
Tabella dei Contenuti
- Che cos'è il Machine Learning?
- Che si intende per algoritmo, modello e performance?
- Cosa significa "addestrare un modello"?
- Tipi di apprendimento automatico
- Esempi di applicazione del machine learning
- Esempi pratici di machine learning in vari settori
- Come si lavora nel campo del machine learning?
- Conclusioni
Spiegare cosa sia il machine learning è relativamente semplice, ma il discorso va tarato in base all'interlocutore. Alcuni termini possono essere interpretati in modo diverso dipendentemente dal contesto, quindi è giusto ricercare un vocabolario quanto più generale possibile.
Il mio discorso sarà tarato per i neofiti del campo: persone che sanno poco di analisi quantitativa ma che vogliono iniziare ad approcciarsi alla materia per diversi motivi. In particolare, spero che questo articolo possa aiutare giovani figure ad orientarsi nello spazio universitario e lavorativo.
Che cos'è il Machine Learning?
Il termine machine learning si traduce in italiano apprendimento automatico ed è un ramo dell'intelligenza artificiale, che a sua volta è una branchia dell'informatica.
Nel machine learning si utilizzano i dati numerici per addestrare computer a completare dei compiti specifici. Il risultato è un algoritmo che a sua volta utilizza un modello del fenomeno per trovare la soluzione ad un problema. Il termine addestrare è fondamentale ed è l'attività che caratterizza maggiormente il campo. Successivamente vedremo nel dettaglio cosa significa.
La differenza tra un software che applica una regola specifica per risolvere un compito (ad esempio, se una frase contiene la parola "casa", creare una categoria "immobile" in un foglio di calcolo Excel) e un algoritmo di machine learning è che quest'ultimo non deve essere esplicitamente programmato per risolverlo correttamente.
Un algoritmo di machine learning utilizza un modello per inferire matematicamente delle regole nei dati tale che quest'ultimo sia in grado di trovare una soluzione generica al problema.
Diamo quindi una definizione generale:
Il machine learning è un ramo dell'intelligenza artificiale che permette a software di utilizzare dati numerici per trovare soluzioni a specifici compiti senza essere esplicitamente programmati per farlo.
Queste soluzioni possono essere più o meno accurate, e difficilmente si arriva a giungere performance paragonabili a quelle umane. Questo non deve però destare preoccupazioni: la maggior parte dei problemi affrontati col machine learning offre performance che soddisfano i casi d'uso. Ci basti pensare alle raccomandazioni dei prodotti su Amazon oppure all'identificazione di spam di Gmail. Vedremo degli esempi a breve.
Specializzazione Machine Learning
DeepLearning AI
Impara il machine learning dal corso leggendario di Andrew Ng, fondatore di Coursera e ex direttore della ricerca AI Google e Baidu.
Il machine learning si distingue dal deep learning, che rappresenta una sua sottocategoria specifica. Il deep learning utilizza le reti neurali, strutture complesse ispirate al cervello umano, per creare modelli in grado su dati più complessi e non strutturati, come immagini, audio e video.
 Andrea D’Agostino
Andrea D’Agostino
Che si intende per algoritmo, modello e performance?
Chiariamo alcuni concetti prima di continuare.
Un algoritmo non è altro che una serie di istruzioni seguite da un computer. È sicuramente una parola molto inflazionata al momento (algoritmo di Facebook, algoritmo di Twitter e così via), ma di fatto è un concetto molto semplice.
Un modello è un software che viene inserito nell'algoritmo e che ci serve per trovare la soluzione al nostro problema. Poiché spesso non conosciamo la vera soluzione, queste vengono chiamate predizioni.
Prima di essere utilizzato per risolvere problemi importanti, un modello viene sottoposto ad una serie di test che ne valutano la performance. Questa può essere calcolata solo se possediamo un set di dati che ci permette di confrontare la realtà con la predizione del modello. Se la performance ci soddisfa allora useremo il modello, altrimenti decidere di addestreremo nuovamente oppure di usarne un altro.

Cosa significa "addestrare un modello"?
