
Tensorflow è il framework creato da Google che permette ai praticanti di machine learning di creare modelli di deep learning ed è spesso la prima soluzione che viene proposta agli analisti che si approcciano per la prima volta al deep learning.
Il motivo è da ricercarsi nella semplicità e intuitività dell'API sequenziale di Tensorflow. Questa è molto semplice ma permette all'analista di creare reti neurali molto complesse e potenti.
API significa Application Programming Interface (interfaccia di programmazione dell'applicazione) e rappresenta proprio l'interfaccia tra l'utente e l'applicativo che vogliamo usare.
L'interfaccia di Tensorflow è semplice, diretta e facilmente comprensibile anche da chi non ha mai fatto deep learning pratico, ma che conosce solo la teoria.
L'API sequenziale di Tensorflow è molto beginner-friendly e quindi si presta molto bene ad essere insegnata come introduzione al deep learning.
In questo articolo propongo una introduzione al deep learning proprio che sfrutta l'API sequenziale, mostrando esempi e codice in modo da aiutare il lettore nella comprensione di questi concetti.
Intuizione alla base del deep learning e delle reti neurali
Prima di vedere come funziona Tensorflow e il suo modello sequenziale, è necessario avere un minimo di background su cosa sia il deep learning e come funzionano le reti neurali.
Le reti neurali sono lo strumento principale del deep learning. L'apprendimento di un fenomeno avviene attraverso l'attivazione e disattivazione dei neuroni presenti all'interno di una rete, che riescono a rappresentare il problema che vogliamo risolvere attraverso pesi e bias.
Tra ogni strato neuronale c'è una funzione di attivazione. Questa va a trasformare l'output di uno strato verso il prossimo, con diverse conseguenze sulla abilità della rete a generalizzare il problema. La più comune delle funzioni di attivazione è chiamata ReLU.
Ogni neurone è caratterizzato da pesi e bias. Attraverso gli algoritmi di gradient descent e backpropagation una rete neurale è in grado di modificare e aggiornare la combinazione di pesi e bias in maniera iterativa in modo da avvicinarsi sempre di più alla funzione reale che descrive il fenomeno nella realtà.
Una rete neurale è in grado di comprendere se sta migliorando o meno le sue performance andando a confrontare quanto le sue predizioni siano vicine ai valori reali. Questo comportamento è descritto da una loss function (funzione di perdita). Come praticanti di machine learning, vogliamo sempre andare a minimizzare la loss.
Il nostro obiettivo come analisti è quello di ridurre quanto più possibile la loss, evitando al contempo l'overfitting.
Non andrò nel dettaglio in questo pezzo anche perché ho parlato di questo argomento nell'articolo Introduzione alle reti neurali - pesi, bias e attivazione. Consiglio al lettore che vuole espandere la sua intuizione delle basi del deep learning di leggere questo articolo.
Questa piccola intuizione però sarà sufficiente per aiutare nella comprensione della sezione che segue.
Cosa è e come funziona l'API sequenziale di Tensorflow?
Tensorflow mette a disposizione una miriade di funzionalità grazie a Keras. Le API di TensorFlow si basano su quelle di Keras per la definizione e l'addestramento delle reti neurali.
Il modello sequenziale ci permette di specificare una rete neurale, per l'appunto, sequenziale: da input ad output, passando per una serie di strati neurali, uno dopo l'altro.
Tensorflow permette di usare anche l'API funzionale per la creazione di modelli di deep learning. È un approccio usato da utenti esperti e non è user-friendly quanto l'API sequenziale. La differenza fondamentale sta nel fatto che l'API funzionale permette di creare reti neurali non sequenziali (quindi multi-output e con integrazioni ad altri componenti).
In Python, è implementabile così
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential(
[...]
)
keras.Sequential accetta una lista che contiene l'architettura della rete neurale. Ogni strato viene inserito nella lista, e il dato fluisce in maniera sequenziale attraverso ognuno di essi finché non diventa output.
