedding sono rappresentazioni vettoriali in grado di descrivere le relazioni tra parole e quindi tra concetti e contesti diversi.
Andrea D’Agostino
Ecco il codice per fare l'encoding
embedding_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
train_embeddings = embedding_model.encode(x_train[:, 0], batch_size=200, show_progress_bar=True)
val_embeddings = embedding_model.encode(x_val[:, 0], batch_size=200, show_progress_bar=True)
test_embeddings = embedding_model.encode(test[features].values[:, 0], batch_size=200, show_progress_bar=True)
print(train_embeddings)
>> array([[-0.09318926, 0.00423619, 0.02815985, ..., 0.00752447,
-0.06652465, -0.02501139],
[ 0.04237603, -0.02704737, 0.01021558, ..., 0.05896651,
-0.13489658, 0.02803236],
[ 0.02641385, 0.04102813, -0.08502118, ..., -0.00755973,
-0.0864008 , 0.01873737],
...,
[ 0.05361762, 0.05990427, 0.00647471, ..., 0.06769853,
-0.07111193, 0.05109518],
[ 0.03240207, -0.03758994, 0.07875723, ..., 0.01599755,
-0.12521371, 0.04028842],
[ 0.00951448, 0.08904066, 0.0581084 , ..., 0.05006377,
-0.08251362, -0.00287952]], dtype=float32)Ora useremo Dataset e DataLoader di PyTorch per caricare i nostri dati all'interno del modello.
Creazione di Dataset e DataLoader
Poiché useremo PyTorch per creare il modello, useremo le classi Dataset e DataLoader per formattare i nostri dati correttamente.
Il dataset accetterà gli embedding e le variabili target. Invito il lettore interessato a leggere questo articolo di introduzione a PyTorch per comprendere meglio le dinamiche di Dataset e DataLoader.
class EnglishLanguageProficiency(Dataset):
def __init__(self, embeddings, cohesion, syntax, vocabulary, phraseology, grammar, conventions):
self.features = torch.tensor(embeddings, dtype=torch.float32)
self.cohesion = torch.tensor(cohesion, dtype=torch.float32)
self.syntax = torch.tensor(syntax, dtype=torch.float32)
self.vocabulary = torch.tensor(vocabulary, dtype=torch.float32)
self.phraseology = torch.tensor(phraseology, dtype=torch.float32)
self.grammar = torch.tensor(grammar, dtype=torch.float32)
self.conventions = torch.tensor(conventions, dtype=torch.float32)
def __len__(self):
return self.features.shape[0]
def __getitem__(self, idx):
x = self.features[idx]
y = torch.stack([
self.cohesion[idx],
self.syntax[idx],
self.vocabulary[idx],
self.phraseology[idx],
self.grammar[idx],
self.conventions[idx]
])
return {
'x': x,
'y': y
}Creare i dataset e loader è semplice:
train_dataset = EnglishLanguageProficiency(train_embeddings, y_train[:, 0], y_train[:, 1], y_train[:, 2], y_train[:, 3], y_train[:, 4], y_train[:, 5])
val_dataset = EnglishLanguageProficiency(val_embeddings, y_val[:, 0], y_val[:, 1], y_val[:, 2], y_val[:, 3], y_val[:, 4], y_val[:, 5])
train_loader = DataLoader(
dataset=train_dataset,
batch_size=16,
shuffle=True,
drop_last=True
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=16,
shuffle=False,
drop_last=True
)Ora scriveremo il modello che riceverà questi dati in input e produrrà delle predizioni.
Rete neurale in PyTorch
La rete neurale è scritta in PyTorch ed è di fatto un modello di regressione, cioè di predizione di un valore numerico.
class RegressionModel(nn.Module):
def __init__(self, n_features, n_outputs):
super().__init__()
self.n_features = n_features
self.n_outputs = n_outputs
self.cohesion_layer = nn.Linear(self.n_features, self.n_outputs)
self.syntax_layer = nn.Linear(self.n_features, self.n_outputs)
self.vocabulary_layer = nn.Linear(self.n_features, self.n_outputs)
self.phraseology_layer = nn.Linear(self.n_features, self.n_outputs)
self.grammar_layer = nn.Linear(self.n_features, self.n_outputs)
self.conventions_layer = nn.Linear(self.n_features, self.n_outputs)
def forward(self, x):
cohesion = self.cohesion_layer(x)
syntax = self.syntax_layer(x)
vocabulary = self.vocabulary_layer(x)
phraseology = self.phraseology_layer(x)
grammar = self.grammar_layer(x)
conventions = self.conventions_layer(x)
return torch.cat([cohesion, syntax, vocabulary, phraseology, grammar, conventions], dim=1)Questo modello riceverà gli embedding in input, di dimensione train_embeddings.shape[1] e n_output 1.