Come abbiamo menzionato, ad un modello vengono forniti dati numerici per trovare delle soluzioni generalizzabili. L'atto di mostrare questi dati al modello e di permettere a quest'ultimo di apprendere si chiama training (addestramento).
Durante il training, l'algoritmo di apprendimento cerca di imparare i pattern che legano i dati insieme partendo da certe ipotesi. Ad esempio, gli algoritmi probabilistici fondano il loro funzionamento proprio nel dedurre le probabilità che un evento accada in presenza di certi dati.
L'addestramento è controllato attraverso gli iperparametri, che ci permettono di regolare/tarare come il modello interpreta i dati e molto altro. Ogni modello ha i suoi iperparametri che variano in base alla logica di funzionamento (ce ne sono veramente tanti). Uno degli aspetti più importanti del lavoro di un data scientist è proprio trovare quali siano gli iperparametri giusti per un determinato modello. Spesso è una vera e propria ricerca che può durare anche molto tempo.
Una volta tarato il modello e addestrato, occorre calcolare le performance per comprendere se siamo soddisfatti o meno delle sue predizioni. Se lo siamo, la fase di training si considera conclusa e si procede con le seguenti fasi di sviluppo.
Un modello addestrato si comporta come qualsiasi altro software: riceve input e restituisce output. In input ci saranno i dati del fenomeno, in output invece le predizioni.
Tipi di apprendimento automatico
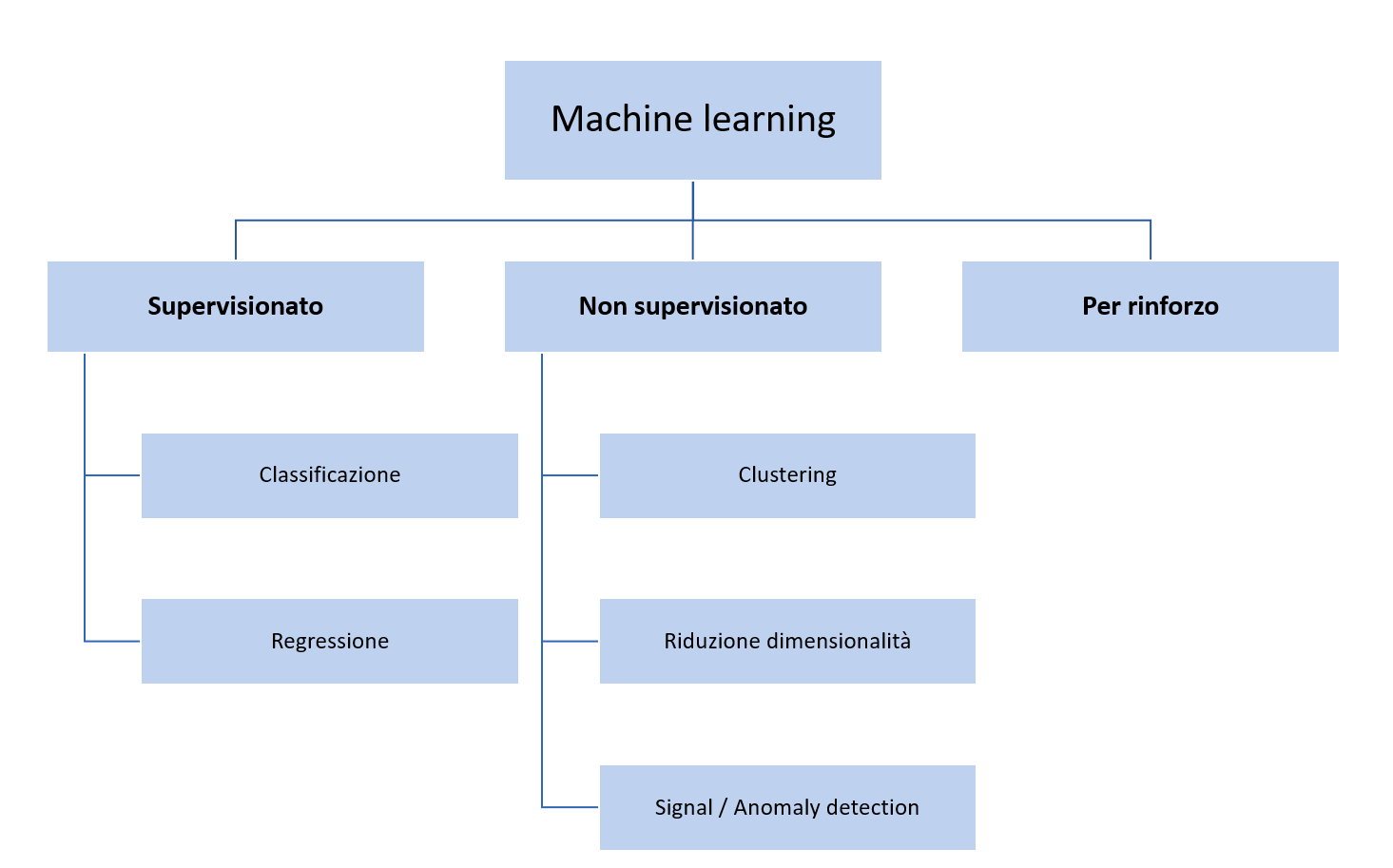
Il machine learning può essere diviso fondamentalmente in tre aree: apprendimento supervisionato, non supervisionato e per rinforzo. Vediamo come l'addestramento di questi algoritmi differisce proprio in base alla sottocategoria alla quale appartiene.
Apprendimento supervisionato
Gli algoritmi che si basano sull'apprendimento supervisionato hanno bisogno di essere addestrati su dati che al loro interno contengono la risposta esatta al problema, in modo tale da comprendere quale sia la relazione tra quest'ultima ed il fenomeno.
Ad esempio, un dataset per un task supervisionato potrebbe essere quello che contiene i dati di proprietà immobiliari e il loro prezzo. Se volessimo predire il prezzo di un immobile, l'algoritmo dovrebbe essere addestrato a comprendere l'associazione tra caratteristiche della casa, come numero di camere, metri calpestabili e altro e proprio il prezzo.