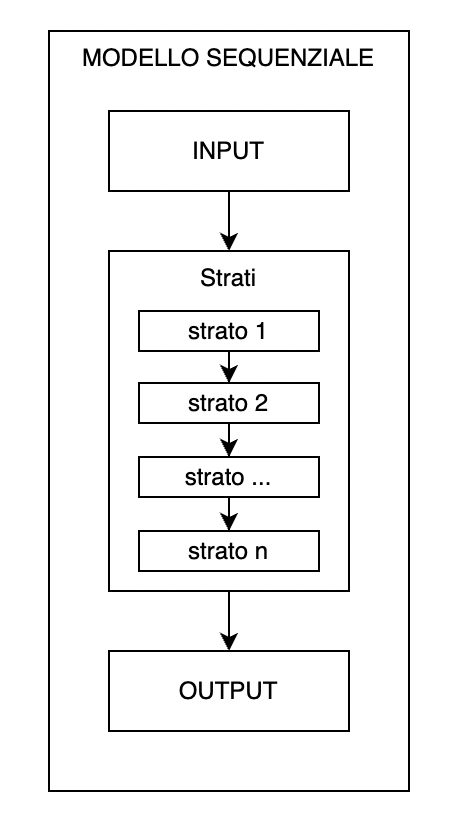
Possiamo specificare degli strati neurali attraverso keras.layers.
Lo strato di input
Il primo strato da inserire in una rete neurale è quello di input. Attraverso keras è molto semplice.
Creiamo uno strato di 256 neuroni, con attivazione relu e una dimensione di 4.
# strato input
layers.Dense(256, input_dim=4, activation="relu", name="input")
Questo strato sarà diverso dagli altri, poiché gli altri non necessitano di specificare l'argomento input_dim.
Uno dei problemi più comuni nei principianti del deep learning è quello di comprendere quale sia la shape dell'input.
Trovare il valore di input_dim non è banale, e dipende molto dai dati che abbiamo. Poiché nel deep learning ragioniamo in tensori (strutture che contengono dati multidimensionali), a volte diventa difficile intuire quale sia la forma dei nostri dati da fornire alla rete neurale.
In un dataset tabellare, la nostra input shape sarà uguale al numero di colonne del dataset. Con Pandas e Numpy basta usare .shape[-1] sull'oggetto per ottenere questa informazione.
Nel caso di immagini invece, saremmo costretti a passare il numero di pixel totale dell'immagine. Nel caso di una immagine 28 * 28, l'input dimension sarà 784.
Discorso ancora diverso per le serie temporali, dove bisogna passare la dimensione del dataset, la lunghezza della finestra temporale e la dimensione del dataset contenuta in essa.
Ponendo che il nostro dataset sia tabellare e che abbia 4 colonne, ci basterà specificare 4 come input dimension.
Per quanto riguarda il numero di neuroni, il valore di 256 è arbitrario. Bisogna sperimentare con questi parametri e valutare qual è l'architettura più performante.
Gli strati successivi all'input
Andiamo ad aggiungere degli strati al nostro modello sequenziale.
model = keras.Sequential(
[
layers.Dense(256, input_dim=4, activation="relu", name="input")
layers.Dense(128, activation="relu", name="strato1"),
layers.Dense(64, activation="relu", name="strato2"),
# ...
]
)
Gli strati dopo il primo non richiedono di specificare la input dimension, poiché dopo lo strato di input sarà la rappresentazione dell'input in termini di pesi e bias a passare da uno strato all'altro.
Lo strato di output
Lo strato di output si differenzia dagli altri strati in quanto deve rispecchiare il numero di valori che vogliamo ricevere in output dalla rete neurale.
Se per esempio vogliamo fare una regressione, e quindi predire un singolo numero, il numero di unità nello strato finali dovrà essere uno.
# strato output
layers.Dense(1, name="output")
In questo caso, non va nemmeno specificata la funzione di attivazione, poiché senza di essa si ha una rappresentazione lineare (non influenzata dalla ReLU ad esempio) della rete neurale.
