
Il concetto di cross-validazione estende direttamente da quello dell'overfitting, trattato nel mio precedente articolo.
La cross-validazione è una delle tecniche più efficaci proprio per evitare l'overfitting e per comprendere bene le performance di un modello predittivo.
Quando ho parlato di overfitting, ho diviso i miei dati in training e test set. Il training set ci è servito a ad addestrare il modello, il test set a valutare le sue performance. Ma questa metodica è sbagliata e non va applicata in casi reali. Questo perché possiamo indurre overfitting nel test set se addestriamo a lungo il nostro modello finché non troviamo la configurazione corretta.
Questo concetto prende il nome di data leakage ed è uno dei problemi più comuni e gravi che si possano fare nel campo. Infatti, se addestrassimo il nostro modello a performare bene sul test set, questo poi sarebbe "adeguato" solo per quel test set.
Che si intende per configurazione? Ogni modello è caratterizzato da una serie di iperparametri. Segue definizione
un iperparametro del modello è una configurazione esterna ad esso il cui valore non può essere stimato dai dati. Modificare un iperparametro modifica di conseguenza il comportamento del modello sui nostri dati e può migliorare o peggiorare le nostre performance.
Ad esempio un albero tree.DecisionTreeClassifier di Sklearn, ha max_depth come iperparametro che gestisce la profondità dell'albero. Modificare questo iperparametro modifica le performance del modello, in bene o in peggio. Non possiamo sapere il valore ideale di max_depth se non sperimentando. Oltre a max_depth, l'albero decisionale possiede molti altri iperparametri.
Quando selezioniamo il modello da usare sul nostro dataset, dobbiamo poi comprendere quali sono le configurazioni di iperparametri migliori. Questa attività si chiama tuning degli iperparametri.
Trovata la configurazione migliore, si porta il modello migliore, con la configurazione migliore, nel mondo "reale" - vale a dire il test set che è formato da dati che il modello non ha mai visto prima.
Al fine di testare la configurazione senza passare direttamente al test set, introduciamo un terzo set di dati, chiamato di validazione.
Il flusso generale è questo:
- Addestriamo il modello sul training set
- Testiamo le performance della configurazione attuale sul set di validazione
- Se e solo se siamo soddisfatti delle performance sul set di validazione, allora testiamo sul test set.
Ma perché complicarci la vita inserendo un ulteriore set per valutare le performance? Perché non usare la classica divisione training-test set?
Il motivo è semplice ma è estremamente importante.
Fare machine learning è un processo iterativo.
Per iterativo si intende che un modello può e dev'essere valutato più volte con configurazioni diverse per capire quale è la condizione più performante. Il set di validazione ci permette proprio di testare diverse configurazioni e selezionare quella migliore per il nostro scenario, senza il rischio di overfitting.
Ma c'è un problema. Dividendo il nostro dataset in tre parti andiamo a ridurre il numero di esempi disponibili al nostro modello per l'addestramento. Inoltre, poiché la divisione usuale è 50-30-20, i risultati del modello potrebbero dipendere casualmente da come i dati sono stati distribuiti nei vari set.
La cross-validazione risolve questo problema, andando a rimuovere il set di validazione dall'equazione e preservando il numero di esempi disponibili al modello per l'apprendimento.
Cosa è la cross-validazione?
La cross-validazione è uno dei concetti più importanti nel machine learning. Questo perché ci permette di creare un modello in grado di generalizzare, cioè in grado di creare predizioni coerenti anche su dati non appartenenti al set di addestramento.
Un modello in grado di generalizzare è un modello utile, potente.
Fare cross-validazione significa dividere i nostri dati di addestramento in diverse porzioni e testare il nostro modello su parti alcune di queste parti. Il test set continua ad essere usato per la valutazione finale, mentre le performance del modello vengono valutate sulle porzioni generate dalla cross-validazione. Questa metodica viene chiamata K-Fold, che vedremo meglio in dettaglio tra poco.
In basso una immagine che riassume questo detto finora.
