
Questo articolo mostrerà come preparare dei testi per applicazioni basate su reti neurali.
Dato un corpus di dati testuali, applicheremo il seguente processo
- mappatura della singola parola del testo (token) ad un indice
- creazione di token specifici per fine frase, padding e simboli non appartenenti al vocabolario
- conversione dei termini presenti in dizionario in tensori
Il vocabolario organizzerà i nostri dati in formato chiave: valore dove la chiave sarà il termine e il valore sarà un indice numerico intero associato a quel termine. Saranno presenti dei token speciali che avranno queste caratteristiche
- __PAD__: indica il simbolo del padding
- </e>: indica end of line (fine della frase)
- __UNK__: indica un simbolo sconosciuto, non appartenente al dizionario
Questo lavoro sarà molto utile perché fornirà un template per creare l'input al nostro generatore di dati (data generator in gergo del deep learning) in maniera facile ed efficiente.
Il Dataset
Useremo il dataset fornito da Sklearn, 20newsgroups, per avere rapido accesso ad un corpus di dati testuali. A scopo dimostrativo, userò solo un campione di 10 testi.
import numpy as np
from sklearn.datasets import fetch_20newsgroups
# categorie dalle quali prenderemo i nostri dati
categories = [
'comp.graphics',
'comp.os.ms-windows.misc',
'rec.sport.baseball',
'rec.sport.hockey',
'alt.atheism',
'soc.religion.christian',
]
# primi 10 elementi
dataset = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=('headers', 'footers', 'quotes'))
corpus = [item for item in dataset['data'][:10]]
corpus
Su questi testi applicheremo un preprocessing semplice, per pulire le frasi da stop word e caratteri speciali.
Il Processo
Funzione di preprocessing
La funzione di preprocessing è la seguente
import re
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
def preprocess_text(text: str) -> str:
"""Funzione che pulisce il testo in input andando a
- rimuovere i link
- rimuovere i caratteri speciali
- rimuovere i numeri
- rimuovere le stopword
- trasformare in minuscolo
- rimuovere spazi bianchi eccessivi
Argomenti:
text (str): testo da pulire
Restituisce:
str: lista di token puliti
"""
# rimuovi link
text = re.sub(r"http\S+", "", text)
# rimuovi numeri e caratteri speciali
text = re.sub("[^A-Za-z]+", " ", text)
# rimuovere le stopword
# 1. crea token
tokens = nltk.word_tokenize(text)
# 2. controlla se è una stopword
tokens = [w.lower() for w in tokens if not w in stopwords.words("english")]
return tokensQuesta funzione è usabile per qualsivoglia problema di elaborazione del linguaggio naturale, non solo questo presente nell'articolo.
Creazione del vocabolario
Lavorare con un vocabolario ci permette di mappare termine ad indice. L'indice sarà l'elemento che verrà convertito a tensore.
def get_vocab(training_corpus):
# includiamo caratteri speciali aggiuntivi
# padding, fine di linea, termine sconosciuto
vocab = {'__PAD__': 0, '__</e>__': 1, '__UNK__': 2}
# costruiremo il vocabolario solo con i dati di training
for item in training_corpus: # iteriamo nel nostro corpus
processed_text = preprocess_text(item) # applichiamo preprocessing al testo
for word in processed_text: # per ogni parola contenuto nel testo (token)
if word not in vocab: # se la parola non è presente nel dizionario
vocab[word] = len(vocab) # crea una chiave che è uguale al termine, e il suo valore è uguale alla lunghezza del vocabolario
return vocab
vocab = get_vocab(corpus)L'output sarà il seguente
Da testo a tensori
Scriveremo una funzione che utilizzerà il dizionario per creare una rappresentazione numerica dei termini presenti in quest'ultimo. Questi numeri saranno inseriti in una lista e rappresenteranno i tensori da applicare in un task di deep learning.
Non utilizzeremo TensorFlow, PyTorch o Numpy per questo esempio, così da spiegare fondamentalmente come avviene il processo.
Partiremo dalla funzione text_to_tensor
def text_to_tensor(text: str, vocab_dict: dict, unk_token='__UNK__', verbose=False):
'''
Argomenti:
text - stringa contenente il testo
vocab_dict - il dizionario di termini
unk_token - il carattere speciale usato per identificare i termini sconosciuti
verbose - stampaggio di messaggi di debug
Restituisce:
tensor_l - una lista di indici che rappresentano numericamente il nostro testo
'''
word_l = preprocess_text(text)
if verbose:
print("Lista delle parole presenti nel testo:")
print(word_l)
# Inizializziamo una lista vuota che conterrà i tensori
tensor_l = []
# Prendiamo il valore di __UNK__ token
unk_ID = vocab_dict[unk_token]
if verbose:
print(f"Il valore di UNK è {unk_ID}")
# per ogni parola nella lista:
for word in word_l:
# prendiamo il suo indice
# e se la parola non è presente nel dizionario, usiamo UNK ID
word_ID = vocab_dict.get(word, unk_ID)
# inseriamo il valore nella lista finale
tensor_l.append(word_ID)
return tensor_l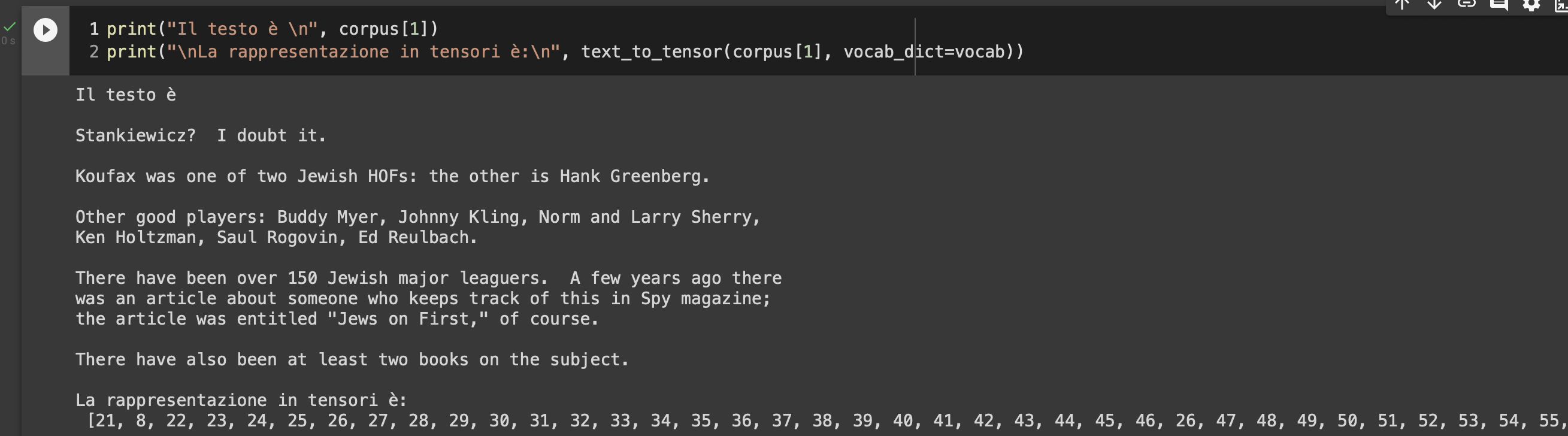
Ora possiamo procedere a usare i nostri tensori per creare un batch_generator e un modello di deep learning, come una LSTM.





Commenti dalla community