Se invece volessimo predire delle categorie, ad esempio differenziare tra cani e gatti in una immagine, avremmo bisogno di una funzione di attivazione nell'ultimo strato che si chiama softmax. Softmax mappa la rappresentazione della rete neurale alle classi presenti nel nostro dataset, assegnando una probabilità alla predizione di ciascuna classe.
Per l'esempio menzionato, il nostro strato di output sarebbe
# strato output
layers.Dense(2, activation="softmax", name="output")
Il risultato sarebbe simile a [[ 0.98, 0.02]] , dove il primo numero indica il livello di confidenza della rete neurale a predire la classe 1, che potrebbe essere cane o gatto.
Stampare un sommario del modello
Mettiamo insieme i pezzi di codice visti finora., aggiungiamo un nome al modello e stampiamo un riassunto della nostra architettura con .summary().
model = keras.Sequential(
layers=[
layers.Dense(256, input_dim=4, activation="relu", name="input"),
layers.Dense(128, activation="relu", name="strato1"),
layers.Dense(64, activation="relu", name="strato2"),
layers.Dense(2, activation="softmax", name="output")
],
name="modello_sequenziale1"
)
model.summary()
Osserviamo il risultato
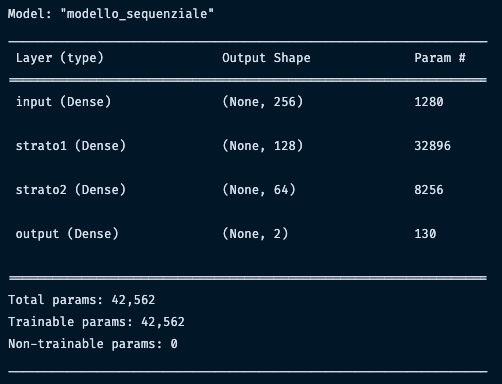
Questo sommario mostra informazioni molto importanti per comprendere l'architettura della nostra rete neurale e come il dato si muove tra gli strati.
La colonna più importante è Output Shape. Nel caso di un esempio così semplice può non sembrare rilevante, ma questa colonna mostra come il nostro dato cambia forma nei vari strati della rete neurale.
Il sommario diventa specialmente utile quando usiamo le reti neurali convoluzionali oppure LSTM. Questo perché la forma del dato cambia in modi non facilmente intuibili. In caso di errori, queste informazioni ci possono aiutare a debuggare il codice.
La colonna Param # indica il numero di parametri che possono essere modificati dalla rete neurale. In termini matematici, è il numero di dimensioni del nostro problema di ottimizzazione. Ricordiamo che ogni neurone ha un parametro di peso e uno di bias e quindi n_parametri = n_neuroni * ( n_input + 1).
Nel primo strato output e input sono uguali, quindi sarebbe 256 x 5.
Aggiungere strati in maniera incrementale
C'è anche un metodo alternativo, puramente basato sullo stile e quindi arbitrario, di aggiungere strati ad un modello sequenziale.
In maniera incrementale, è possibile usare model.add() per aggiungere un oggetto.
model = keras.Sequential()
model.add(layers.Dense(256, input_dim=4, activation="relu", name="input"))
model.add(layers.Dense(128, activation="relu", name="strato1"))
model.add(layers.Dense(64, activation="relu", name="strato2"))
model.add(layers.Dense(2, activation="softmax", name="output"))
Il risultato finale è uguale a quello visto precedentemente attraverso la lista layers, quindi si può usare l'approccio che si preferisce.
Compilare il modello sequenziale completo
Andiamo ora a compilare il modello - un processo necessario per l'addestramento della rete neurale.
Compilare significa andare a settare un una funzione di perdita, un ottimizzatore e le metriche di valutazione delle performance.
Una volta stabilita la architettura della rete, compilare richiede solo un piccolo pezzo di codice. Portando avanti l'esempio della classificazione tra cani e gatti, useremo come loss function la cross-entropia categoriale, Adam come ottimizzatore e la accuratezza come metrica di valutazione.