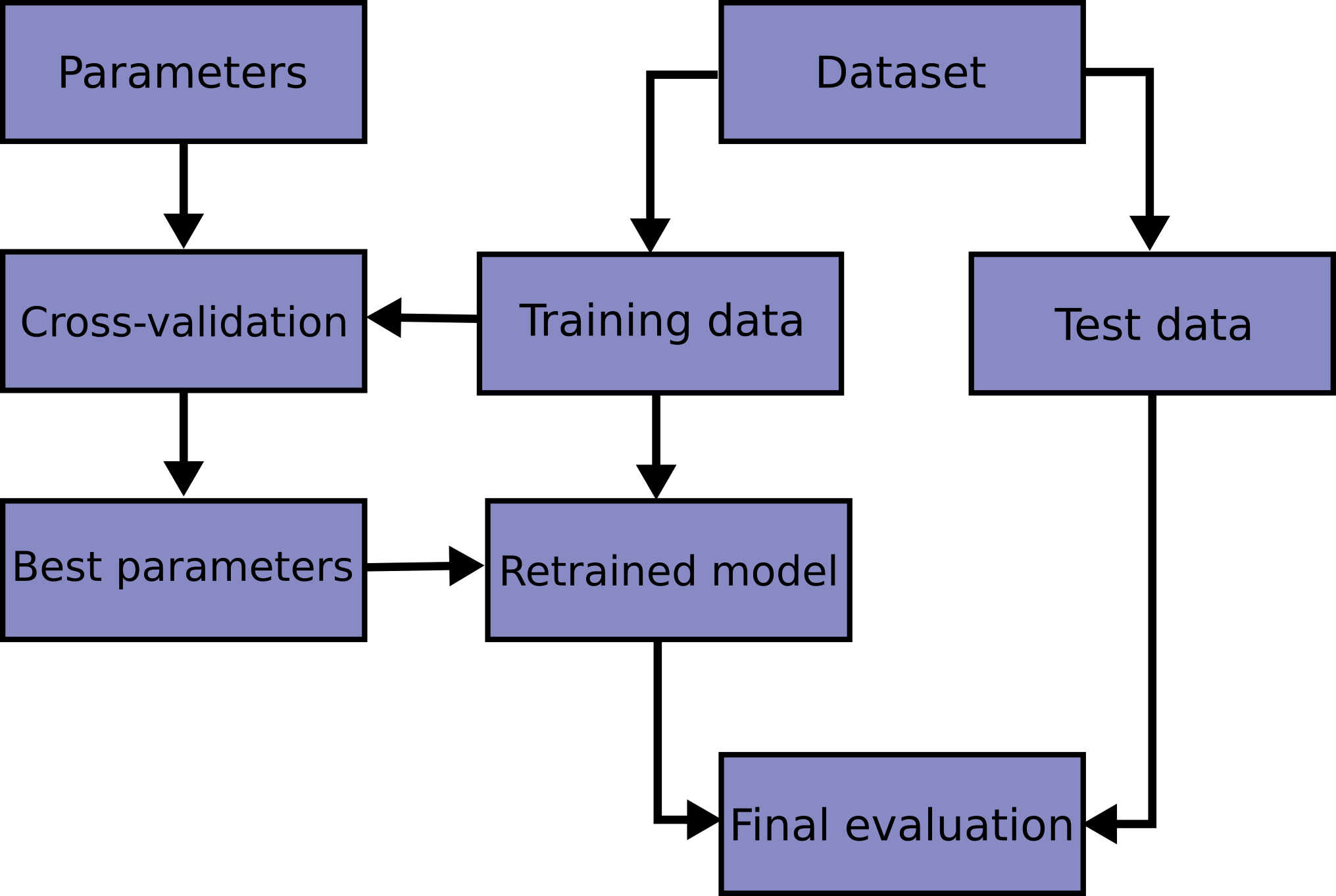
Cross-validazione K-Fold
La cross-validazione può essere fatta in modi diversi, ma ogni metodo è adatto ad uno scenario diverso. In questo articolo vedremo la cross-validazione K-Fold, che è sicuramente la tecnica di cross-validazione più popolare. Altri varianti popolari sono la cross-validazione stratificata e quella basata su gruppi.
Il training set viene diviso in k-fold (leggiamo "porzioni") e il modello viene addestrato su k-1 porzioni. La porzione rimanente viene usata per valutare il modello.
