
In questo post vedremo come implementare un modello di regressione logistica usando PyTorch in Python.
PyTorch è uno dei framework di deep learning più famosi e usati dalla community di data scientist e ingegneri del machine learning al mondo, e imparare questo strumento diventa fondamentale se si vuole costruire una carriera nel campo della IA applicata.
Esso si affianca a TensorFlow, un altro framework di deep learning molto famoso sviluppato da Google.
Non ci sono differenze fondamentali notevoli, tranne per la struttura e organizzazione delle loro API, che possono risultare molto diverse.
Mentre entrambi i framework permettono di creare reti neurali molto complesse, PyTorch è generalmente preferito grazie al suo stile più Pythonesco e alla libertà che lascia allo sviluppatore di integrare logiche custom nel software.
Useremo il breast cancer dataset di sklearn, dataset open source e già usato precedentemente in alcuni degli articoli presenti in questo blog per addestrare un modello di classificazione binaria.
L'obiettivo è quello di spiegare come:
- passare da Pandas per l'organizzazione del dataset ai
DataseteDataLoaderdi PyTorch - creare una rete neurale per la classificazione binaria in PyTorch
- creare predizioni
- valutare le performance del nostro modello con delle funzioni di utilità e matplotlib
- usare tale rete per fare delle predizioni
Per la fine di questo articolo avremo una idea chiara di come creare una rete neurale in PyTorch e di come il loop di addestramento funzioni.
Installare PyTorch e le altre dipendenze
Iniziamo il nostro progetto andando a creare un ambiente virtuale in una cartella dedicata.
Visita questo link per imparare come creare un ambiente virtuale con Conda.
Una volta creato il nostro ambiente virtuale, scriviamo nel terminale pip install torch -U. Questo comando installerà l'ultima versione di PyTorch, che alla data di scrittura di questo articolo è la versione 2.0.
