
Tabella dei Contenuti
Nel campo dell'apprendimento automatico, le prestazioni dei modelli sono spesso dettate dalla scelta degli iperparametri.
Gli iperparametri sono impostazioni che governano il processo di addestramento e l'architettura di un modello di machine learning.
La regolazione fine di questi parametri può portare a miglioramenti significativi nell'accuratezza e nell'efficienza del modello. Tuttavia, la regolazione manuale degli iperparametri può essere un compito noioso e dispendioso in termini di tempo. È qui che entra in gioco Optuna, un potente framework di ottimizzazione degli iperparametri in Python progettato per automatizzare e semplificare il processo di ottimizzazione.
Optuna offre un approccio flessibile ed efficiente all'ottimizzazione degli iperparametri, consentendo agli utenti di definire una funzione obiettivo che incapsula le prestazioni del proprio modello.
Sfruttando tecniche come la potatura (pruning) e l'ottimizzazione sequenziale, Optuna può convergere rapidamente sui migliori iperparametri, riducendo al minimo il tempo dedicato alle regolazioni manuali.
Questo articolo ti guiderà attraverso il processo di utilizzo di Optuna per l'ottimizzazione degli iperparametri, concentrandosi in particolare sulla sua integrazione con Scikit-Learn.
- Cosa è il tuning degli iperparametri e il suo significato nell'apprendimento automatico
- Come usare la libreria Optuna per l'ottimizzazione degli iperparametri
- Implementazioni pratiche di ottimizzazione degli iperparametri utilizzando Optuna con Scikit-Learn
Iniziamo!
Cosa è l'ottimizzazione degli iperparametri e casi d'uso
L'ottimizzazione degli iperparametri è una componente essenziale del ciclo di vita del machine learning, applicabile a vari domini e modelli.
Come spiego nell'articolo Cos'è il Machine Learning: la definizione di un data scientist, la fase di ricerca e ottimizzazione degli iperparametri è proprio parte del ciclo vitale di un progetto di machine learning.

Difficilmente vedremo un processo di machine learning che non copre la parte di ottimizzazione degli iperparametri.
Definiamo prima cosa è un iperparametro.
Un iperparametro del modello è una configurazione esterna ad esso il cui valore non può essere stimato dai dati. Modificare un iperparametro modifica di conseguenza il comportamento del modello sui nostri dati e può migliorare o peggiorare le nostre performance.
Un iperparametro può essere max_depth in un albero decisionale, oppure il numero di cluster in un algoritmo di clustering come il KMeans.
Essendo quindi una attività integrante del processo di machine learning, è importante poter trovare efficacemente (e possibilmente anche velocemente) tali iperparametri. Optuna nasce proprio per questo.
Ecco alcuni scenari in cui un'ottimizzazione efficace degli iperparametri può fare una differenza significativa:
- Classificazione delle immagini: la regolazione fine dei parametri nelle reti neurali convoluzionali (CNN) può portare a una maggiore precisione nella classificazione delle immagini, con un impatto sulle applicazioni nel settore sanitario, della sicurezza e dei social media.
- Elaborazione del linguaggio naturale (NLP): l'ottimizzazione degli iperparametri in modelli come i Transformer può migliorare le prestazioni in attività quali analisi del sentiment, traduzione e riepilogo.
- Previsioni finanziarie: negli algoritmi di trading, la messa a punto precisa degli iperparametri può portare a modelli di previsione migliori, che in ultima analisi influiscono sulla redditività e sulla gestione del rischio.
Si capisce quindi che Optuna può essere usato sia per gli algoritmi di machine learning tradizionale, sia per le reti neurali e quindi applicazioni di deep learning.
Optuna aiuta proprio in questo caso, perché ci farà settare una strategia di ottimizzazione che andrà sempre a puntare verso la diminuzione/massimizzazione della metrica di valutazione delle performance.
Cosa è Optuna?
Optuna è un framework di ottimizzazione degli iperparametri open source semplice da utilizzare ma sufficientemente potente per attività di ottimizzazione complesse.

Il suo design è incentrato sulla flessibilità e sulle prestazioni. Optuna consente agli utenti di definire spazi di ricerca e strategie di ottimizzazione gestendo automaticamente le prove e il tracciamento dei risultati. Ciò porta a un processo di ottimizzazione più efficiente rispetto alla griglia tradizionale o ai metodi di ricerca casuale.
Optuna offre tre caratteristiche principali
- Ricerca automatizzata di iperparametri ottimali utilizzando condizionali, loop e sintassi Python
- Cerca in modo efficiente spazi ampi ed elimina le prove (trials) poco promettenti per ottenere risultati più rapidi
- Parallelizza le ricerche degli iperparametri su più thread o processi senza modificare il codice
Ecco un esempio di come si implementa Optuna in progetto Sklearn, che vedremo a breve in più dettaglio.
import sklearn
import optuna
# 1. Definire una funzione obiettivo da massimizzare/minimizzare
def objective(trial):
# 2. Suggerire valori per gli iperparametri
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
if classifier_name == 'SVC':
svc_c = trial.suggest_float('svc_c', 1e-10, 1e10, log=True)
classifier_obj = sklearn.svm.SVC(C=svc_c, gamma='auto')
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32, log=True)
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth, n_estimators=10)
...
return accuracy
# 3. Crea un oggetto di studio e ottimizza la funzione obiettivo per 100 iterazioni
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)Esempio di Optuna con Scikit-Learn
Per illustrare le capacità di Optuna, analizziamo un esempio pratico utilizzando il framework Scikit-Learn e sfruttando il Titanic Dataset di Kaggle.
Questo dataset ci darà modo proprio di confrontare cosa succede con e senza tuning degli iperparametri, poiché non è composto da poche righe e costituisce uno dei primi dataset su cui un data scientist inizia a lavorare..
Se vuoi seguire con la lettura, ecco il link alla competizione Kaggle che ti permette di accedere al dataset