Il tutto avviene nel cosiddetto cross-validation loop - il ciclo di cross-validazione. Vediamo una immagine presa da Scikit-learn.org che mostra questo concetto chiaramente
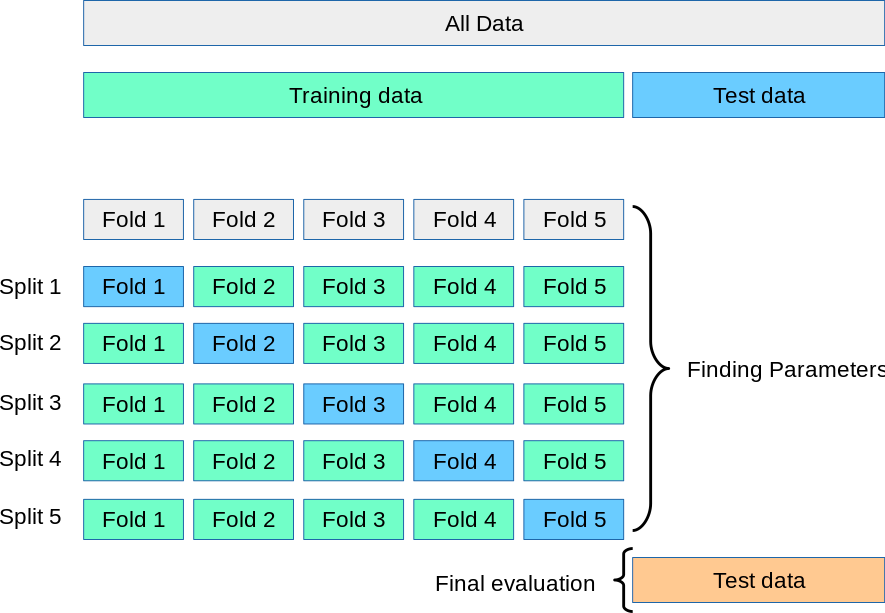
Dopo aver interato attraverso ogni split, avremo come risultato finale la media delle performance. Questo aumenta la validità delle performance, in quanto un modello "nuovo" viene addestrato su ogni porzione del dataset di addestramento. Avremo quindi un punteggio finale che riassume la performance del modello in tanti step di validazione - una metodica molto affidabile rispetto alla performance in una singola iterazione!
Andiamo a scomporre il processo:
1. Randomizzare ogni riga del dataset
2. Dividere il dataset in k porzioni
3. Per ogni gruppo
1. Creare una porzione di test
2. Allocare il restante all'addestramento
3. Addestrare il modello e valutarlo sui menzionati set
4. Salvare la performance
4. Valutare le performance generali prendendo la media dei punteggi alla fine del processo
Il valore di k è tipicamente 5 o 10, ma si può usare la regola di Sturges per stabilire un numero più preciso di split
\[ numero\_di\_split = 1 + \log_2{(N)} \]
Il loop di cross-validazione
Ho poco fa menzionato il loop di cross-validazione. Andiamo più in profondità in questo concetto che è fondamentale ma spesso trascurato dai giovani analisti.
Fare cross-validazione, di per sé, è già molto utile. Ma in alcuni casi è necessario andare oltre e testare nuove idee e ipotesi per migliorare ulteriormente il proprio modello.
Tutto questo va fatto all'interno del ciclo di cross-validazione, che è il punto 3 del flusso citato sopra.
Ogni esperimento dev'essere effettuato all'interno del loop di cross-validazione.
Poiché la cross-validazione ci permette di addestrare e testare il modello più volte e tirare le somme alla fine con una media, bisogna inserire tutte le logiche che vanno a modificare il comportamento del modello proprio all'interno della cross-validazione. Non fare ciò rende impossibile misurare l'impatto delle nostre ipotesi.
Vediamo ora degli esempi.
Implementare la cross-validazione K-Fold in Python
Usando Sklearn, vediamo un template per applicare la cross-validazione in Python. Useremo Sklearn per generare un dataset fantoccio per un task di classificazione e useremo la accuratezza e il ROC-AUC score per valutare il nostro modello.