Avviando un notebook, possiamo verificare la versione della libreria usando torch.__version__ dopo aver fatto import torch.
Possiamo verificare che PyTorch sia installato correttamente nell'ambiente andando a importare e lanciare un piccolo script di test, come mostrato nella guida ufficiale.
import torch
x = torch.rand(5, 3)
print(x)
>>> tensor([[0.3890, 0.6087, 0.2300],
[0.1866, 0.4871, 0.9468],
[0.2254, 0.7217, 0.4173],
[0.1243, 0.1482, 0.6797],
[0.2430, 0.4608, 0.8886]])Se lo script viene eseguito correttamente allora siamo pronti a procedere con il progetto. In caso contrario suggerisco al lettore di riferirsi alla guida ufficiale che si trova qui https://pytorch.org/get-started/locally/.
Continuiamo con l'installazione delle dipendenze aggiuntive:
- Sklearn;
pip install scikit-learn - Pandas;
pip install pandas - Matplotlib;
pip install matplotlib
Librerie come Numpy sono automaticamente installare quando si installa PyTorch.
Importare ed esplorare il dataset
Iniziamo importando le librerie installate e il breast cancer dataset da Sklearn con il seguente snippet di codice
import torch
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
breast_cancer_dataset = load_breast_cancer(as_frame=True, return_X_y=True)Creiamo un dataframe dedicato a contenere le nostre X e y in questo modo
df = breast_cancer_dataset[0]
df['target'] = breast_cancer_dataset[1]
df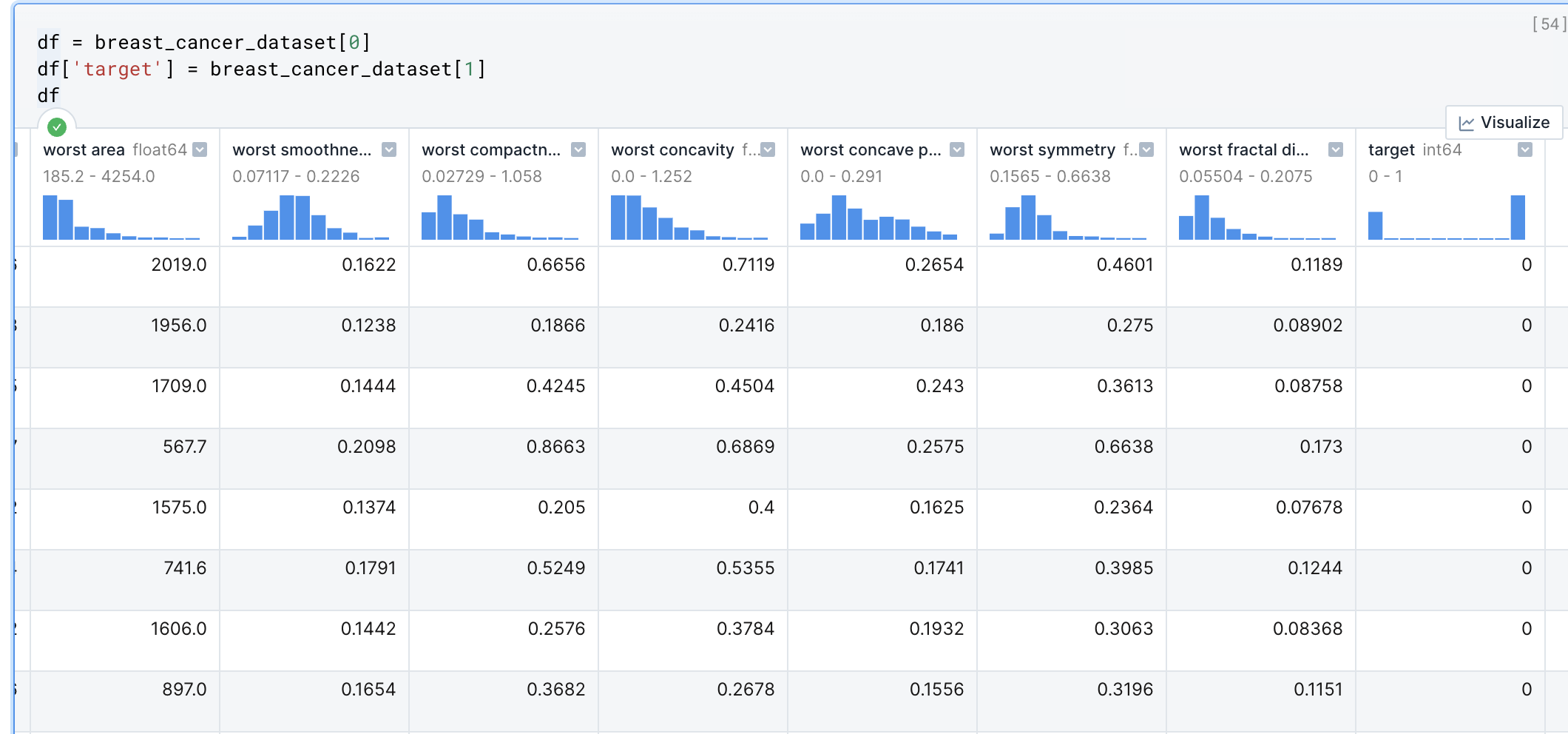
Il nostro obiettivo è quello di creare un modello in grado di prevedere la colonna target in base alle caratteristiche presenti nelle nelle altre colonne.
Andiamo a fare un minimo di analisi esplorativa per avere po' di consapevolezza del dataset. Useremo la libreria sweetviz per creare automaticamente un report di analisi.
Installiamo sweetviz con il comando pip install sweetviz e creiamo un report di EDA (exploratory data analysis) con questo snippet
import sweetviz as sv
eda_report = sv.analyze(df)
eda_report.show_notebook()
Sweetviz creerà un report direttamente nel nostro notebook da poter esplorare.