Ecco come appare il dataset
Questo articolo non coprirà l'adeguato preprocessing e gestione delle variabili categoriali, ma mostrerà degli step di base che permetteranno l'addestramento del modello.
L'ambiente Kaggle contiene già Optuna ed Sklearn installati, ma nel caso si voglia usarle al di fuori di Kaggle e in un ambiente proprio, usare il comando per installarle
pip install optuna scikit-learn
Vediamo la performance del nostro modello senza fare tuning degli iperparametri.
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
train['Age'] = train['Age'].fillna(train['Age'].median())
# Codifica delle variabili categoriali
label_encoder = LabelEncoder()
train['Sex'] = label_encoder.fit_transform(train['Sex'])
train['Cabin'] = label_encoder.fit_transform(train['Cabin'])
train['Embarked'] = label_encoder.fit_transform(train['Embarked'])
# Divisione di feature e target
X = train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Survived'])
y = train['Survived']
# Split di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creazione modello RandomForest per la classificazione
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
# Predizione e metrica di accuratezza
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy}")
>>> Accuracy: 0.8044692737430168Questo è un modello di base, non ottimizzato. Vediamo ora come Optuna può aumentare le performance del modello, senza toccare i dati di addestramento.
...
# Definizione della funzione obiettivo
def objective(trial):
# Diciamo ad Optuna quali iperparametri deve scegliere e in che modo
n_estimators = trial.suggest_int('n_estimators', 10, 100)
max_depth = trial.suggest_int('max_depth', 1, 32)
min_samples_split = trial.suggest_int('min_samples_split', 2, 10)
# Crea un modello Random Forest Classifier
clf = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
random_state=42
)
# Addestramento del modello
clf.fit(X_train, y_train)
# Predizione e valutazione
preds = clf.predict(X_test)
accuracy = accuracy_score(y_test, preds)
return accuracy
# Crea l'esperimento in Optuna
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=20)
# Stampa i migliori iperparametri e la corrispondente precisione
print("Best hyperparameters: ", study.best_params)
print("Best accuracy: ", study.best_value)>>> [I 2024-07-21 15:14:25,662] A new study created in memory with name: no-name-a2fcacbe-1f73-464d-9172-eef4f7fbb58a
[I 2024-07-21 15:14:25,743] Trial 0 finished with value: 0.8100558659217877 and parameters: {'n_estimators': 23, 'max_depth': 14, 'min_samples_split': 2, 'min_samples_leaf': 2}. Best is trial 0 with value: 0.8100558659217877.
[I 2024-07-21 15:14:26,062] Trial 1 finished with value: 0.8324022346368715 and parameters: {'n_estimators': 86, 'max_depth': 9, 'min_samples_split': 7, 'min_samples_leaf': 9}. Best is trial 1 with value: 0.8324022346368715.
...
[I 2024-07-21 15:14:45,264] Trial 49 finished with value: 0.8212290502793296 and parameters: {'n_estimators': 32, 'max_depth': 6, 'min_samples_split': 2, 'min_samples_leaf': 2}. Best is trial 47 with value: 0.8435754189944135.
Best hyperparameters: {'n_estimators': 65, 'max_depth': 10, 'min_samples_split': 3, 'min_samples_leaf': 3}
Best accuracy: 0.8435754189944135Alla fine delle sue 50 iterazioni, Optuna è riuscito a trovare una combinazione di iperparametri che ci fa guadagnare un solido 4.35% rispetto alla baseline.
In alcuni casi, un tale aumento di performance potrebbe essere cruciale! Immaginiamo se un modello sottoposto ad un tuning del genere fosse dedicato a creare offerte commerciali per clienti e che la metrica fosse correlata al tasso di conversione. Sarebbe un aumento molto significativo.
È proprio per questo motivo che il tuning degli iperparametri è così importante e fa parte del ciclo di vita di un progetto di machine learning - gli effetti sono concretamente utili a patto che abbiamo risorse computazionali e tempo da allocare.
Alcuni modelli possono avere oltre 50 iperparametri. Per questo motivo, ho creato Parametro, una leggerissima applicazione web che ti permette di trovare gli iperparametri del tuo modello e di implementarli nella tua codebase con un semplice click.
Supporta Sklearn, XGBoost e altri modelli di ML tradizionale.