Alla fine otterremo un punteggio ROC-AUC medio attraverso tutti gli split.
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn import metrics
# creiamo un dataset per un task di classificazione
X, y = datasets.make_classification(n_samples=2000, n_features=20, n_classes=2, random_state=42)
# creiamo l'oggetto KFold applicando la regola di Sturges
sturges = int(1 + np.log(len(X)))
kf = KFold(n_splits=sturges, shuffle=True, random_state=42)
fold = 0
aucs = []
# QUESTO È IL LOOP DI CROSS-VALIDAZIONE!
for train_idx, val_idx, in kf.split(X, y):
# l'oggetto kf genera gli indici e i valori per le rispettive X e y, creando il set di validazione su cui testare il modello nello split.
X_tr = X[train_idx]
y_tr = y[train_idx]
X_val = X[val_idx]
y_val = y[val_idx]
# ----
# applicare qui le ipotesi che vogliamo testare
# ...
# ----
# qui addestriamo il modello
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_tr, y_tr)
# creiamo le predizioni e salviamo lo score nella lista aucs
pred = clf.predict(X_val)
pred_prob = clf.predict_proba(X_val)[:, 1]
acc_score = metrics.accuracy_score(y_val, pred)
auc_score = metrics.roc_auc_score(y_val, pred_prob)
print(f"======= Fold {fold} ========")
print(
f"Accuracy on the validation set is {acc_score:0.4f} and AUC is {auc_score:0.4f}"
)
# aggiorniamo il valore di fold così possiamo stampare il progresso
fold += 1
aucs.append(auc_score)
general_auc_score = np.mean(aucs)
print(f'\nOur out of fold AUC score is {general_auc_score:0.4f}')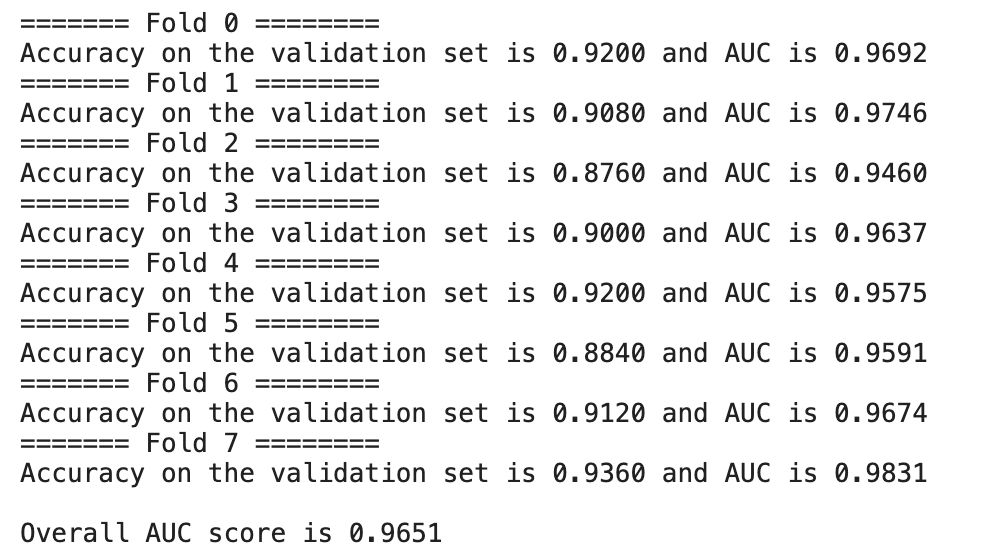
I risultati finali potrebbero cambiare data la natura stocastica (leggere casuale) di alcuni processi.
Conclusione
La cross-validazione è il primo, essenziale step da considerare quando si fa machine learning.
Ricordate sempre: se vogliamo fare feature engineering, aggiungere logiche o testare altre ipotesi - splittate sempre prima i dati con KFold e applicate tali logiche nel loop di cross-validazione.
Se abbiamo un buon framework di cross-validazione con dati di validazione rappresentativi della realtà e di quelli di addestramento, allora possiamo creare buoni modelli di machine learning, altamente generalizzabili.





Commenti dalla community