
Tabella dei Contenuti
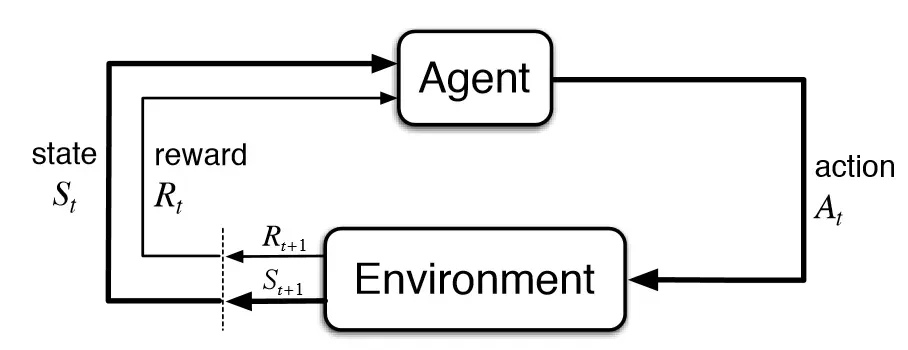
Il Reinforcement Learning (RL) è una branca del machine learning che si distingue dal tipo di apprendimento supervisionato e non. Infatti, con il termine reinforcement si vuole indicare un tipo di apprendimento basato sulla ricompensa capace di risolvere problemi decisionali in cui, attraverso un meccanismo di tentativi ed errori (trial and error), l'agente compie interazioni autonome con l’ambiente in cui opera.
A differenza degli approcci supervisionati o non supervisionati, il RL si basa su un processo di apprendimento iterativo, dove un agente impara attraverso un sistema di ricompense e punizioni.
Questa guida ha lo scopo di fornire una panoramica completa per iniziare da zero, accompagnandoti dalle basi teoriche agli strumenti pratici.
Esempio pratico: immaginiamo di dover addestrare (per la prima volta) il nostro amico a quattro zampe (di nome Red) e vogliamo che quest’ultimo resti fermo mentre noi ci allontaniamo pian piano da lui. Red riceverà un premio quando eseguirà il comando correttamente, ma verrà redarguito ogni qual volta proverà ad alzarsi senza il nostro permesso.

Questo processo di apprendimento è esattamente identico al nostro e a quello degli animali, ovvero attraverso le interazioni con l’ambiente comprendiamo come agire al fine di ottenere il risultato sperato.
Allo stesso modo il RL sfrutta un sistema di ricompense e punizioni come segnali postivi e negativi di comportamento. Il RL si distingue per il suo approccio basato sull'interazione, quindi l'obiettivo sarà quello di apprendere una policy, ossia una strategia ottimale al fine di massimizzare la ricompensa.
Concetti fondamentali
L’obiettivo del RL è quello di individuare un modello adatto che permetta di massimizzare la ricompensa massima totale ottenibile dall’agente.
Vediamo i termini chiave per comprendere i fondamentali del RL:
- Environment (Ambiente) — Spazio in cui l’agente opera
- State (Stato) — Stato in cui si trova l’agente
- Reward (Ricompensa) — Feedback positivo ottenuto dall’ambiente
- Policy (Strategia / Politica) — Definisce le azioni dell’agente
- Value (Valore) — Ricompensa futura che l’agente riceverà compiendo una particolare azione
L'ambiente rappresenta il contesto fisico o virtuale in cui l'agente opera, mentre lo stato descrive la condizione in cui l'agente si trova in un dato momento. Ogni azione compiuta dall'agente influisce sull'ambiente e viene valutata attraverso un sistema di ricompense.
La policy definisce le azioni da intraprendere in base allo stato attuale, mentre il valore rappresenta una stima delle ricompense future ottenibili eseguendo determinate azioni.
Questi elementi collaborano per orientare l'agente verso decisioni ottimali. Tuttavia, per identificare l'azione migliore da compiere, l'agente deve affrontare una sfida cruciale: esplorare nuovi stati e, al contempo, massimizzare la ricompensa attesa.