In gergo diciamo che le caratteristiche di un fenomeno facciano parte del feature set (denotato con , variabile aleatoria indipendente). La variabile da predire è la variabile dipendente (perché dipende dalle caratteristiche, per l'appunto), denotata tipicamente con .
Riassumiamo con una frase cosa è l'apprendimento supervisionato.
L'apprendimento supervisionato è una sottocategoria di apprendimento automatico che racchiude algoritmi che hanno bisogno di dati in forma X e y. X è l'insieme delle caratteristiche del fenomeno, y è l'osservazione che vogliamo predire.
Un algoritmo supervisionato apprende la relazione tra X e y ed è in grado di predire una nuova y data una X non appartenente al set di addestramento.
L'ultima parte della definizione potrebbe essere un po' complicata, quindi cerchiamo di capire meglio cosa si intende X non appartenente al set di addestramento.
L'obiettivo di un algoritmo di machine learning supervisionato è quello di predire qualcosa date delle caratteristiche di un fenomeno. Durante il training, un modello predittivo impara le relazioni tra queste e poi viene valutato.
Usando una metafora,
un modello predittivo non è che un bambino a scuola che studia per il suo piccolo test. Durante le esercitazioni (training), il bambino ha accesso alle risposte corrette ed è quindi in grado di perfezionare il suo apprendimento. Al test finale, il bambino sarà sottoposto a delle domande senza avere accesso alla soluzione corretta.
X (domande al test finale) non fa parte del set di addestramento (domande di esercitazione), e quindi il bambino (modello predittivo) dovrà trovare la soluzione (y) più precisa possibile in base all'apprendimento al quale è stato sottoposto.
Fanno parte dell'apprendimento supervisionato gli algoritmi di regressione (predizione di un valore numerico) e classificazione (predizione di una categoria).
Apprendimento non supervisionato
In questo caso i nostri algoritmi non necessitano di avere accesso alla risposta corretta nel nostro dataset, e quindi necessitano solo di un feature set X.