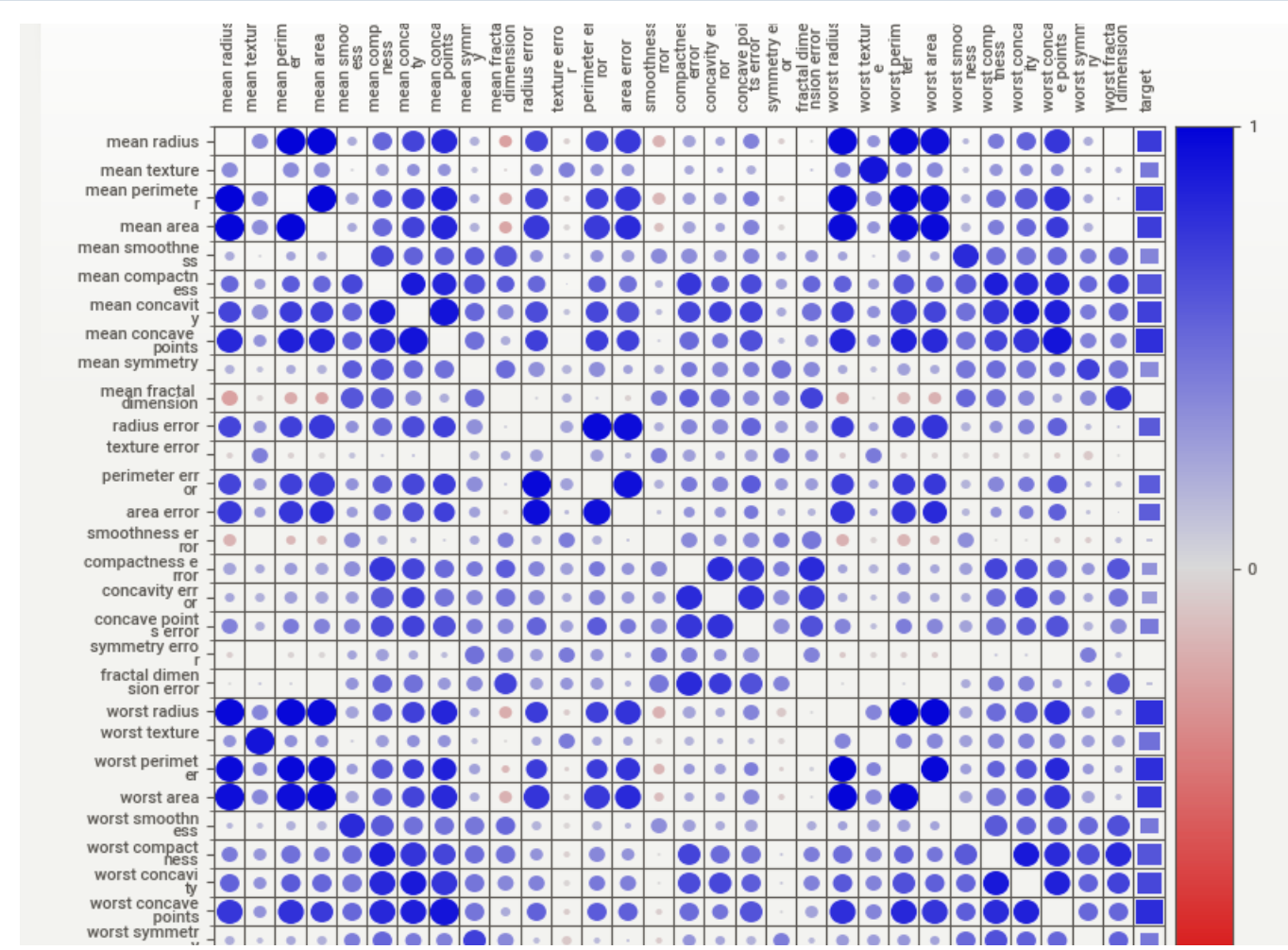
Vediamo come diverse colonne siano altamente associate con un valore di 0 o 1 della nostra colonna target.
Essendo un dataset multidimensionale avendo variabili con distribuzioni diverse, una rete neurale è una valida opzione per creare un modello predittivo. Detto ciò, questo dataset può essere modellato anche da modelli più semplici, come gli alberi decisionali.
Importiamo altre due librerie per poter mettere su grafico il dataset. Useremo la PCA (Principal Component Analysis) da Sklearn e Seaborn per visualizzare il dataset multidimensionale.
La PCA ci aiuterà a comprimere il grosso numero di variabili in solamente due, che useremo come asse X e Y in uno scatterplot di Seaborn. Seaborn accetta un ulteriore parametro chiamato hue per colorare i punti in base ad una variabile aggiuntiva. Useremo il nostro target.