Esplorazione vs sfruttamento
Il compromesso tra esplorazione e sfruttamento (exploration vs exploitation) è uno dei concetti chiave nel Reinforcement Learning ed è cruciale per l'apprendimento di un agente.
L'esplorazione consiste nel permettere all'agente di provare azioni diverse, anche se non sono quelle ottimali, al fine di raccogliere nuove informazioni sull'ambiente. In altre parole, l'agente cerca di ampliare la propria conoscenza per scoprire potenzialmente azioni che possano portare a ricompense più elevate in futuro. L’esplorazione, pur comportando il rischio di non ottenere la massima ricompensa immediata, è essenziale per migliorare la strategia dell’agente nel lungo termine.
D'altro canto, lo sfruttamento implica l'utilizzo delle informazioni già acquisite per massimizzare la ricompensa in un dato momento. L’agente, in questa fase, tende a scegliere le azioni che hanno già portato ai migliori risultati in passato, riducendo i rischi di azioni inefficaci.
Il compromesso tra questi due aspetti sta nell'equilibrio che l'agente deve mantenere. Se l’agente esplora eccessivamente, rischia di non ottenere ricompense immediate, ma potrebbe scoprire strategie più efficaci utili in futuro. Se, invece, si concentra sullo sfruttamento tralasciando la fase di esplorazione, potrebbe perdere l’opportunità di imparare nuove strategie più redditizie.
Se il cane, come nel nostro esempio, sbaglia l'azione e riceve una correzione (un rimprovero), questo non significa che il processo di apprendimento sia negativo!
Ogni errore è un passo verso una maggiore comprensione di cosa comporta stare fermo al posto. Il "rimprovero" in questo caso diventa una parte del processo di apprendimento che porterà il cane a compiere l'azione corretta in futuro, una volta che avrà esplorato abbastanza l'ambiente e capito le giuste azioni da compiere.
Nel RL, questo è equivalente all'agente che raccoglie esperienze, anche se non sempre gratificanti nel breve termine, per ottimizzare le proprie scelte future e massimizzare la ricompensa complessiva.
Pertanto, una strategia ottimale di apprendimento deve integrare l'esplorazione e lo sfruttamento in modo dinamico, adattandosi all’evoluzione dell'ambiente e alle informazioni acquisite dall'agente.
Markov Decision Process
Un pilastro teorico del Reinforcement Learning è rappresentato dai Markov Decision Processes (MDP), che forniscono una base matematica per descrivere problemi in cui è necessario prendere decisioni sequenziali.
- Stati: rappresentano tutte le possibili situazioni in cui può trovarsi un agente all’interno di un ambiente. Ogni stato descrive le condizioni attuali dell’agente.
- Azioni: sono le scelte disponibili per l’agente in ogni stato. In ogni situazione, l’agente può scegliere fra diverse azioni che determinano la sua prossima mossa.
- Ricompense: per ogni azione intrapresa in un determinato stato, l’agente riceve un feedback, positivo o negativo, che rappresenta quanto quella scelta sia stata utile rispetto all’obiettivo. Questo feedback guida l’apprendimento dell’agente.
- Transizioni: rappresentano il legame tra gli stati. Quando l’agente esegue un’azione in uno stato, si sposta in un nuovo stato. La transizione descrive come e con quale probabilità questo passaggio avviene.
Questo framework consente di definire in modo chiaro i problemi che il Reinforcement Learning cerca di risolvere e fornisce una struttura utile per sviluppare algoritmi capaci di affrontarli. La maggior parte dei problemi di RL può essere modellata come un MDP, rendendolo uno strumento fondamentale per chi si avvicina a questa disciplina.
Compiti episodici e continui
Un concetto chiave negli MDP è quello di compito, ovvero l’obiettivo che l’agente deve raggiungere. I compiti si dividono in due categorie principali:
- Compiti episodici: questi compiti hanno un punto di inizio e uno di fine. L’agente svolge una sequenza di azioni che lo porta a completare un episodio, cioè una serie di passaggi che termina in uno stato finale. Un esempio è giocare una partita a scacchi, dove l’episodio termina quando uno dei due giocatori vince o la partita finisce in parità.