Com'è possibile? Beh perché la logica di questi algoritmi è completamente diversa. Non tutti i modelli di machine learning devono comportarsi come il bambino nella metafora. Infatti, gli algoritmi di apprendimento non supervisionato cercano di scoprire pattern nascosti nei dati per raggruppare, separare o manipolare i dati in qualche modo.
La bellezza di questi algoritmi è che non necessitano dell'intervento umano per fare il loro lavoro. Basta passare ad uno di questi i nostri dati e il gioco è fatto.
Fanno parte dell'apprendimento non supervisionato gli algoritmi di clustering (raggruppamento), anomaly e signal detection (identificazione di anomalie e di segnale) e quelli di riduzione della dimensionalità.
Ci sono anche algoritmi che funzionano in parte in maniera supervisionata e parte in maniera non supervisionata, ma questi sono tipicamente algoritmi ad-hoc creati da grandi aziende o da team molto grandi.
Apprendimento per rinforzo
L'apprendimento per rinforzo, chiamato anche reinforcement learning, viene spesso considerato un argomento ostico e separato dai due menzionati. In realtà il concetto è molto semplice: programmiamo un software, chiamato agente, per apprendere come completare un certo compito (task) in uno specifico ambiente e offriamo ricompense o punizioni in base a come performa.
La logica è di premiare l'agente quando raggiunge il risultato oppure punirlo quando fa qualcosa che lo allontana dal raggiungimento dello stesso. In maniera ciclica, il modello impara le regole per massimizzare la funzione di fitness, cioè quella funzione matematica che definisce la ricompensa, e minimizza l'errore, cioè la punizione. Questo permette un apprendimento simile a quello umano: quello basato sul trial and error.
Sentdex è un esponente del machine learning su YouTube. Consiglio altamente di seguire il suo canale e di guardare questa playlist dove programma un algoritmo di RF a giocare una partita di Starcraft II.
Un altro video particolarmente efficace a comunicare la potenza del reinforcement learning è questo
Esempi di applicazione del machine learning
Per consolidare la nostra interpretazione di cosa sia il machine learning, vediamo alcuni esempi pratici di come viene usato nella vita di tutti i giorni. Ognuno di questi casi d'uso è stato messo in atto da un team di data science, e se scegliete di lavorare nel campo anche voi potreste lavorare su progetti del genere!
Identificazione anomalie
Avete presente quando una banca nota una transazione anomala e vi chiede il permesso più volte per essere sicuri che siete voi effettivamente ad autorizzarla? Ecco. Dietro questi meccanismi ci sono algoritmi di anomaly detection che utilizzando i dati comportamentali riescono a cogliere comportamenti che divergono da quelli usuali. Estremamente utili per bloccare una transazione non autorizzata nel contesto bancario, altrettanto utile durante il monitoraggio di fenomeni naturali, come con i terremoti e uragani.
Classificazione di immagini e di testi
VI siete mai chiesti come fa l'iPhone a sfruttare il nostro volto per funzionalità come FaceID? Anche se non è l'unico meccanismo coinvolto, Apple utilizza il machine learning per classificare le immagini che provengono dalla nostra fotocamera. In questo caso, la classificazione è binaria: presenza o meno di un volto riconosciuto nell'immagine.
Gmail ha uno degli algoritmi anti-spam più famosi. Basta aprire il nostro account email e vedere la casella dello spam piena di email dannose. Come fa Google a sapere che una email è potenzialmente dannosa e piazzarla nella casella spam senza il nostro intervento? Attraverso algoritmi di machine learning precisamente addestrati e tarati per classificare il contenuto testuale delle nostre email.
Come già menzionato, le performance non di un modello non devono essere perfette per fornire valore concreto agli utenti. Infatti a volte potremmo trovarci a dover piazzare manualmente delle email spam nella casella appropriata.
Previsione dei prezzi
Il machine learning permette di prevedere valori numerici, come il prezzo di qualcosa. Potrebbe sembrare una magia, ma nel settore immobiliare le aziende utilizzano algoritmi di machine learning per prevedere il prezzo di immobili e di conseguenza affinare le strategie di compravendita e ottenere un vantaggio competitivo.