Ciclo di addestramento
Ora scriveremo il codice per addestrare il modello, usando come funzione di perdita MSE (mean squared error).
model = RegressionModel(n_features=train_embeddings.shape[1], n_outputs=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, factor=0.1, verbose=True)
criterion = nn.MSELoss()
epoch_train_losses = []
epoch_val_losses = []
epoch_train_rmse = []
epoch_val_rmse = []
num_epochs = 30
for epoch in tqdm(range(num_epochs)):
train_losses = []
val_losses = []
model = model.train()
for data in train_loader:
x = data['x']
y = data['y']
y_pred = model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss.item())
model = model.eval()
for data in val_loader:
x = data['x']
y = data['y']
y_pred = model(x)
loss = criterion(y_pred, y)
val_losses.append(loss.item())
epoch_train_losses.append(np.mean(train_losses))
epoch_val_losses.append(np.mean(val_losses))
epoch_train_rmse.append(np.sqrt(np.mean(train_losses)))
epoch_val_rmse.append(np.sqrt(np.mean(val_losses)))
scheduler.step(np.mean(val_losses))
if (epoch+1) % 5 == 0:
print(f"Epoch: {epoch+1}/{num_epochs}, Train Loss: {np.mean(train_losses):.3f}, Val Loss: {np.mean(val_losses):.3f}, Train RMSE: {np.sqrt(np.mean(train_losses)):.3f}, Val RMSE: {np.sqrt(np.mean(val_losses)):.3f}")
plt.title("Train vs Val Loss")
plt.plot(epoch_train_losses, label="Train Loss")
plt.plot(epoch_val_losses, label="Val Loss")
plt.legend()
plt.grid()
plt.show()
>>
20%|██ | 6/30 [00:00<00:02, 9.01it/s]
Epoch: 5/30, Train Loss: 0.630, Val Loss: 0.617, Train RMSE: 0.794, Val RMSE: 0.786
37%|███▋ | 11/30 [00:01<00:02, 9.16it/s]
Epoch: 10/30, Train Loss: 0.501, Val Loss: 0.492, Train RMSE: 0.708, Val RMSE: 0.701
53%|█████▎ | 16/30 [00:01<00:01, 9.18it/s]
Epoch: 15/30, Train Loss: 0.433, Val Loss: 0.431, Train RMSE: 0.658, Val RMSE: 0.657
70%|███████ | 21/30 [00:02<00:00, 9.24it/s]
Epoch: 20/30, Train Loss: 0.393, Val Loss: 0.398, Train RMSE: 0.627, Val RMSE: 0.631
87%|████████▋ | 26/30 [00:02<00:00, 9.24it/s]
Epoch: 25/30, Train Loss: 0.367, Val Loss: 0.376, Train RMSE: 0.606, Val RMSE: 0.613
100%|██████████| 30/30 [00:03<00:00, 9.11it/s]
Epoch: 30/30, Train Loss: 0.349, Val Loss: 0.362, Train RMSE: 0.591, Val RMSE: 0.601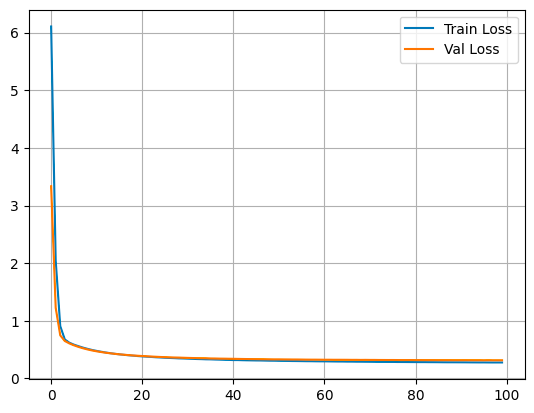
Le due curve diminuiscono insieme ed è una indicazione di apprendimento. Non si nota overfitting.
Inferenza su testi nuovi
Ora possiamo usare il modello per creare delle predizioni su dati non visti. Kaggle fornisce un set di test di testi da valutare.
Ecco il codice Python per creare nuove predizioni con il nostro modello
with torch.inference_mode():
test_preds = model(torch.tensor(test_embeddings, dtype=torch.float32))
test_preds = test_preds.numpy()
test_preds = pd.DataFrame(test_preds, columns=labels)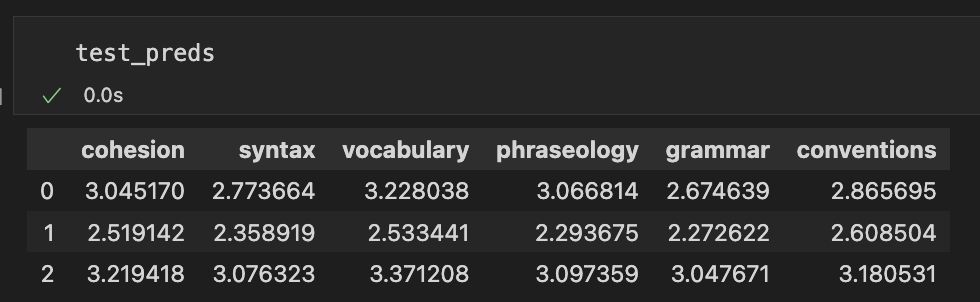
E ora siamo pronti ad unire queste predizioni al dataframe di test.
test.merge(test_preds, left_index=True, right_index=True)
Conclusioni
In questo articolo ho mostrato come, in modo semplice, sia possibile creare una rete neurale in PyTorch sfruttando il transfer learning - cioè facendo leva sugli embedding, quindi l'apprendimento di grosse reti neurali, per risolvere un task di natura linguistica.
È sicuramente possibile migliorare tale approccio e architettura del modello. Ad esempio, si potrebbe fare feature engineering e aggiungere altre variabili che provengono dal testo, come lo score Flesch-Kincaid che indica il grado di leggibilità del testo.
Condivido anche il link al repository Github di questo progetto.
 andrea-dagostino
andrea-dagostinoAlla prossima 👋
Commenti dalla community