Anatomia della funzione obiettivo di Optuna
Guardiamo più attentamente questa parte di codice per comprendere cosa fa Optuna dietro le quinte.
def objective(trial):
n_estimators = trial.suggest_int('n_estimators', 10, 100)
max_depth = trial.suggest_int('max_depth', 1, 32)
min_samples_split = trial.suggest_int('min_samples_split', 2, 10)
clf = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
random_state=42
)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
accuracy = accuracy_score(y_test, preds)
return accuracy
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=20)Focalizziamoci sulle prime tre righe - n_estimators, max_depth e min_samples_split. Cosa sono questi? Sono gli iperparametri che abbiamo scelto di ottimizzare per il modello RandomForestClassifier.
Se usiamo la documentazione di Sklearn, vediamo i loro valori di default all'inizializzazione
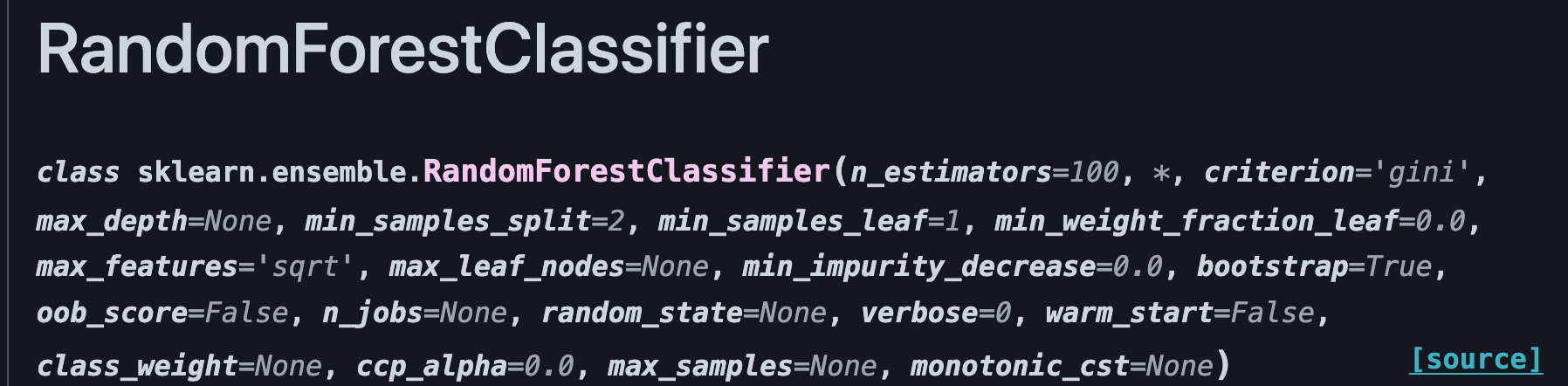
Vediamo come il valore predefinito di n_estimators sia 100, 2 per min_samples_split e così via.
Optuna va a sovrascrivere questi valori e a valutare il modello ad ogni iterazione usando i metodi come .suggest_int(). È qui che avviene la magia di Optuna - il suggerimento cambia dinamicamente, in base alle performance ad ogni iterazione. Se una serie di iperparametri influenzano positivamente la performance del modello ed altri no, allora Optuna si concentrerà proprio ad ottimizzare quelli che offrono il delta maggiore nella performance finale.
Usando .suggest_int(<nome_iperparametro>, inizio, fine) stiamo dicendo ad Optuna che per quel iperparametro, cerca partendo dal primo valore e finisci all'ultimo, passando per tutti quelli in mezzo.
Infine c'è la direzione minimize oppure maximize - in base al problema, classificazione (come in questo caso) o regressione, vorremo minimizzare l'errore o massimizzare l'accuratezza. In questo caso stiamo usando la accuratezza, e quindi vogliamo massimizzarla.
n_trials è un valore importante che definisce per quante iterazioni Optuna deve fare ottimizzazione. Non c'è un limite, e bisogna tarare quel valore in base al caso d'uso.
Conclusioni
Con questo articolo hai imparato cosa sono gli iperparametri, cosa è Optuna e come usarlo per ottimizzare gli iperparametri dei modelli della suite Sklearn.
Va precisato che Optuna può essere usato per qualsiasi modello, non solo quelli di Sklearn. Può essere infatti usato anche per le reti neurali, testando il numero e il tipo di strati neurali sia in PyTorch che Keras / TensorFlow.
L'ottimizzazione degli iperparametri è un passaggio cruciale nello sviluppo di modelli robusti di machine learning e andrebbe sempre fatto se possibile. Incorporando Optuna nel tuo flusso di lavoro, puoi automatizzare e migliorare il processo di ottimizzazione, ottenendo migliori prestazioni del modello con meno sforzo manuale.





Commenti dalla community