
Creare un dataset è una delle prime e più importanti fasi di un progetto di data analytics e machine learning. Come ho già parlato nel mio articolo dove spiego dell'importanza di creare un dataset partendo da zero, qui mi concentro sul condividere con voi lettori una metodica semplice ed efficace per popolare un corpus di dati testuali usando come sorgente dati dei blog online.
La motivazione da parte mia che mi ha convinto a scrivere questo pezzo è che il dato di tipo testuale è sicuramente il più prevalente nel mondo online ed è sicuramente una competenza valida quella di poter attingere a questa pool di dati. In questo vi condividerò come.
Voglio sottolineare la metodica qui presente non è invasiva e in generale non dovrebbe esserci il rischio (se non modificate il codice, ovviamente) di incorrere in penalità.
Ricordatevi di scraperare sempre responsabilmente. Se un sito web dichiara nero su bianco che non vuole essere scraperato, non fatelo. Inoltre, questa metodica è indicata per recuperare articoli presenti nell'HTML - questo significa che se il contenuto è generato via Javascript allora questo non sarà recuperabile. In questo caso bisogna emulare un browser con uno strumento come Playwright o Selenium.
Iniziamo.
Come funziona il software?
Il primo step è quello di recuperare i link dal nostro sito target in modo da poter inviare delle richieste a quei link e recuperare il corpo dell'articolo. Il flusso di dati può essere immaginato così:
- Recuperiamo la lista di URL che vogliamo scraperare
- Per ogni URL facciamo una richiesta GET per recuperare il corpo dell'articolo dall'HTML
- Salviamo il dato in un dizionario Python con due chiavi, URL e articolo
- Salviamo il dizionario in una lista
- Trasformiamo la lista in un dataframe Pandas
Andiamo subito nel punto 1.
Come recuperare una lista di URL che vogliamo scraperare
Per trovare la lista di URL useremo la sitemap.xml, un file presente nella maggior parte dei siti web (gli editoriali ne hanno veramente bisogno dal punto di vista SEO) che ha l'obiettivo di indicare ai motori di ricerca il contenuto del nostro sito web, frequenza di aggiornamento e categorie. Essa spesso si trova in www.sitoweb.it/sitemap.xml. Se così non fosse, possiamo usare il file robots.txt, solitamente allo stesso indirizzo web, che ci indicherà la posizione della sitemap.
Raggiungendo la sitemap vediamo che si presenta così
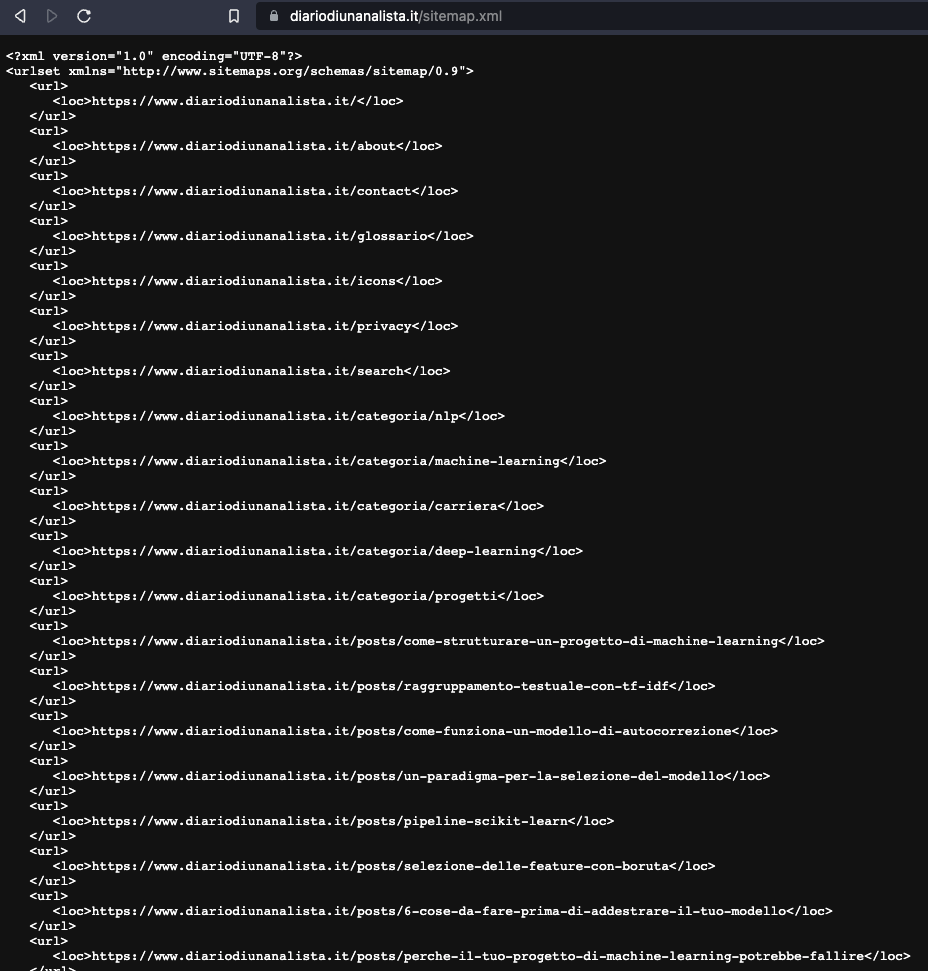
Quello che vediamo è un file in formato .xml (extensible markup language) che in una gerarchia ad albero comunica con le sue foglie le specifiche di un dato elemento. Ad esempio, il nodo di una URL è tipicamente il nodo loc. Questo è quello più importante perché comunica ai motori di ricerca proprio l'inserimento di nuove URL nel nostro sito.
