
In questo articolo voglio presentare al lettore una visione olistica di quello che per me è processo di data science.
Tale processo viene spesso menzionato in materiale educativo di settore, come corsi online e manuali ed è il punto di partenza del professionista che vuole muovere i suoi primi passi nel campo dell'analisi dei dati. Questo perché il processo di data science è molto simile al metodo scientifico di Galileo che si studia a scuola.
Diventa quindi un aggancio dalla semplice interpretazione che permette a chi si muove nel campo di comprendere e spiegare efficacemente ogni step del progetto che sta osservando.
Questo processo spesso include le seguenti fasi:
- inquadramento del problema
- raccolta del dato
- preprocessing e trasformazioni
- esplorazione
- modellazione e interpretazione dei risultati
- go-live
Quando il data scientist lavora da solo, ogni aspetto di questo processo è sotto la sua completa responsabilità.
Infatti, la figura del data scientist è molto ricercata proprio per il suo skill set variegato, che copre molteplici campi di competenza, sia quelli più orientati all'ingegneria del software, come creazione di programmi per reperire i dati dal web, che l'aspetto più statistico, che si esprime nella fase di preprocessing e esplorazione.
Quando invece il data scientist è inserito in un team, ecco che il suo focus viene diretto a fasi specifiche del processo di data science. Questo perché figure come il data engineer e il data analyst (ma anche altre che qui non menziono) vengono impiegate per gestire con altrettanto focus le loro rispettive aree di expertise.
Declinazione fase - ruolo nel processo di data science
Per comprendere al meglio i ruoli e le attività delle figure menzionate può essere interessante associare ogni fase del processo di data science ad un ruolo.
1. Inquadramento del problema
Figure necessarie: tutte
Figure optional: nessuna
Questa è una fase di brainstorming, dove si parla del problema e di come affrontarlo per migliorare in qualche modo il processo che è afflitto da tale problema.
Ogni ruolo è in grado di contribuire in maniera importante alla definizione e messa a fuoco del problema, cosa lo causa e come è composto in modo da analizzare un piano risolutivo.
Solitamente durante questa fase di kick-off del progetto ci si riunisce più volte in team e si discute di cosa si vuole fare, risolvere e ottenere alla fine del progetto. I membri chiave del progetto prendono appunti, fanno domande e guidano la conversazione per gli individui che non sono direttamente coinvolte nello sviluppo.
Gli strumenti usati coinvolgono diagrammi di flusso, di Gantt e creazione di documentazione preliminare per offrire al team esteso una visione di come il progetto sarà costituito dal punto di vista gestionale tecnico.
Insieme alle figure che lavorano nel mondo dei dati, in questa fase sono coinvolti anche stakeholder e membri di altri team che possono contribuire alla conversazione.
2. Raccolta del dato
Figure necessarie: Data engineer
Figure optional: Data scientist
Nella fase di raccolta dati il data engineer è essenziale. A dispetto di quanti molti pensano, un data scientist da solo non è in grado di creare impalcature di raccolta dati su larga scala.
Sebbene il data scientist abbia conoscenze anche in questo campo, le specifiche di tale lavoro sono responsabilità del data engineer poiché non si parla solo di scraping, richieste HTTP a API o altro, ma di mettere insieme tutte queste fonti e creare sistemi di memorizzazione del dato efficienti.
Un data engineer è esperto dei sistemi di archiviazione e processamento nel cloud, come Amazon Web Services (AWS) o Azure di Microsoft. È in grado di scegliere la piattaforma adatta per massimizzare l'efficienza sia in termini di costi che di tempo. Sentiamo spesso i termini data lake e warehouse - questi non sono altro che database con scopi diversi posizionati, solitamente, nel cloud.
Servizi del genere sono tipicamente usati per progetti di livello enterprise o comunque molto grandi e strutturati e quindi un data engineer diventa molto importante proprio in contesti del genere.
In pratica, il data engineer trova modo di lavorare soprattutto in un contesto legato al big data, con un numero molto elevato di terabyte processati ogni giorno dai sistemi messi in piedi dal team di software e data engineering.
Come figura optional troviamo il data scientist, che può affiancare il DE nella conversazione che andrà a trattare la struttura del dato in database, poiché saranno i data scientist e analyst a lavorare con quel dato una volta raccolto e trasformato.
Il database utilizzato, la schematizzazione del dato in modelli e molto altro è quindi in mano al data engineer che si occuperà, in seguito alla raccolta, anche della sua trasformazione.