- Compiti continui: in questi compiti, il processo non ha una fine definita e l’agente deve interagire costantemente con l’ambiente senza raggiungere uno stato finale. Ad esempio, un sistema di controllo di un impianto industriale non ha un termine prestabilito ma deve ottimizzare continuamente il processo produttivo.
La distinzione tra compiti episodici e continui è importante perché influenza il modo in cui gli algoritmi di apprendimento sono progettati. Nei compiti episodici, si analizzano le ricompense al termine dell’episodio per migliorare le decisioni future. Nei compiti continui, invece, l’agente deve aggiornare continuamente la propria strategia per adattarsi in tempo reale all’ambiente.
Questa distinzione offre una base concettuale per comprendere i vari approcci all’apprendimento tramite rinforzo e aiuta a definire il tipo di problema che si sta affrontando.
Approcci per individuare la policy ottimale
In un MDP, l’obiettivo è identificare una policy ottimale, ovvero una strategia che massimizza la ricompensa cumulativa a lungo termine. Esistono due approcci principali per addestrare un agente a raggiungere questo scopo:
- Policy-Based Methods: questi metodi si concentrano direttamente sull'apprendimento della policy, ossia sull'identificazione della migliore azione da intraprendere in ogni stato. L’agente viene addestrato a mappare direttamente gli stati alle azioni, senza costruire una rappresentazione esplicita del valore degli stati. Questo approccio è particolarmente utile in problemi con spazi di azione continui.
- Value-Based Methods: in questi metodi, l'agente apprende il valore degli stati o delle azioni (attraverso una funzione di valore) e sceglie le azioni che massimizzano tali valori. L’obiettivo è stimare accuratamente quanto sia "buono" trovarsi in un determinato stato o eseguire una certa azione, in termini di ricompense future attese.
La scelta tra i due approcci dipende dalla natura del problema e dalle caratteristiche dell’ambiente.
Algoritmi e approcci più famosi
Q-Learning e SARSA sono due algoritmi fondamentali e ampiamente utilizzati nel Reinforcement Learning, entrambi progettati per apprendere una strategia ottimale che massimizzi le ricompense cumulative. Tuttavia, si differenziano per il modo in cui gestiscono l’esplorazione e l’apprendimento.
Q-Learning: Apprendimento Off-Policy
Il Q-Learning è un algoritmo off-policy, il che significa che l’aggiornamento dei valori Q non dipende direttamente dalle azioni intraprese dall’agente durante l’esplorazione. In altre parole, il Q-Learning assume che l’agente esegua sempre l’azione migliore possibile (ovvero quella con il valore più alto), anche se nella realtà può aver scelto diversamente.
Questo approccio consente all’algoritmo di concentrarsi maggiormente sullo sfruttamento di strategie ottimali a lungo termine, senza legarsi alla policy usata durante la fase di esplorazione. Grazie a questa caratteristica, il Q-Learning è particolarmente efficace nell’apprendere una strategia ottimale anche quando l’agente esplora l’ambiente con una policy che bilancia esplorazione e sfruttamento.
Il principale vantaggio del Q-Learning è quindi la sua capacità di apprendere una strategia ottimale, indipendentemente dalle azioni effettivamente intraprese durante l’esplorazione, rendendolo un algoritmo aggressivo e orientato ai risultati.
SARSA: Apprendimento On-Policy
A differenza del Q-Learning, SARSA è un algoritmo on-policy, il che significa che l’aggiornamento dei valori Q si basa sulle azioni effettivamente scelte dall’agente durante l’esplorazione. In questo caso, l’agente aggiorna i valori Q considerando sia lo stato corrente che l’azione che sceglierà successivamente, in base alla sua policy attuale.