import seaborn as sns
from sklearn import decomposition
pca = decomposition.PCA(n_components=2)
X = df.drop("target", axis=1).values
y = df['target'].values
vecs = pca.fit_transform(X)
x0 = vecs[:, 0]
x1 = vecs[:, 1]
sns.set_style("whitegrid")
sns.scatterplot(x=x0, y=x1, hue=y)
plt.title("Proiezione PCA")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.xticks([])
plt.yticks([])
plt.show()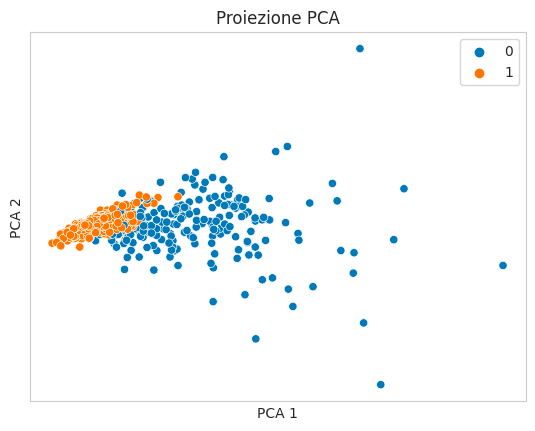
Vediamo come i record che hanno come target 1 si raggruppino in base a delle caratteristiche comuni. Sarà obiettivo della nostra rete neurale differenziare in maniera matematica le righe con target 0 o 1.
Creare dataset e dataloader
PyTorch mette a disposizione gli oggetti Dataset e DataLoader per permetterci di organizzare e caricare efficientemente i nostri dati nella rete neurale.
Sarebbe possibile usare direttamente Pandas, ma questo avrebbe degli svantaggi perché rendere il nostro codice meno efficiente.
La classe Dataset permette di specificare il formato giusto per i nostri dati e applicare le logiche di reperimento e trasformazione che sono spesso fondamentali (si pensi alla data augmentation applicata alle immagini).
Vediamo come creare un oggetto Dataset di PyTorch.
from torch.utils.data import Dataset
class BreastCancerDataset(Dataset):
def __init__(self, X, y):
# creiamo tensori per le feature
self.features = torch.tensor(X, dtype=torch.float32)
# creiamo tensori per le etichette
self.labels = torch.tensor(y, dtype=torch.float32)
def __len__(self):
# definiamo un metodo per recuperare la lunghezza del dataset
return self.features.shape[0]
def __getitem__(self, idx):
# override necessario del metodo __getitem__ che aiuta a indicizzare i nostri dati
x = self.features[idx]
y = self.labels[idx]
return x, yQuesto è una classe che eredita da Dataset e che permette al Dataloader, che creeremo a breve, di recuperare efficacemente batch di dati.
La classe accetta X e y come input.
Dataset di addestramento, validazione e test
Prima di procedere negli step seguenti, è importante creare dei set di training, validation e test.
Questi ci aiuteranno a valutare le performance del nostro modello e a capire la qualità delle predizioni.
Per il lettore interessato suggerisco di leggere l'articolo 6 linee guida per addestrare correttamente il tuo modello e cosa è la cross-validazione nel machine learning per comprendere meglio perché dividere i nostri dati in tre partizioni sia una metodica efficace per la valutazione delle prestazioni.
Con Sklearn questo diventa semplice con il metodo train_test_split
from sklearn import model_selection
train_ratio = 0.50
validation_ratio = 0.20
test_ratio = 0.20
x_train, x_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=1 - train_ratio)
x_val, x_test, y_val, y_test = model_selection.train_test_split(x_test, y_test, test_size=test_ratio/(test_ratio + validation_ratio))
print(x_train.shape, x_val.shape, x_test.shape)
>>> (284, 30) (142, 30) (143, 30)Con questo piccolo snippet di codice abbiamo creato i nostri set di training, validazione e test secondo degli split controllabili.
Machine Learning with PyTorch and Scikit-Learn: Develop machine learning and deep learning models with Python
Sebastian Raschka, Yuxi (Hayden) Liu, Vahid Mirjalili
Machine Learning with PyTorch and Scikit-Learn è una guida completa al machine learning e al deep learning con PyTorch. Funge sia da tutorial passo dopo passo sia da riferimento a cui tornerai mentre costruisci i tuoi sistemi di machine learning.

Normalizzazione dei dati
Quando si fa deep learning, anche per un task semplice come la classificazione binaria, è sempre necessario normalizzare i nostri dati.
Normalizzare significa portare tutti i valori delle varie colonne presenti nel dataset sulla stessa scala numerica. Questo aiuta la rete neurale a convergere più efficacemente e quindi fare predizioni accurate più velocemente.