Va anche specificato che spesso esiste un file chiamato sitemap_index.xml, che invece di puntare alle URL dei singoli articoli / pagine, contiene una lista di altre sitemap che a loro volta puntano a URL specifiche. Ad esempio, potrebbe esserci una sitemap dedicata alle pagine statiche, una alle categorie e una ai post.
Perché partire dalla sitemap?
È una domanda legittima. Essenzialmente abbiamo due strade:
- Atterriamo con il nostro scraper sulla homepage e seguiamo tutte le URL interne al sito (quelle che puntano a risorse / pagine nello stesso sito)
- Sfruttiamo la sitemap che già contiene le URL rilevanti.
La 2. sicuramente sembra la più efficace. Ci sono tuttavia alcuni punti da tenere a mente: nella sitemap potrebbero non esserci tutti gli articoli che in realtà esistono sul sito.
Ricordiamoci che la sitemap è un file controllato dal proprietario del sito web e lui può decidere se rendere una URL pubblica nella sitemap o meno (ci sono anche altre impostazioni che rendono una pagina su un sito irraggiungibile per un motore di ricerca, la sitemap non è una di queste).
Per la maggior parte dei casi, una sitemap di un blog sarà sufficiente per permetterci di creare un corpus di dati testuali per le nostre analisi.
Gli strumenti
Useremo una libreria chiamata Trafilatura sia per recuperare le URL dalla sitemap che per raccogliere i nostri articoli. Questa è una potente libreria che serve a diverse cose, tra le quali localizzare una sitemap all'interno di un sito senza doverla esplicitamente dichiarare, seguire ogni link interno per mappare il sito (qualora la sitemap non fosse disponibile), scaricare ed estrarre il contenuto di una pagina. Trafilatura fa questo e altro e vi consiglio di leggere la documentazione per scoprire tutte le sue potenzialità.
Ad accompagnare Trafilatura c'è Pandas - i dati raccolti verranno inseriti in un DataFrame per un facile utilizzo.
Come optional c'è PyMongo, nel caso volessimo salvare i nostri dati in un database non relazionale.
L'algoritmo
Iniziamo a scrivere del codice.
from trafilatura.sitemaps import sitemap_search
def get_urls_from_sitemap(resource_url: str) -> list:
"""
Questa funzione recupera una lista di URL da una sitemap con Trafilatura
"""
urls = sitemap_search(resource_url)
return urlsImportiamo sitemap_search da Trafilatura e scriviamo una funzione che data una URL base di un sito web (come la homepage ad esempio) essa restituisca tutte le URL presenti in sitemap.
