
Il machine learning è una branca dell'intelligenza artificiale che si occupa di creare modelli in grado di effettuare previsioni su dati non visti in precedenza.
Uno dei primi passi per costruire un modello di machine learning è la scelta della giusta architettura e dei parametri del modello.
Questi parametri, chiamati iperparametri, sono settati a priori e non vengono appresi durante il processo di training. I valori degli iperparametri possono avere un impatto significativo sulle prestazioni del modello.
Sta allo sviluppatore trovare un set di iperparametri che massimizzano le performance del modello tale che questo possa generalizzare correttamente su dati non visti.
Tuttavia, trovare la combinazione ottimale di valori può essere una sfida, soprattutto quando ci sono molti iperparametri da considerare. In questi casi, la grid search (ricerca a griglia) può essere una soluzione efficace per risolvere il problema.
La Grid Search è una delle tecniche più utilizzate nel tuning degli iperparametri, un processo essenziale per migliorare le performance dei modelli di machine learning.
Gli iperparametri sono parametri impostati prima dell'addestramento del modello e possono influenzare significativamente i risultati. Un'ottimizzazione corretta può ridurre l'errore di generalizzazione del modello e migliorare la sua capacità predittiva.
In questo articolo, vedremo come utilizzare la Grid Search in Python con la libreria scikit-learn, passo dopo passo, con esempi pratici di codice.
La grid search è una tecnica utilizzata nel machine learning per trovare i migliori iperparametri di un modello e consiste nel definire una griglia di valori per ogni iperparametro e testare tutte le possibili combinazioni di valori.
In questo modo è possibile trovare i valori di iperparametri che massimizzano le prestazioni del modello.
Nella pipeline di machine learning, applicare la grid search fa parte della fase chiamata hyperparameter tuning.
- Cosa è la grid search e come funziona
- Come usare Sklearn per applicare la grid search
Iniziamo!
Come funziona la grid search
Partiamo da un esempio per comprendere come funziona la grid search. Useremo la famosa libreria sklearn in Python per testare la logica di una grid search su un albero decisionale.
Andando sulla documentazione ufficiale di Sklearn per l'oggetto DecisionTreeClassifier troviamo una lista di iperparametri che questo accetta e che noi possiamo scegliere.
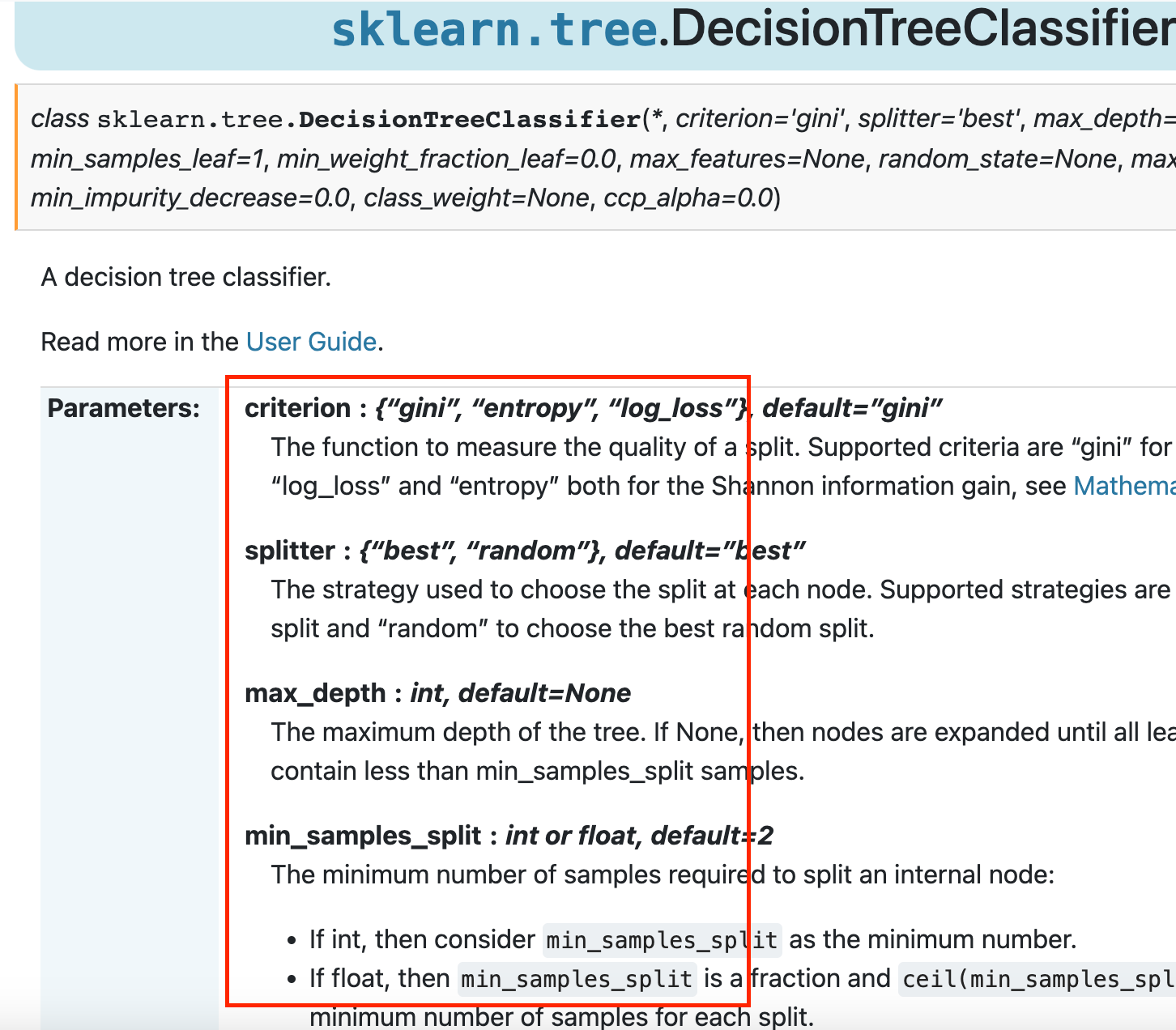
Questi e molti altri sono disponibili da visionare al link della documentazione.