Questo rende SARSA più "cauto" rispetto al Q-Learning, poiché tiene conto delle decisioni reali prese dall’agente, invece di fare ipotesi su un comportamento ottimale ideale. Questa caratteristica lo rende più adatto a contesti in cui l’esplorazione può comportare rischi, ad esempio in ambienti dinamici o poco conosciuti, dove scelte errate possono avere conseguenze negative.
Differenze Principali tra Q-Learning e SARSA
- Approccio all’apprendimento: Q-Learning apprende in modo indipendente dalla policy utilizzata durante l’esplorazione, mentre SARSA si basa direttamente sulle azioni intraprese dall’agente.
- Strategia di esplorazione: Q-Learning tende a essere più aggressivo e orientato verso il comportamento ottimale, mentre SARSA adotta un approccio più conservativo.
- Applicazione: Q-Learning è più adatto in ambienti statici e prevedibili, dove l’esplorazione non comporta rischi significativi. SARSA, invece, si comporta meglio in ambienti dinamici o incerti, dove è importante considerare i rischi associati all’esplorazione.
Nonostante siano estremamente utili e di facile applicazione, entrambi gli algoritmi hanno un limite comune: la difficoltà a generalizzare in stati non ancora visitati. In pratica, memorizzano i valori Q per ogni possibile combinazione di stato e azione, il che li rende poco efficienti in ambienti con spazi di stato molto grandi o continui. Questo problema emerge in contesti come il controllo di robot o i videogiochi complessi, dove il numero di possibili stati può essere estremamente elevato.
Per affrontare questi limiti, sono stati sviluppati algoritmi più avanzati. Ad esempio:
- Deep Q-Network (DQN): utilizza reti neurali per approssimare i valori Q, permettendo di gestire spazi di stato molto ampi e continui.
- SARSA Lambda: introduce un meccanismo di generalizzazione per migliorare l’efficienza.
- Actor-Critic: combina elementi di policy learning e apprendimento basato sui valori, aumentando la capacità di affrontare problemi complessi.
Grazie a questi avanzamenti, oggi è possibile applicare il Reinforcement Learning anche in scenari realistici e complessi, che superano le capacità dei metodi tradizionali. Nonostante ciò, Q-Learning e SARSA rimangono pilastri fondamentali del campo, fornendo le basi per comprendere e sviluppare algoritmi più sofisticati.
Deep Q-Network e Deep Deterministic Policy Gradient
Nel panorama del Reinforcement Learning, algoritmi come il Deep Q-Network (DQN) e il Deep Deterministic Policy Gradient (DDPG) hanno segnato una svolta, consentendo di superare molte limitazioni degli approcci tradizionali basati su Q-Learning o metodi policy-based, infatti, questi algoritmi integrano le capacità delle reti neurali per affrontare problemi complessi
Deep Q-Networks
Il DQN combina il Q-Learning con le reti neurali per stimare i Q-valori, che rappresentano il valore atteso di intraprendere una certa azione in uno stato specifico. Questo approccio si è dimostrato particolarmente efficace nei contesti in cui lo spazio degli stati è troppo grande per essere rappresentato esplicitamente. La rete neurale generalizza l'apprendimento, mappando gli stati alle azioni ottimali senza dover esplorare ogni combinazione possibile.
Un'innovazione chiave del DQN è l'uso di una rete target separata per stabilizzare l'addestramento. Inoltre, l'algoritmo implementa un processo chiamato replay esperienziale, che consiste nel memorizzare le esperienze passate (sotto forma di stati, azioni, ricompense e stati successivi) in un buffer e riutilizzarle per aggiornare i pesi della rete. Questo meccanismo riduce la correlazione tra i dati, migliorando la convergenza.
Deep Deterministic Policy Gradient
Il DDPG è progettato per ambienti con spazi di azione continui, dove il DQN non è facilmente applicabile. Si basa sui principi dell'Actor-Critic, in cui due reti neurali lavorano in tandem:
- Rete Actor: apprende direttamente la policy deterministica, mappando ogni stato a un'azione specifica.