Avendo tutte le URL presenti in sitemap per un sito, possiamo ora iniziare a creare il nostro dataset. Trafilatura scarica e estrae i testi così
from trafilatura import fetch_url, extract
def extract_article(url: str) -> dict:
"""
Estrae un articolo da una URL con Trafilatura
"""
downloaded = fetch_url(url)
article = extract(downloaded, favor_precision=True)
return articleCon favor_precision=True chiediamo alla libreria di usare metodi più stringenti per quanto riguarda l'identificazione del corpo centrale dell'articolo. Poiché essa applica delle euristiche, a volte è può sbagliarsi e tirar dentro del contenuto non appartenente a quello centrale, ad esempio intestazioni presenti nella sidebar. Con l'argomento favor_precision chiediamo una maggiore precisione a scapito di tempi di elaborazione un pochino più lunghi.
Ora mettiamo tutto insieme in una funzione che chiameremo create_dataset(). Questa funzione riceve come argomento una lista di siti web dalla quale vogliamo prendere gli articoli. Useremo https://www.diariodiunanalista.it e https://fragrancejourney.it, che è un piccolo blog italiano nella nicchia delle profumazioni.
import pandas as pd
from tqdm import tqdm
import time
def create_dataset(list_of_websites: list) -> pd.DataFrame:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
data = []
# usiamo tqdm per creare una progress bar
for website in tqdm(list_of_websites, desc="Websites"):
# popoliamo urls con tutte le URL del sito web usando la funzione precedente
urls = get_urls_from_sitemap(website)
# creiamo un dizionario python che diventerà poi il nostro dataframe
for url in tqdm(urls, desc="URLs"):
d = {
'url': url,
"article": extract_article(url)
}
data.append(d)
# ricordiamoci di rispettare il sito web! Non spammiamo
time.sleep(0.5)
df = pd.DataFrame(data)
# rimuoviamo duplicati se esitono
df = df.drop_duplicates()
# rimuoviamo righe vuote se esistono
df = df.dropna()
return dfHo inserito un time.sleep(0.5) così da non pesare eccessivamente sul server del sito web. Provate ad alzare questo timer se incorrete in errori di timeout o simili.