Useremo lo StandardScaler di Sklearn.
from sklearn import preprocessing
scaler = preprocessing.StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_val_scaled = scaler.transform(x_val)
x_test_scaled = scaler.transform(x_test)Notiamo come fit_transform sia applicato solo al training set, mentre transform sia applicato agli altri due dataset. Questo serve ad evitare il fenomeno del data leakage - quando informazioni del nostro di validazione o di test sono trasferiti involontariamente nel nostro set di training. Vogliamo che il nostro set di addestramento sia l'unica fonte di apprendimento, senza influenze da dati di test.
Questi dati ora sono pronti per essere forniti in input alla classe BreastCancerDataset.
train_dataset = BreastCancerDataset(x_train_scaled, y_train)
val_dataset = BreastCancerDataset(x_val_scaled, y_val)
test_dataset = BreastCancerDataset(x_test_scaled, y_test)Importiamo il dataloader e inizializziamo gli oggetti.
from torch.utils.data import DataLoader
train_loader = DataLoader(
dataset=train_dataset,
batch_size=16,
shuffle=True,
drop_last=True
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=16,
shuffle=False,
drop_last=True
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=16,
shuffle=False,
drop_last=True
)La potenza del DataLoader è che permette di specificare se fare lo shuffling dei nostri dati e in che numero di batch i dati debbano essere forniti al modello. La batch size è da considerarsi un iperparametro del modello e quindi può impattare i risultati delle nostre inferenze.
Implementazione della rete neurale in PyTorch
Creare un modello in PyTorch potrebbe sembrare complesso, ma in realtà richiede la comprensione solo di alcuni concetti di base.
- Quando scriviamo un modello in PyTorch, useremo un approccio basato su oggetti, come per i dataset. Significa che creeremo una classe come
class MyModelche eredita dalla classenn.Moduledi PyTorch - PyTorch è un software di differenziazione automatica. Significa che quando andiamo a scrivere una rete neurale basata sull'algoritmo di backpropagation, il calcolo delle derivate per calcolare la loss è fatto dietro alle quinte. Questo richiede la scrittura di un po' di codice dedicato che potrebbe trarre in confusione la prima volta.
Consiglio al lettore vuole conoscere le basi di come funzionano le reti neurali di consultare l'articolo Introduzione alle reti neurali - pesi, bias e attivazione
Detto ciò, vediamo come appare il codice per scrivere un modello di regressione logistica.
class LogisticRegression(nn.Module):
"""
La nostra rete neurale accetta num_features e num_classes.
num_features: numero di caratteristiche da cui apprendere
num_classes: numero di classi in output da prevedere (in questo caso, 1 o 2, poiché l'output è binario (0 o 1))
"""
def __init__(self, num_features, num_classes):
super().__init__() # inizializziamo il metodo init di nn.Module
self.num_features = num_features
self.num_classes = num_classes
# creiamo un singolo strato di neuroni su cui applicare la regr. logistica
self.linear1 = nn.Linear(in_features=num_features, out_features=num_classes)
def forward(self, x):
logits = self.linear1(x) # facciamo passare in nostri dati nello strato
probs = torch.sigmoid(logits) # applichiamo una funzione sigmoide per ottenere le probabilità di appartenenza ad una classe (0 o 1)
return probs # restituiamo le probabilità
La nostra classe eredita da nn.Module. Questa classe fornisce i metodi che dietro alle quinte permettono al modello di funzionare.
Metodo __init__
Il metodo __init__ di una classe contiene la logica che viene eseguita all'instanziamento di una classe in Python. Qui passiamo due argomenti: il numero di feature e il numero di classi da predire. num_features corrisponde al numero di colonne che compongono il nostro dataset meno la nostra variabile target, mentre num_classes corrisponde al numero di risultati che la rete neurale deve restituire.
Oltre ai due argomenti e alle loro variabili di classe, vediamo la riga super().__init__(). La funzione super inizializza il metodo init della classe madre. Questo permette di avere le funzionalità di nn.Module all'interno del nostro modello.
Sempre nel blocco init, vediamo l'implementazione di uno strato lineare self.linear1, che accetta come argomenti il numero di feature e il numero di risultati da restituire.
Metodo forward()
Facendo def forward(self, x) diciamo a Python di fare un override del metodo forward all'interno della classe madre nn.Moduledi PyTorch. Infatti, questo metodo viene chiamato all'esecuzione di un forward pass - cioé quando i nostri dati passano da uno strato all'altro.
forward accetta l'input \( x \), che contiene le feature su cui il modello tarerà la sua performance.