- Rete Critic: stima il valore dell'azione suggerita dall'Actor utilizzando un approccio basato su Q-Learning.
Una caratteristica distintiva del DDPG è l'uso del rumore esplorativo, che aggiunge perturbazioni alle azioni per incoraggiare l'agente a esplorare nuove strategie. Questo è particolarmente utile in ambienti con dinamiche complesse e spazi d'azione ad alta dimensionalità.
Applicazioni degli algoritmi avanzati
Questi algoritmi rappresentano lo stato dell’arte del Reinforcement Learning e trovano applicazione in una vasta gamma di settori. Nel campo della robotica, ad esempio, il DDPG consente ai robot di apprendere movimenti precisi in ambienti tridimensionali, come afferrare oggetti o navigare in spazi affollati. Nel settore dei giochi, il DQN è stato utilizzato per superare i record umani in diversi videogiochi Atari, dimostrando la sua efficacia nella gestione di ambienti complessi e dinamici.
L'adozione di tali algoritmi consente non solo di affrontare problemi di alta complessità computazionale, ma anche di esplorare nuovi orizzonti in cui il Reinforcement Learning può avere un impatto determinante.
Esempio in Python
Vediamo adesso un'applicazione in Python sfruttando il pacchetto di OpenAI Gymnasium.

Una delle caratteristiche principali di Gymnasium è la disponibilità di un'ampia varietà di ambienti preconfigurati, ciascuno con un diverso livello di complessità e uno scopo specifico per allenare e testare algoritmi di reinforcement learning.
Tra questi, l’ambiente MountainCar è un classico problema introduttivo che permette di esplorare i concetti base del RL.
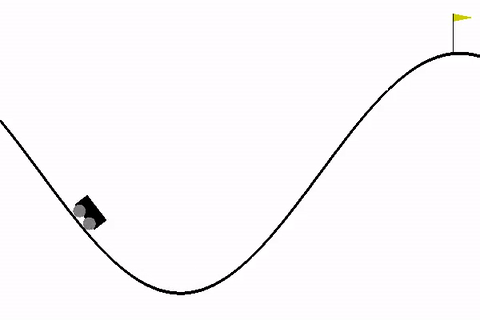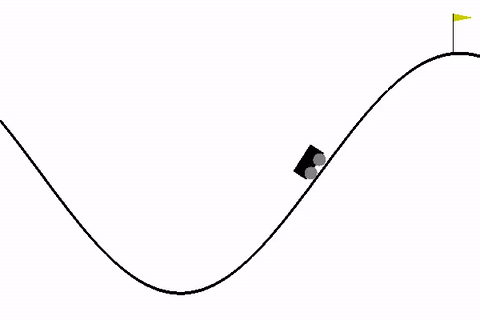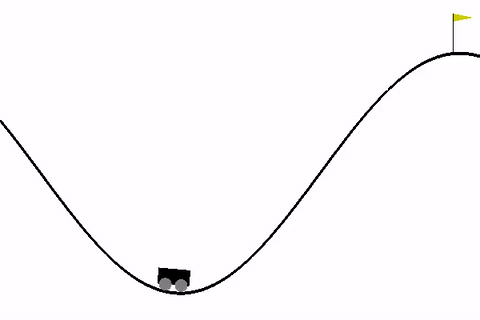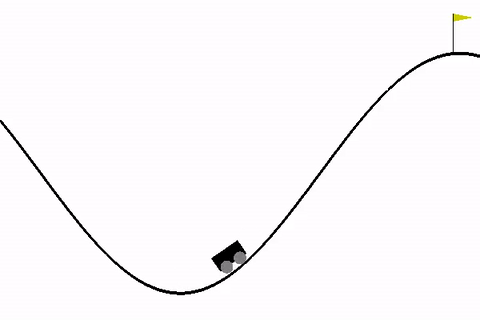
Quando si lavora con ambienti di reinforcement learning come MountainCar, è fondamentale capire la struttura degli spazi di osservazione e azione, che definiscono i possibili stati e le azioni che l'agente può intraprendere.
