
Tabella dei Contenuti
Questo articolo ti guiderà attraverso l'utilizzo di ollama, uno strumento da linea di comando che permette il download, l'esplorazione e l'utilizzo di Large Language Models (LLM) sul tuo PC.
Per la fine di questo articolo avrai modo di lanciare modelli in locale e interrogarli via Python grazie ad un endpoint dedicato. Tali modelli saranno completamente personalizzabili.
- cosa è ollama e perché ci semplifica la vita nell'utilizzare LLM sul proprio pc
- come usare ollama da terminale
- come usare ollama via Python
Iniziamo.
Cosa è ollama?
ollama è uno strumento open source che permette la gestione facilitata di LLM sul proprio PC.
Supporta praticamente tutti i modelli open source più nuovi e popolari di Hugging Face e permette anche di caricarne dei nuovi direttamente via la sua interfaccia da riga di comando.
È disponibile sia via Github che attraverso il sito web ufficiale, dove è possibile scaricare le versioni per Windows, Mac e Linux.
Il progetto Github è disponibile qui:
 ollama
ollamaPerché usare LLM in locale con ollama?
Iniziare ad usare modelli open source non è proprio facilissimo. ollama si mette tra lo sviluppatore che vuole integrare i modelli nel suo software e lo strato alquanto macchinoso di processi che è in altro modo obbligato ad implementare a mano.
ollama quindi velocizza e semplicizza i processi di:
- selezione e download del modello, grazie alla sua facilissima interfaccia
- configurazione di un endpoint di inferenza
- integrazione con una codebase Python o JavaScript
Sembra poco, ma non lo è.
Mentre scaricare un modello non è complicato (basta andare su Hugging Face ed è possibile farlo per la maggior parte dei modelli), configurarlo e implementarlo per farlo "partire" può essere un processo lento e non senza sfide, soprattutto in ambienti poco supportati come Windows.
ollama, con pochissimi comandi, permette di avere un LLM open source in ascolto sulla nostra macchina pronto sia a conversare che a rispondere a chiamate API.
Per impostazione predefinita, su Linux e Windows, ollama tenterà di utilizzare le GPU Nvidia o Radeon e utilizzerà tutte le GPU che riesce a trovare, quindi l'accelerazione è garantita senza dover toccare nulla nel caso in cui abbiamo una scheda video di ultima generazione.
Building LLMs for Production: Enhancing LLM Abilities and Reliability with Prompting, Fine-Tuning, and RAG
Louis-François Bouchard, Louie Peters
Questo libro è una guida completa per migliorare le competenze e comprendere i modelli generativi e linguistici di grandi dimensioni (LLM).

Tour delle funzionalità di ollama
Una volta installato, ollama permette di essere evocato via terminale attraverso il comando ollama.
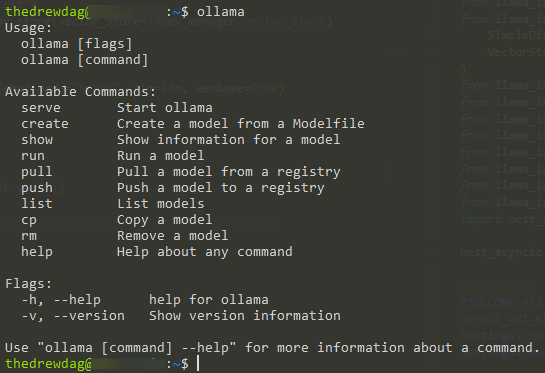
Vediamo i comandi a disposizione più importanti:
serve: fa partire ollama nel caso in cui il processo fosse spentoshow: mostra la informazioni su un modello specificorun: permette di eseguire un modello precedentemente scaricato. Se il modello non è presente, ollama inizierà a scaricarlopull: scarica un modello, senza eseguirlo una volta terminatolist: stampa su schermo la lista dei modelli disponibili sulla macchinarm: rimuove un modello dal PC
Gli altri comandi non verranno trattati in questo articolo poiché sono inerenti al caricamento di modelli nuovi sul registro ollama.
Per avere una lista completa dei modelli disponibili su ollama puoi visitare questo link 👇

Esempio: come scaricare e usare il modello Mistral in locale
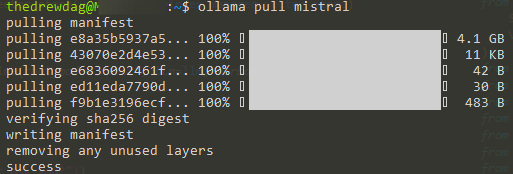
Mistral è uno dei modelli più famosi nello spazio open source della IA generativa. Vediamo quanto è facile scaricarlo com ollama con il comando pull.

Dopo pochi minuti il modello è pronto per essere usato sulla macchina.
Ora è possibile conversare con Mistral con il comando ollama run mistral
Chiedo a Mistral "How can I use large language models on my local pc?" (come posso usare un LLM in locale sul mio pc?) e il modello risponde correttamente. L'inferenza è molto veloce su una Nvidia RTX 4080.

Come usare ollama in Python
Ovviamente ci interessa poter usare Mistral direttamente in Python. Il team di ollama ha messo a disposizione una pacchetto che è possibile scaricare con il comando pip install ollama.
Vediamo come usare Mistral per generare del testo in base a delle stringhe in input in un semplice programma Python, controllando il prompt di sistema e quello dell'utente.
import ollama
response = ollama.chat(model='mistral', messages=[
{
"role": "system",
"content": "You are an expert at creating brief poems about animals"
},
{
"role": "user",
"content": "Write a poem about a dog"
},
])
print(response['message']['content'])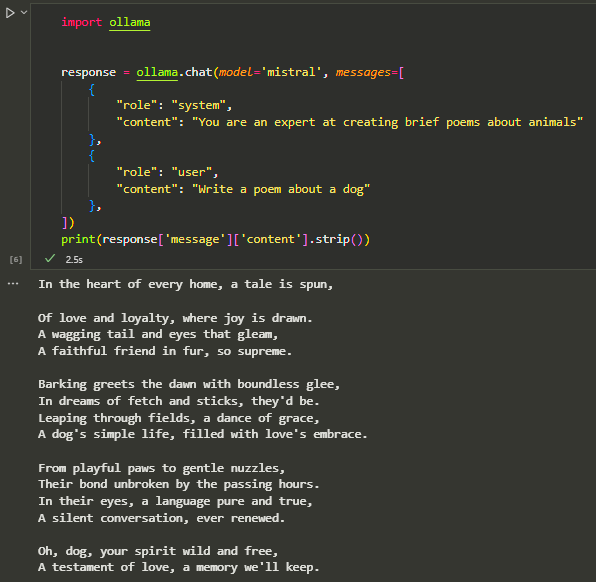
Conclusioni
Questo articolo ti ha mostrato come usare ollama come wrapper intorno a logiche più complesse per usare un LLM in locale.
Attraverso pochi comandi è possibile iniziare ad usare subito modelli di linguaggio naturale come Mistral, Llama2 e Gemma direttamente nel tuo progetto Python.
La semplicità di utilizzo permette anche a chi non è un data scientist di usare efficacemente gli LLM open source, che malgrado le loro limitazioni attuali, possono essere comunque usati per task di automazione semplici.
Ti è piaciuto il contenuto di questo articolo?
Supporta questo blog con una donazione




Commenti dalla community