L'input passa attraverso il primo strato, creando la variabile logits. I logit sono i calcoli della rete neurale che non sono ancora convertiti in probabilità dalla funzione di attivazione finale, che in questo caso è una sigmoide. Di fatto, sono la rappresentazione interna della rete neurale prima di essere mappata ad una funzione che ne permette l'interpretazione.
In questo caso la funzione sigmoide andrà a mappare i logit a delle probabilità comprese tra 0 e 1. Se l'output è minore di 0, allora la classe sarà 0 altrimenti sarà 1. Questo avviene nella riga self.probs = torch.sigmoid(x).
Funzioni di utility per plotting e calcolo accuracy
Creiamo delle funzioni di utilità da utilizzare nel training loop che vedremo a breve. Queste due servono per calcolare la accuratezza alla fine di ogni epoca e a visualizzare le curve di performance alla fine del training.
def compute_accuracy(model, dataloader):
"""
Questa funzione mette il modello in modalità di valutazione (model.eval()) e calcola la accuratezza rispetto al dataloader in input
"""
model = model.eval()
correct = 0
total_examples = 0
for idx, (features, labels) in enumerate(dataloader):
with torch.no_grad():
logits = model(features)
predictions = torch.where(logits > 0.5, 1, 0)
lab = labels.view(predictions.shape)
comparison = lab == predictions
correct += torch.sum(comparison)
total_examples += len(comparison)
return correct / total_examples
def plot_results(train_loss, val_loss, train_acc, val_acc):
"""
Questa funzione riceve delle liste di valori e crea dei grafici fianco a fianco per mostrare le performance di training e validation
"""
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
ax[0].plot(
train_loss, label="train", color="red", linestyle="--", linewidth=2, alpha=0.5
)
ax[0].plot(
val_loss, label="val", color="blue", linestyle="--", linewidth=2, alpha=0.5
)
ax[0].set_xlabel("Epoch")
ax[0].set_ylabel("Loss")
ax[0].legend()
ax[1].plot(
train_acc, label="train", color="red", linestyle="--", linewidth=2, alpha=0.5
)
ax[1].plot(
val_acc, label="val", color="blue", linestyle="--", linewidth=2, alpha=0.5
)
ax[1].set_xlabel("Epoch")
ax[1].set_ylabel("Accuracy")
ax[1].legend()
plt.show()Addestramento del modello
Ora veniamo alla parte dove la maggior parte dei neofiti del deep learning hanno difficoltà: il loop di training di PyTorch.
Guardiamo il codice e poi commentiamolo
import torch.nn.functional as F
model = LogisticRegression(num_features=x_train_scaled.shape[1], num_classes=1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
num_epochs = 10
train_losses, val_losses = [], []
train_accs, val_accs = [], []
for epoch in range(num_epochs):
model = model.train()
t_loss_list, v_loss_list = [], []
for batch_idx, (features, labels) in enumerate(train_loader):
train_probs = model(features)
train_loss = F.binary_cross_entropy(train_probs, labels.view(train_probs.shape))
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print(
f"Epoch {epoch+1:02d}/{num_epochs:02d}"
f" | Batch {batch_idx:02d}/{len(train_loader):02d}"
f" | Train Loss {train_loss:.3f}"
)
t_loss_list.append(train_loss.item())
model = model.eval()
for batch_idx, (features, labels) in enumerate(val_loader):
with torch.no_grad():
val_probs = model(features)
val_loss = F.binary_cross_entropy(val_probs, labels.view(val_probs.shape))
v_loss_list.append(val_loss.item())
train_losses.append(np.mean(t_loss_list))
val_losses.append(np.mean(v_loss_list))
train_acc = compute_accuracy(model, train_loader)
val_acc = compute_accuracy(model, val_loader)
train_accs.append(train_acc)
val_accs.append(val_acc)
print(
f"Train accuracy: {train_acc:.2f}"
f" | Val accuracy: {val_acc:.2f}"
)A differenza di TensorFlow, PyTorch richiede la scrittura di un loop di training in puro Python.
Vediamo il procedimento per punti:
- Instanziamo il modello e l'ottimizzatore
- Decidiamo un numero di epoche
- Creiamo un for loop che itera tra le epoche
- Per ogni epoca, settiamo il modello in modalità training con
model.train()e cicliamo neltrain_loader - Per ogni batch del
train_loader, calcolare la loss, portare a 0 il calcolo delle derivate conoptimizer.zero_grad()e aggiornare i pesi della rete conoptimizer.step()
A questo punto il training loop è completo, e se si vuole si può integrare la stessa logica sul dataloader di validazione come scritto nel codice.