3. Preprocessing e trasformazioni
Figure necessarie: Data engineer
Figure optional: Data scientist
Anche qui un data engineer è essenziale per strutturare pipeline di preprocessing del dato. Il bisogno di un data engineer è che di nuovo gli strumenti nel cloud diventano essenziali per lavorare con un grosso volume di dati in maniera efficiente.
Fuori dal contesto dei (quasi) big data, un data scientist può trovare modo di far funzionare le cose, ma comunque in modo meno efficiente di un data engineer.
Un data engineer potrebbe scegliere di usare Apache Airflow invece di NiFi per fare scheduling dei task oppure per gestire il flusso in entrata e in uscita dei dati.
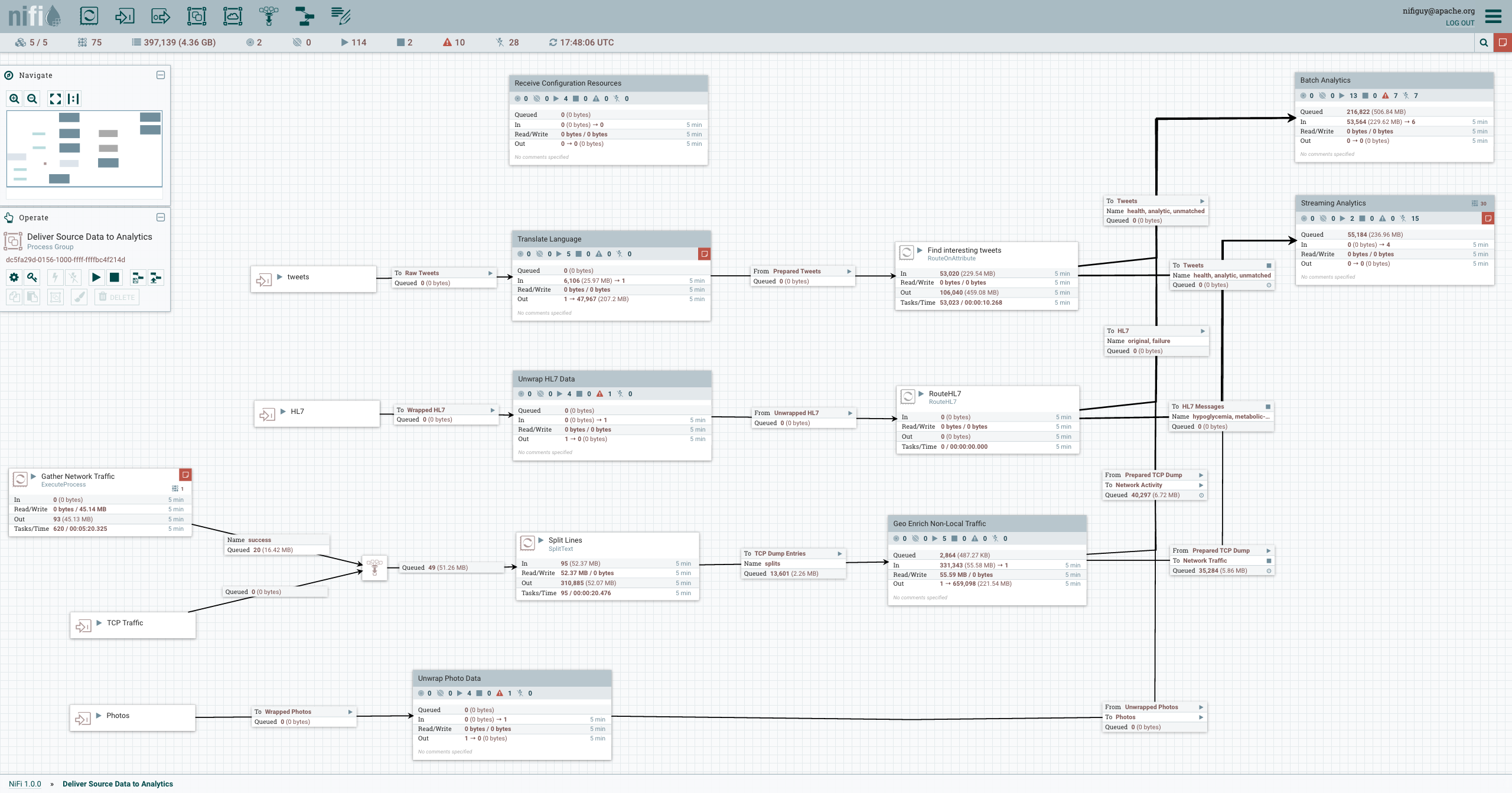
Questi sono solo due strumenti che permettono al professionista di strutturare e applicare l'ETL (extract, load, transform) sui dati.