Vediamo come l'iperparametro criterion possa assumere diversi valori ("gini", "entropy", etc.). La scelta di uno di questi valori potrà influenzare le prestazioni del modello.
Il parametro max_depth è spesso oggetto di grid search poiché influenza molto il comportamento dell'albero decisionale. Questo rappresenta la profondità massima di estensione dell'albero prima di giungere ad una previsione. Stesso discorso per min_samples_split, che definisice quanti campioni occorrono per creare un nodo nella struttura dell'albero.
La griglia potrebbe essere la seguente:
parametri = {
'max_depth': [2, 3, 4, 5, 10, 20],
'min_samples_split': [2, 3, 4, 5, 10, 20]
}La grid search testerebbe tutte le possibili combinazioni di valori nella griglia, ad esempio:
max_depth = 2, min_samples_split = 2
max_depth = 2, min_samples_split = 3
max_depth = 2, min_samples_split = 4
...
max_depth = 5, min_samples_split = 4
max_depth = 5, min_samples_split = 5
...Per ogni combinazione di valori, il modello viene addestrato e valutato utilizzando una metrica di valutazione, come l'accuratezza o l'F1-score. Alla fine della grid search, si selezionano i valori di iperparametri che massimizzano la metrica di valutazione.

Come applicare la grid search in Python con Sklearn
In Python, la grid search può essere facilmente applicata proprio grazie a Sklearn. Sklearn fornisce la classe GridSearchCV che implementa la grid search.
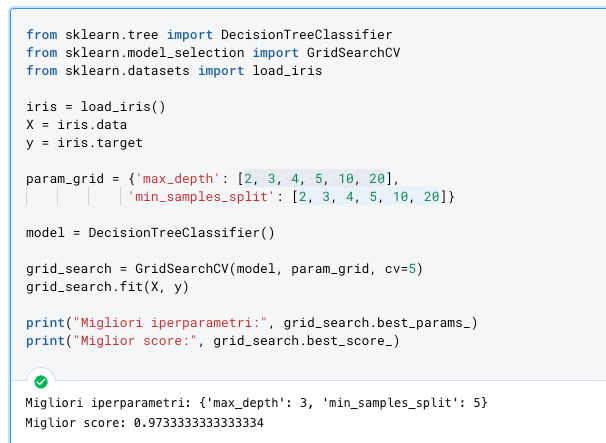
Ecco un esempio di come utilizzare la classe GridSearchCV per ottimizzare gli iperparametri di un albero di decisione in Python sfruttando il dataset Iris:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
param_grid = {'max_depth': [2, 3, 4, 5, 10, 20],
'min_samples_split': [2, 3, 4, 5, 10, 20]}
model = DecisionTreeClassifier()
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
print("Migliori iperparametri:", grid_search.best_params_)
print("Miglior score:", grid_search.best_score_)
La griglia di valori per gli iperparametri max_depth e min_samples_split è definita nel dizionario param_grid. La classe GridSearchCV viene inizializzata con l'albero decisionale, la griglia di valori degli iperparametri e il numero di fold per la cross-validation (cv=5). Infine, il metodo fit viene chiamato per eseguire la grid search.
Il risultato della grid search è stampato a schermo utilizzando le proprietà best_params_ e best_score_. La proprietà best_params_ restituisce i valori degli iperparametri che massimizzano il punteggio di validazione incrociata (best_score_).
L'oggetto grid_search può essere ora usato come un modello a se stante per un nuovo addestramento e validazione.
Tuttavia, è importante notare che la grid search può diventare molto lenta con molti iperparametri da esplorare e che potrebbero esserci approcci migliori in tal caso.
Inoltre, la grid search può portare alla selezione di modelli troppo complessi, che tendono a sovra-adattarsi ai dati di training.
Un modello che si sovra-adatta ai dati di addestramento non è in grado di generalizzare corretamente su dati non visti e diventa quindi inutile in un contesto di applicazione reale.
Leggi di più sull'overfitting visitando l'articolo qui
 Andrea D’Agostino
Andrea D’Agostino
Pertanto, è consigliabile utilizzare la grid search con cautela e combinare la sua applicazione con altre tecniche di tuning degli iperparametri, come la ricerca casuale o la bayesian optimization.
Conclusioni
La grid search è una tecnica potente per ottimizzare gli iperparametri dei modelli di machine learning e può essere particolarmente utile quando si hanno molti iperparametri da considerare.
Tuttavia, è importante considerare che la grid search può essere computazionalmente costosa se ci sono molti iperparametri da esplorare.
Inoltre, la grid search può portare alla selezione di modelli troppo complessi, che tendono a sovra-adattarsi ai dati di training.





Commenti dalla community