1. Spazio di osservazione (observation_space): Nel caso di MountainCar, l'ambiente restituisce un spazio di tipo Box. Questo tipo di spazio è utilizzato per rappresentare valori continui (come la posizione e la velocità dell'auto in MountainCar). La forma del Box per MountainCar è (2,), il che significa che l'osservazione è un vettore di due valori, uno per la posizione e uno per la velocità dell'auto.
- Posizione dell'auto: Il primo valore nell'array rappresenta la posizione dell'auto lungo la valle, che va da -1.2 (l'estremità sinistra) a 0.6 (l'estremità destra).
- Velocità dell'auto: Il secondo valore nell'array rappresenta la velocità dell'auto, che può essere compresa tra -0.07 e 0.07.
La funzione Box delimita questi valori con un limite inferiore e limite superiore, il che significa che qualsiasi osservazione restituita dal sistema sarà sempre un vettore che rientra in questi limiti. Ad esempio, una posizione di -1.2 e una velocità di 0.0 sono una combinazione valida per lo stato iniziale.
2. Spazio delle azioni (action_space): l'ambiente definisce un spazio di tipo Discrete(3), che significa che ci sono tre azioni possibili. Queste azioni sono discrete e corrispondono a:
- 0: Accelerare a sinistra.
- 1: Non accelerare (restare fermi).
- 2: Accelerare a destra.
In MountainCar, l'agente deve scegliere tra queste tre azioni per cercare di far salire l'auto sulla montagna. Non esistono altre azioni o combinazioni, il che rende l'azione un insieme discreto di scelte finite.
import time
# Number of steps you run the agent for
num_steps = 1500
obs = env.reset()
for step in range(num_steps):
# take random action, but you can also do something more intelligent
# action = my_intelligent_agent_fn(obs)
action = env.action_space.sample()
# apply the action
obs, reward, done, info = env.step(action)
# Render the env
env.render()
# Wait a bit before the next frame unless you want to see a crazy fast video
time.sleep(0.001)
# If the epsiode is up, then start another one
if done:
env.reset()
# Close the env
env.close()
type(env.observation_space)
#OUTPUT -> gym.spaces.box.Box
print("Upper Bound for Env Observation", env.observation_space.high)
print("Lower Bound for Env Observation", env.observation_space.low)
OUTPUT:
Upper Bound for Env Observation [0.6 0.07]
Lower Bound for Env Observation [-1.2 -0.07]Il primo passo nel codice è la creazione e l'inizializzazione dell'ambiente, che rappresenta il mondo in cui l'agente si troverà ad agire. In questo caso, l'ambiente è MountainCar, dove l'auto deve essere spinta da una valle fino alla cima di una montagna. L'ambiente viene ripristinato (reset), riportandolo allo stato iniziale in cui l'auto è posizionata tra due montagne. Subito dopo il reset, l'ambiente viene chiuso, ma questo passaggio potrebbe essere usato solo per liberare risorse in un contesto più grande, come nel caso di simulazioni più complesse.
L'ambiente ha una "spazio di osservazione" che descrive cosa l'agente può percepire. Nel caso di MountainCar, l'agente può osservare la posizione dell'auto e la velocità dell'auto. Ogni volta che l'agente esamina l'ambiente, ottiene un aggiornamento su questi valori. Questi valori sono limitati, quindi l'ambiente ha un "limite superiore" e un "limite inferiore" per ciascuna di queste due variabili, ovvero la posizione e la velocità. Per esempio, la posizione può variare da -1.2 (molto a sinistra nella valle) a 0.6 (dove l'auto può iniziare a salire sulla montagna), e la velocità è limitata tra -0.07 e 0.07.
Una volta che l'ambiente è stato inizializzato e l'agente ha accesso alle informazioni, si entra in un ciclo continuo di interazione con l'ambiente. L'agente deve compiere delle azioni per esplorare l'ambiente. Ogni "passo" del ciclo rappresenta una singola iterazione in cui l'agente:
- Sceglie un'azione: In questo caso, l'agente non prende decisioni basate su una strategia intelligente, ma sceglie un'azione a caso, come accelerare a sinistra, non fare nulla o accelerare a destra. L'idea è di testare l'ambiente in modo casuale per raccogliere dati su come l'auto si comporta in diverse situazioni.