Una delle grandi contribuzioni di un data engineer è proprio quella di poter guidare il team nella scelta della strumentazione adatta.
Anche qui il data scientist può affiancare il data engineer per contribuire agli step di preprocessing.
4. Esplorazione
Figure necessarie: Data scientist, data analyst
Figure optional: Data engineer
In base alla grandezza del progetto, la fase di esplorazione e comprensione del dato viene fatta dagli esperti di analytics (che di solito sono i data scientist / analyst) oppure da questi e anche il team di data engineering.
Lavorando strettamente con database di ogni tipo, i data engineer sono molto abili con SQL. Questo li rende molto utili anche nella fase di esplorazione del dato, non solo nella fase di memorizzazione.
Nella fase di analisi esplorativa del dato, il professionista interroga dati usabili (che lo sono tipicamente solo in seguito alla fase di preprocessing) al fine di trovare insight, anomalie e pattern utili. Questa fase è essenziale per capire se il dato è veramente usabile per il destinatario (che può essere un utente umano o un modello di machine learning) e per comprendere i next step.
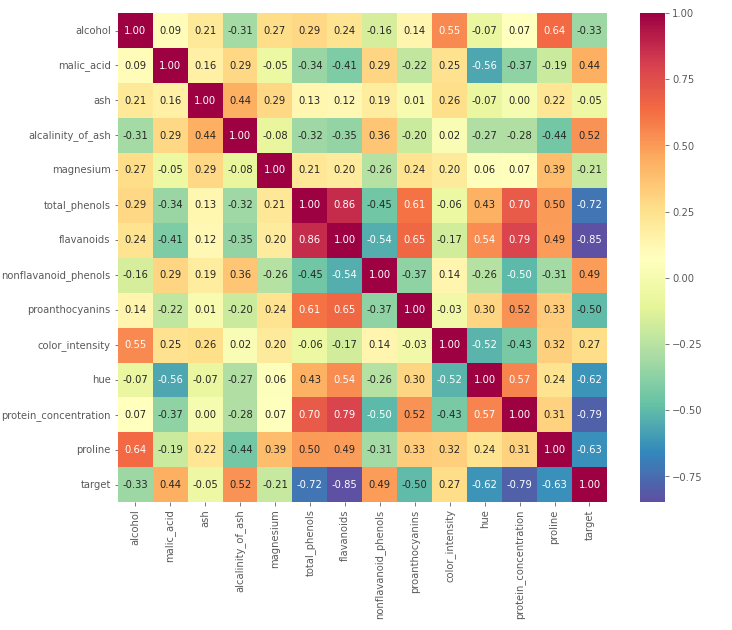
Questo viene fatto attraverso query SQL, visualizzazione e report per i membri del team e stakeholder.
Ad un analista servono solo conoscenze di SQL e di data visualization per coprire completamente la fase di esplorazione del dato. Tutto il resto è conoscenza che si costruisce sopra quei due mattoni fondamentali.
La fase esplorativa si conclude quando si è solitamente superata una validazione da parte del team responsabile dei dati e dagli stakeholder. Se il professionista lavora da solo, allora la fase esplorativa si conclude con un report finale che dettaglia gli insight trovati oppure con una fase di modellazione del dato.
5. Modellazione e interpretazione dei risultati
Figure necessarie: Data scientist
Figure optional: Data analyst
Un data scientist si trova a suo agio durante la fase di modeling più di qualsiasi altro professionista con un ruolo nel mondo dei dati. Questa è la sua specialità perché permette di applicare tutte le hard skill di questa figura, dalle competenze di statistica a quelle di sperimentazione e ottimizzazione.
In questa fase il team di data science si riunisce per valutare il feature set e inquadrare il problema in una ottica di machine learning. Si comprende se è un problema che può essere affrontato con un approccio supervisionato, oppure se c'è bisogno di generare nuovi dati attraverso il feature engineering per arricchire il modello.
Tale modello, quando addestrato correttamente sui dati a disposizione, potrà fornire importanti benefici al business, quali automazione di una serie di task intensivi e inefficienti se portati avanti da un umano (generazione di testi, categorizzazione di contenuto, etc.) oppure predire un evento futuro con un errore possibilmente piccolo.
Un data scientist è un abilitatore dell'automazione
La fase di modellazione è caratterizzata anche dalla costruzione di impalcature di sperimentazione. Infatti, raramente un modello funziona alla prima iterazione, e richiede invece molti step di correzione e fine-tuning per raggiungere performance apprezzabili.
Questo sistema dev'essere mantenuto e gestito dai data scientist, che tracciano e analizzano i risultati dei vari esperimenti. Strumenti come MLFlow e Neptune.ai vengono usati per questo tipo di compito.