Per leggere di più su questi parametri, vi invito a leggere l'articolo sulla classificazione binaria di immagini fatta in Tensorflow.
model.compile(
loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"]
)
Addestrare il modello sequenziale
Per addestrare il modello sequenziale basta usare model.fit() dopo averlo compilato. Basta passare X e y, dove X è il nostro feature set e y è la nostra variabile target.
Ci sono anche altri parametri passabili in .fit(). Ecco alcuni dei più importanti:
batch_size: permette di stabilire il numero di esempi da valutare ad ogni iterazione di addestramento prima di aggiornare i pesi e i bias del modelloepochs: stabilisce il numero di volte che il modello processa tutto il dataset. Una epoca è superata quando tutti gli esempi nel dataset sono stati sfruttati per aggiornare i pesi del modellovalidation_data: qui passiamo il set di dati di test su cui fare la valutazione dell'addestramento.
model = keras.Sequential(
layers=[
layers.Dense(256, input_dim=4, activation="relu", name="input"),
layers.Dense(128, activation="relu", name="strato1"),
layers.Dense(64, activation="relu", name="strato2"),
layers.Dense(2, activation="softmax", name="output")
],
name="modello_sequenziale1"
)
model.compile(
loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, batch_size=32, epochs=200, validation_data=(X_test, y_test),)
da qui parte il processo di addestramento che mostrerà in terminale il progresso con loss e metrica di performance.
Ho scritto un articolo sull'Early Stopping con Tensorflow, una callback in grado di aiutare una rete neurale a migliorare le sue performance in training.
Valutazione del modello sequenziale