Ecco il risultato del training dopo il lancio di questo codice
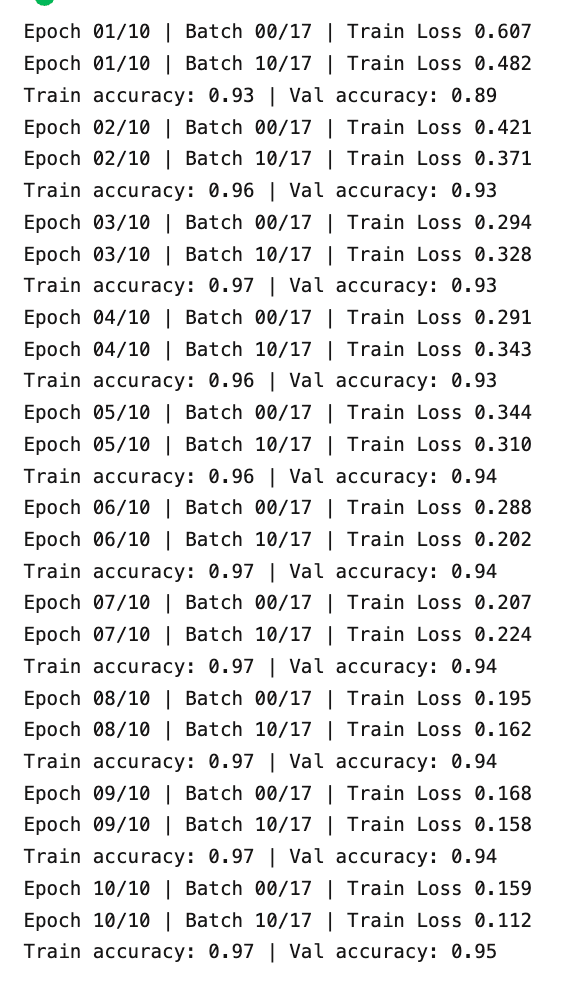
Valutazione delle performance della rete neurale
Usiamo la utility function creata precedentemente per mettere su grafico loss in training e validazione.
plot_results(train_losses, val_losses, train_accs, val_accs)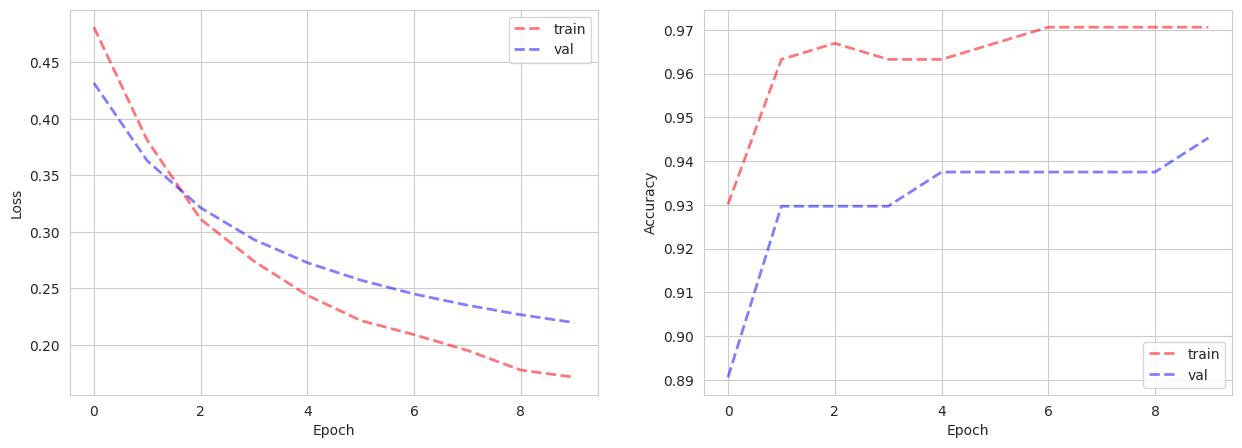
Il nostro modello di classificazione binaria riesce velocemente a convergere ad una accuracy alta, e vediamo come la loss si abbassi alla fine di ogni epoca.
Il dataset risulta essere semplice da modellare e il numero basso di esempi non aiuta a vedere una convergenza più graduale verso performance alte da parte della rete.