Il data analyst offre supporto al scientist, che può contribuire all'analisi delle performance di vari modelli e nella documentazione.
In un contesto enterprise, i modelli predittivi vengono testati usando tecniche come AB test con un gruppo ristretto di utenti prima di essere rilasciati ufficialmente.
6. Go-live
Figure necessarie: Data scientist
Figure optional: Data engineer
La fase di go-live, detta anche deployment, coinvolge principalmente il data scientist con competenze di ML Ops (machine learning operations). Queste competenze riguardano sistemi e infrastrutture per gestire diversi modelli predittivi e tracciare le performance nel tempo.
L'obiettivo principale del professionista che ha responsabilità in questa fase è quello di assicurarsi che i modelli deployati siano in linea con le performance attese e non mostrino drift: quando qualcosa nel mondo cambia che il modello non può conoscere e che quindi impatta negativamente sulle performance.
La preoccupazione principale del data scientist coinvolto nel processo di go-live è quella di tracciare le performance dei modelli e che questi non si spostino significativamente dalle performance mostrate in un setting sperimentale.
Insieme agli strumenti di tracciamento delle performance che ho menzionato prima, qui un data scientist, in collaborazione anche con dei software developer, può scegliere come servire il modello al pubblico e creare quindi API o microservizi collegati tra loro.
La libreria in Python più versatile al momento per configurare delle API è FastAPI.
Il data engineer può essere coinvolto per aiutare il data scientist a configurare i sistemi nel cloud.
Visione olistica del processo di data science
Se valutiamo il coinvolgimento di queste figure professionali nel processo di data science, vediamo come tutte contribuiscano in maniera fondamentale allo svolgersi di ogni fase, aumentando l'efficienza di ogni processo.
Il processo di data science è quindi naturalmente inclusivo di molteplici figure professionali, soprattutto se esteso ad un contesto enterprise.
È vero che se il professionista lavora da solo o in un piccolo team, allora questi possono focalizzarsi su processi più snelli e lavorare su di essi in prima persona senza un supporto da parte dello specialista. Va notato però che i processi in questione soffriranno dell'assenza di queste figure.
Qui langue un pericolo per lo stakeholder inesperto del campo:
progetti grandi consegnati a team piccoli possono soffrire sugli aspetti più fondamentali (soprattutto step 1 e 2 del processo).
Lavorare in solitudine o in team piccoli su progetti molto grandi come software as a service (SAS) a tema analytics può essere una sfida importante, dove alcune scelte fondamentali possono essere soggetta a compromessi a causa di competenze non specializzate.
Ad esempio, un data scientist esperto in modeling avrà ottimi risultati nell'addestrare un modello predittivo, ma potrebbe perdersi nella scelta dell'infrastruttura cloud ideale dove deployare il suo modello.
Lo stakeholder che è interessato a innescare un progetto basato sui dati dovrebbe essere consapevole del processo di data science e di come questo possa includere figure professionali specializzate che possono fare la differenza.
Se i dati esistono già nel mondo e sono usabili, ad esempio un dataset di Kaggle, il progetto potrebbe non richiedere figure come il data engineer o il scientist poiché il focus sarebbe puramente analitico.
Va considerato anche il destinatario del risultato finale: un modello o una dashboard deployati per uso interno possono essere caratterizzati da processi molto più snelli e meno stringenti rispetto agli stessi invece consegnati ad un cliente che paga una fee mensile.
Conclusione
Vedere il processo di data science come un ciclo di fasi che naturalmente coinvolgono tutte le figure specializzate in ambito dati è a mio avviso essenziale - permette a chi fa questa valutazione di comprendere profondamente i vantaggi e le limitazioni di cui beneficia o soffre il progetto, e da consapevolezza maggiore dell'output finale.
Sono dell'idea che una conversazione costante tra membri di team diverso, ma appartenente allo stesso campo (leggere data engineering e science) possa beneficiare enormemente il progetto, in modi impossibili da prevedere ab origine.
Il lupo solitario invece dovrebbe circondarsi di colleghi virtuali quanto più possibile: consiglio infatti di ingaggiare persone sui social e parlare con loro direttamente per migliorare le performance su un task complesso.
Infine, lo stakeholder principale, che sia un CTO oppure un imprenditore con una ambizione di sfondare in ambito data, dovrebbe prima di tutto informarsi sul processo di data science al fine di pianificare adeguatamente il progetto lato business.
L'inclusione o meno di una di queste figure può impattare notevolmente sul business, e questa non dovrebbe essere una sorpresa, ma bensì una condizione precedentemente pensata e compresa profondamente.





Commenti dalla community