Contenuti e UX personalizzata
Alcuni siti web come Amazon tracciano i nostri comportamenti di acquisto e di interazione. Questo permette loro di addestrare modello di machine learning in grado di comprendere cosa vogliamo comprare e mettere davanti a noi quelle possibili scelte.
Amazon infatti ci propone spesso prodotti che "potrebbero piacerci" in base ad algoritmi di raccomandazione e di clustering. Implementare soluzioni del genere non è semplice ma offrire una esperienza del genere ai nostri clienti potrebbe veramente fare la differenza.
Condivido qui un video che elenca altre applicazioni del machine learning
Esempi pratici di machine learning in vari settori
Machine learning nel settore sanitario
Il machine learning sta rivoluzionando il settore sanitario, migliorando l'accuratezza diagnostica, personalizzando i trattamenti e ottimizzando le operazioni mediche - è particolarmente efficace nell’analisi di immagini mediche, come radiografie, risonanze magnetiche e TAC. Grazie agli algoritmi di deep learning, i sistemi possono rilevare in modo accurato lesioni o anomalie, individuando precocemente patologie come tumori, polmoniti e malattie degenerative.
Algoritmi di machine learning vengono anche utilizzati per prevedere gli esiti di specifici trattamenti medici. Analizzando i dati clinici, come la storia medica del paziente, questi modelli possono stimare la probabilità di successo di una terapia, permettendo ai medici di scegliere il trattamento più efficace. In oncologia, ad esempio, modelli predittivi aiutano a pianificare terapie personalizzate per aumentare la sopravvivenza e ridurre gli effetti collaterali.
Machine Learning nel marketing e nell'e-commerce
Il machine learning ha trasformato profondamente il marketing e l’e-commerce - basti vedere come Amazon e Google offrono raccomandazioni altamente mirate all'utente e alla sua attività. Ecco alcuni esempi pratici di come viene utilizzato in questi settori:
Sistemi di raccomandazione
Una delle applicazioni più comuni del machine learning nel commercio online è rappresentata dai sistemi di raccomandazione personalizzata. Piattaforme come Amazon, Netflix e Spotify analizzano le preferenze e i comportamenti di acquisto o visualizzazione dei loro utenti, proponendo prodotti, film o brani musicali su misura. Questi algoritmi migliorano l’esperienza dell’utente, aumentando al contempo le probabilità di acquisto o interazione.
Segmentazione avanzata dei clienti
Nel marketing, il machine learning è fondamentale per segmentare i clienti in base ai loro comportamenti e interessi. Grazie all’analisi di dati demografici, interazioni sui social media e pattern di navigazione, gli algoritmi sono in grado di suddividere i clienti in gruppi mirati attraverso il clustering, permettendo alle aziende di inviare messaggi e offerte personalizzate. Ad esempio, un'azienda di abbigliamento può distinguere tra chi è interessato alla moda sportiva e chi preferisce abiti formali, inviando comunicazioni ad hoc a ciascun gruppo.
Se vuoi leggere di più sul clustering, clicca qui 👇
Andrea D’Agostino
Analisi del sentiment online
Il machine learning viene utilizzato per l'analisi del sentiment, ossia per interpretare il tono e l’umore dietro recensioni, commenti e interazioni online. Gli algoritmi possono identificare sentimenti positivi, negativi o neutri nei contenuti, permettendo alle aziende di valutare la percezione del marchio e rispondere tempestivamente a eventuali critiche. Ad esempio, una campagna pubblicitaria che riceve feedback negativi può essere immediatamente ottimizzata.
Ottimizzazione delle ads
Il machine learning rende più efficiente la pubblicità online, permettendo di impostare campagne mirate con maggiore precisione. Gli algoritmi analizzano i dati degli utenti e ottimizzano i budget pubblicitari in tempo reale, scegliendo dove e quando mostrare gli annunci per massimizzare le conversioni. Grazie a modelli predittivi, Google Ads e Facebook Ads possono personalizzare gli annunci, proponendoli solo agli utenti più propensi all’acquisto.