Sottolineo che è possibile integrare il software TensorBoard in PyTorch per poter loggare le metriche di performance automaticamente tra i vari esperimenti.
Creare le predizioni
Siamo arrivati alla parte finale di questa guida. Vediamo il codice per creare le predizioni per il nostro intero dataset.
# trasformiamo tutte le nostre feature con lo scaler
X_scaled_all = scaler.transform(X)
# trasformiamo in tensori
X_scaled_all_tensors = torch.tensor(X_scaled_all, dtype=torch.float32)
# impostiamo il modello in modalità inferenza e creiamo le predizioni
with torch.inference_mode():
logits = model(X_scaled_all_tensors)
predictions = torch.where(logits > 0.5, 1, 0)
df['predictions'] = predictions.numpy().flatten()Ora importiamo il pacchetto metrics da Sklearn che permette di calcolare velocemente la matrice di confusione e il report di classificazione direttamente sul nostro dataframe pandas.
from sklearn import metrics
from pprint import pprint
pprint(metrics.classification_report(y_pred=df.predictions, y_true=df.target))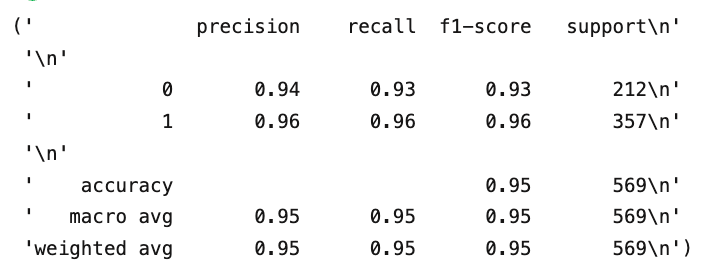
E la matrice di confusione, che mostra sulla diagonale il numero di risposte corrette
metrics.confusion_matrix(y_pred=df.predictions, y_true=df.target)
>>> array([[197, 15],
[ 13, 344]])Ecco una piccola funzione per creare un linea di demarcazione che separa le classi nel grafico PCA
def plot_boundary(model):
w1 = model.linear1.weight[0][0].detach()
w2 = model.linear1.weight[0][1].detach()
b = model.linear1.bias[0].detach()
x1_min = -1000
x2_min = (-(w1 * x1_min) - b) / w2
x1_max = 1000
x2_max = (-(w1 * x1_max) - b) / w2
return x1_min, x1_max, x2_min, x2_max
sns.scatterplot(x=x0, y=x1, hue=y)
plt.title("Proiezione PCA")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.xticks([])
plt.yticks([])
plt.plot([x1_min, x1_max], [x2_min, x2_max], color="k", label="Classificazione", linestyle="--")
plt.legend()
plt.show()Ed ecco come il modello separa le cellule benigne da quelle maligne
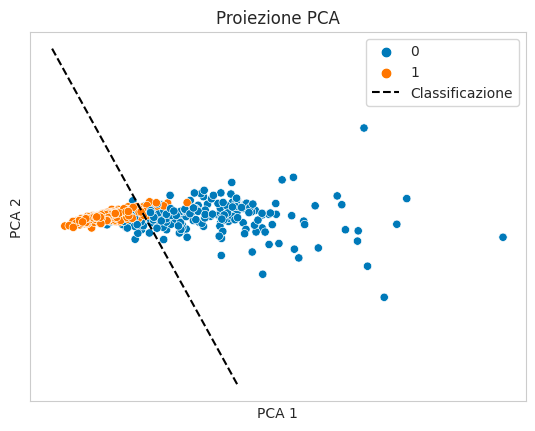
Conclusioni
In questo articolo abbiamo visto come creare un modello di classificazione binaria con PyTorch, partendo da un dataframe Pandas.
Abbiamo visto come appare il loop di training, come valutare il modello e come creare delle predizioni e delle visualizzazioni per aiutare l'interpretazione.
Con PyTorch è possibile creare reti neurali molto complesse...basti pensare che Tesla, l'azienda costruttrice di auto elettriche basate su AI, usa proprio PyTorch per creare i suoi modelli.
Per chi vuole iniziare il suo percorso nel deep learning, imparare PyTorch quanto prima diventa un task a priorità alta poiché consente di creare tecnologie importanti in grado di risolvere problemi complessi basati sui dati.





Commenti dalla community