Lanciamo la funzione e vedremo il nostro corpus costruirsi piano piano. La durata del processo dipende da quanti articoli vogliamo recuperare.
Esportiamo il nostro dataset in formato .csv e abbiamo finito! Abbiamo un corpus di dati testuali pronto per essere sottoposto a pre-processing e ad analisi.
I risultati
Diamo una occhiata al nostro dataset
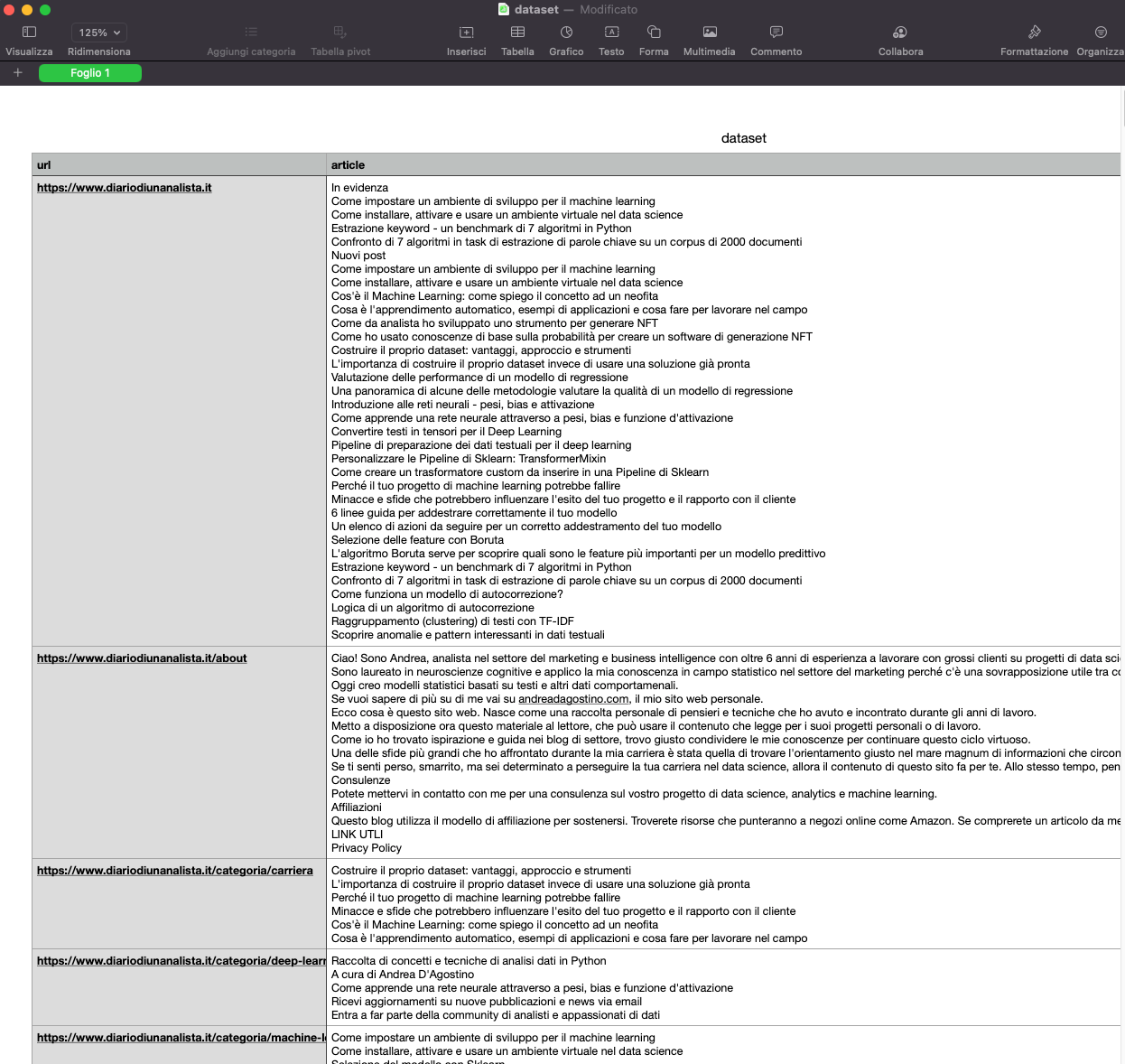
Ora è possibile applicare diverse metodiche analitiche su questo corpus. Sicuramente dovrà essere sottoposto a pre-processing, come rimozioni delle stopword, dei caratteri speciali e della trasformazione in lemmi.
Una applicazione diretta può essere di fare clustering con TF-IDF sui nostri testi. Tutto dipende dal nostro obiettivo. La creatività è il nostro unico limite.
Template del codice
Ecco il codice completo in formato copia-incolla
import time
import pandas as pd
from tqdm import tqdm
from trafilatura.sitemaps import sitemap_search
from trafilatura import fetch_url, extract
def get_urls_from_sitemap(resource_url: str) -> list:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
urls = sitemap_search(resource_url)
return urls
def extract_article(url: str) -> dict:
"""
Estrae un articolo da una URL con Trafilatura
"""
downloaded = fetch_url(url)
article = extract(downloaded, favor_precision=True)
return article
def create_dataset(list_of_websites: list) -> pd.DataFrame:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
data = []
for website in tqdm(list_of_websites, desc="Websites"):
urls = get_urls_from_sitemap(website)
for url in tqdm(urls, desc="URLs"):
d = {
'url': url,
"article": extract_article(url)
}
data.append(d)
time.sleep(0.5)
df = pd.DataFrame(data)
df = df.drop_duplicates()
df = df.dropna()
return df
if __name__ == "__main__":
list_of_websites = [
"https://www.diariodiunanalista.it/",
"https://www.fragrancejourney.it/"
]
df = create_dataset(list_of_websites)
df.to_csv("dataset.csv", index=False)





Commenti dalla community