Il lettore attento avrà notato una particolarità nello snippet di codice appena visto. Mi riferisco a history = model.fit(...). Come mai bisogna assegnare una operazione di addestramento ad una variabile? Perché model.fit(...) restituisce un oggetto che contiene le performance di training.
In Tensorflow, usare .fit() restituisce un oggetto con le performance di training del modello. Questo oggetto è usabile per visualizzare queste performance e per analizzarle in dettaglio.Possiamo accedere ai valori nel dizionario esplorando l'attributo history all'interno della variabile.
Usando questi dati possiamo visualizzare le performance di addestramento sul set di training e validazione.
def plot_model(metric):
plt.plot(history.history[metric])
plt.plot(history.history[f"val_{metric}"])
plt.title(f"model {metric}")
plt.ylabel(f"{metric}")
plt.xlabel("epoch")
plt.legend(["train", "validation"], loc="upper left")
plt.show()
plot_model("loss");
plot_model("accuracy");
Guardiamo la loss
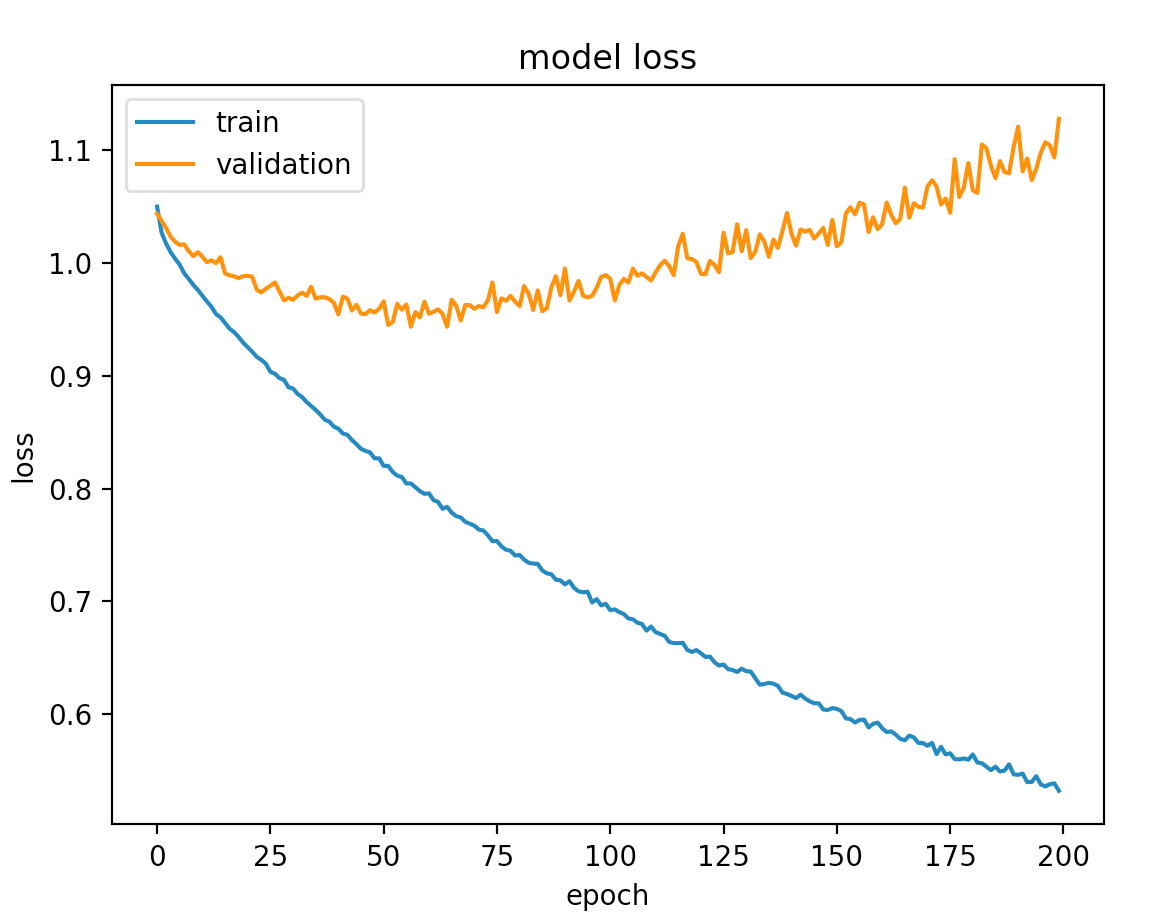
E stesso discorso per la metrica di valutazione scelta, in questo caso la accuratezza
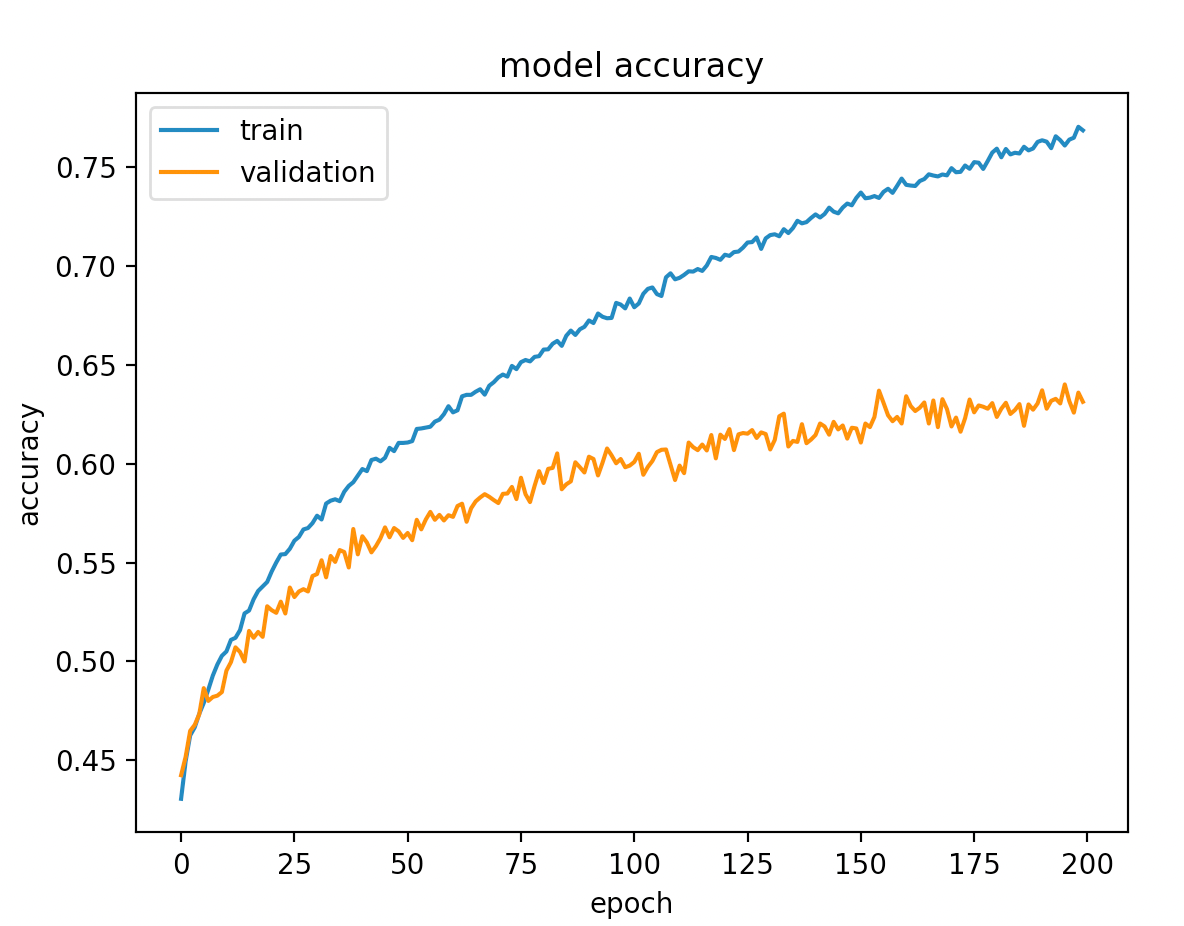
Nel caso in cui avessimo un set di validazione e test, è possibile valutare il modello usando model.evaluate(X_test, y_test).
Fare predizioni con il modello sequenziale
Una volta addestrato, è tempo di usare il modello per fare predizioni. Questa operazione si fa con
train_predictions = model.predict(X_train)
In questo caso, l'API è simile a quella di Sklearn e le predizioni della rete neurali sono assegnate a train_predictions.
Salvare e caricare un modello Tensorflow