- Applica l'azione: Dopo aver scelto l'azione, l'agente applica questa scelta all'ambiente. Ad esempio, se l'azione scelta è "accelerare a destra", l'auto si sposterà verso destra.
- Osserva il risultato: Ogni volta che l'agente compie un'azione, l'ambiente restituisce un nuovo stato, che include la nuova posizione e la velocità dell'auto, e una "ricompensa", che indica quanto l'azione sia stata utile nel raggiungere l'obiettivo (salire sulla montagna).
- Renderizza l'ambiente: Dopo aver applicato l'azione, l'ambiente viene "renderizzato", cioè visualizzato, per mostrare cosa sta succedendo. L'agente può vedere l'auto muoversi e cercare di salire sulla montagna.
- Aspetta un breve periodo: Per non far andare troppo veloce la simulazione (in modo che l'utente possa seguire l'andamento), il codice introduce un piccolo ritardo tra i vari passi.
- Controlla se l'episodio è finito: Se l'auto raggiunge la cima della montagna o se l'episodio è terminato per qualche altro motivo, l'ambiente viene ripristinato e un nuovo episodio inizia.
Il ciclo continua per un numero predeterminato di passi (1500 in questo caso). Ogni episodio inizia con l'auto posizionata nella valle e termina quando l'auto raggiunge l'obiettivo (salire sulla montagna) o dopo che il numero di passi è stato esaurito. Quando un episodio termina, l'ambiente viene resettato e il ciclo ricomincia.
L'agente, agendo casualmente, esplora l'ambiente MountainCar. Inizialmente, l'agente non sa come raggiungere l'obiettivo e compie azioni a caso. Tuttavia, questa esplorazione casuale è fondamentale perché consente all'agente di raccogliere dati che saranno utilizzati successivamente per migliorare le sue decisioni, eventualmente applicando algoritmi di reinforcement learning più avanzati che ottimizzano le azioni in base alle esperienze precedenti.
In sostanza, questo ciclo rappresenta il comportamento di un agente che esplora un ambiente in modo iterativo, raccogliendo esperienze per migliorare progressivamente le sue azioni, un passo essenziale per sviluppare un agente di reinforcement learning che possa risolvere efficacemente il problema di MountainCar.
Grokking Deep Reinforcement Learning
Miguel Morales
Questo libro combina codice Python annotato con spiegazioni intuitive per esplorare le tecniche di deep RL. Vedrai come funzionano gli algoritmi e imparerai a sviluppare i tuoi agenti DRL usando feedback valutativi.

Conclusione
Riassumendo,
- Reinforcement Learning basa tutto sulla massimizzazione cumulate della ricompensa
- Al fine di ottimizzare la policy abbiamo due opzioni: Policy based methods che ottimizza direttamente la policy e Value based methods che agisce indirettamente per ottimizzare la policy
- Termini chiave del RL sono agente, stati, azioni e recompense
Il Reinforcement Learning rappresenta uno degli approcci più affascinanti e potenti nell'ambito dell'intelligenza artificiale. Con le sue applicazioni che spaziano dai videogiochi alla robotica, fino all'ottimizzazione di sistemi complessi, offre un'opportunità unica per risolvere problemi dove l'apprendimento autonomo e l'adattamento sono elementi cruciali.
In questa guida, abbiamo introdotto i concetti chiave, gli algoritmi principali e le tecniche di base che ti permetteranno di muovere i primi passi nel mondo del Reinforcement Learning.
Il Reinforcement Learning è un campo in continua evoluzione, e la tua curiosità è il miglior alleato per esplorare nuove frontiere. Continua a sperimentare, metti alla prova le tue conoscenze e non smettere mai di imparare.





Commenti dalla community