Machine learning nell’Industria finanziaria
Nel settore finanziario, il machine learning ha assunto un ruolo di primo piano, rendendo le operazioni più sicure, ottimizzando i processi e migliorando l'accuratezza delle previsioni. Ecco alcuni esempi concreti di come il machine learning viene applicato in questo campo:
Rilevamento delle Frodi
La rilevazione delle frodi è una delle applicazioni più rilevanti del machine learning in ambito finanziario. Gli algoritmi analizzano migliaia di transazioni in tempo reale, cercando modelli anomali che possono indicare attività fraudolente. Ad esempio, un acquisto improvviso di alto valore in un paese diverso rispetto a quello dell'utente può essere segnalato come sospetto. Questi sistemi di monitoraggio basati sul machine learning si adattano continuamente a nuovi tipi di frode, migliorando costantemente la loro accuratezza.
Valutazione del Credito
Anche la valutazione del rischio di credito è stata trasformata dal machine learning. Tradizionalmente, le banche utilizzavano parametri standard come il reddito e la cronologia creditizia per valutare l’affidabilità di un cliente. Oggi, invece, algoritmi avanzati considerano un numero molto maggiore di variabili, come le abitudini di spesa, la stabilità occupazionale e le relazioni finanziarie. Questo metodo consente di prevedere con maggiore accuratezza la probabilità di insolvenza e di estendere il credito anche a clienti che in passato sarebbero stati esclusi.
Come si lavora nel campo del machine learning?
Per lavorare nel campo del machine learning occorre avere conoscenze di informatica, matematica e statistica. Tanto più specifiche sono queste conoscenze, tanto più saranno le nostre possibilità di trovare un lavoro ben pagato e soddisfacente. Infatti, il data scientist, che è la figura principale che è coinvolta in questo campo, lavora proprio all'intersezione di queste tre discipline.
Ecco una checklist pratica:
- Matematica e Statistica: Una solida base in algebra lineare, calcolo e probabilità è essenziale per comprendere il funzionamento degli algoritmi di ML.
- Programmazione: Conoscere linguaggi come Python (spesso usato per machine learning) o R è cruciale per implementare modelli. Familiarizzare con librerie come Scikit-learn, TensorFlow e PyTorch consente di applicare tecniche di machine learning in modo pratico.
- Gestione dei dati: Sapere come raccogliere, pulire e manipolare i dati è fondamentale, data l’importanza di dataset accurati. Librerie come Pandas e SQL sono utili per questa fase.
- Concetti di Machine Learning: Approfondire le tipologie di apprendimento (supervisionato, non supervisionato, e di rinforzo) e i principali algoritmi per comprendere le basi del ML.
Un data scientist fa il suo lavoro principalmente scrivendo codice, solitamente in Python o R. Per questo motivo deve possedere buone conoscenze di logiche di sviluppo software, strutture dati e algoritmi.
Le aree della matematica più importanti sono sicuramente quelle dell'algebra lineare, che permette al data scientist di sfruttare le proprietà e operazioni su matrici, dell'analisi matematica, con lo studio di funzione e della loro ottimizzazione e del calcolo della probabilità.
Può sembrare molto complesso essere un data scientist, ma avere conoscenza specifica dell'industria dove si vuole lavorare è ancora più importante.
Infatti non serve conoscere a menadito tutte le nozioni delle aree menzionate, ma basta conoscere le basi e aiutare l'azienda o il cliente a cogliere le opportunità più redditizie nel settore dove opera.
Esistono oggi corsi di studi universitari che preparano giovani studenti a lavorare nel settore del data science. I loro curriculum sono variegati, ma tutti coprono le queste discipline.
Per gli autodidatti invece, esistono corsi online estremamente validi per iniziare e consolidare le conoscenze necessarie per lavorare nel settore.
A tema machine learning puro, Coursera offre i corsi più impattevoli sulla carriera di un giovane studente che vuole iniziare il percorso. Non posso non condividere il corso di Andrew Ng su Coursera di introduzione al machine learning. È sicuramente una delle prime tappe da smarcare prima di intraprendere il viaggio profondo nel mondo dei dati.





Commenti dalla community