L'ultimo step è tipicamente quello di salvare il modello che abbiamo addestrato. L'API di Tensorflow permette di farlo semplicemente con
model.save("posizione\su\disco")
Verrà creata una cartella alla posizione su disco specificata che conterrà la nostra rete neurale.
Per caricare il modello in un momento successivo, basta fare
model = keras.models.load_model("posizione\su\disco")
Da qui è possibile usare il modello per fare predizioni come abbiamo visto poco fa.
Quando NON usare un modello sequenziale?
Come già menzionato, Tensorflow permette di creare reti neurali non sequenziali attraverso l'utilizzo dell'API funzionale.
In particolare, vale la pena considerare l'approccio funzionale quando:
- abbiamo bisogno di più output, quindi una rete neurale multi-output
- uno strato richiede più input dagli strati precedenti
- bisogna far comunicare due reti neurali tra di loro
- abbiamo bisogno di una rete neurale custom, con una architettura non usuale
In tutti questi, e forse altri, richiediamo una rete non sequenziale. L'approccio sequenziale è generalmente molto flessibile in quanto permette di risolvere parecchi problemi, come la classificazione binaria di immagini, ma per problemi più complessi una rete del genere potrebbe non fare a caso nostro.
Conclusioni
L'API e modello sequenziale di Tensorflow sono degli strumenti potenti e semplici da usare per il praticante di deep learning.
Questa guida vuole mettere il principiante di deep learning in condizione di poter sperimentare con tali strumenti nei suoi progetti personali, evitando di sentirsi perso e ricorrere alla documentazione ufficiale.
Spero di aver contribuito alla vostra formazione. Alla prossima!





Commenti dalla community