
Il carcinoma della pelle si configura come la forma di neoplasia maligna più comune nell'uomo, spesso diagnosticato mediante osservazione visiva e screening clinico iniziale, seguiti da eventuali analisi dermoscopiche, biopsie ed esami istopatologici.
L'automazione della classificazione delle lesioni cutanee attraverso l'analisi di immagini rappresenta una sfida significativa, data la complessità e la variabilità nell'aspetto delle lesioni.
Il dataset utilizzato in questo contesto proviene dall'archivio ISIC (https://www.kaggle.com/datasets/drscarlat/melanoma) e comprende 8903 immagini di nei benigni e 8902 immagini di nei classificati come maligni. Tutte le immagini sono state uniformemente ridimensionate in formato RGB a bassa risoluzione. L'obiettivo di questo kernel è sviluppare un modello in grado di effettuare una classificazione visiva di un nevo come benigno o maligno.
Le due classi di cancro della pelle oggetto di rilevamento sono:
- Benigno
- Maligno
In questo kernel, sarà implementata una rete neurale convoluzionale utilizzando Keras con TensorFlow come backend. Successivamente, verrà condotta un'analisi dei risultati al fine di valutare l'utilità pratica del modello nell'identificazione di lesioni cutanee.
TensorFlow è una libreria software open-source per l'apprendimento automatico, sviluppata da Google Brain Team. È utilizzata per implementare algoritmi di reti neurali, sia per scopi di ricerca che per applicazioni pratiche.
TensorFlow offre un'ampia gamma di strumenti e risorse che permettono di costruire e addestrare modelli di machine learning complessi. In questo articolo esploreremo il processo di creazione di un modello di classificazione binaria utilizzando TensorFlow. L'obiettivo sarà distinguere melanoma benigno e melanoma maligno nelle immagini, prendendo ispirazione da un noto dataset su Kaggle.
- Scaricare e decomprimere un dataset dal web
- Assemblare un modello di classificazione incorporando livelli di convoluzione e max pooling
- Implementare un ImageDataGenerator per ottimizzare la gestione delle immagini durante le fasi di training e validazione
- Compilare e allenare il modello
- Esaminare le modifiche effettuate alle immagini attraverso i vari strati della rete neurale
- Effettuare previsioni su immagini inedite
Affronteremo queste sfide tenendo presente che il deep learning richiede risorse computazionali significative. Per questo, sfrutteremo Google Colab, impostando il runtime su GPU, per gestire efficientemente i calcoli necessari.
L'indirizzo pubblico del dataset è questo


e fa riferimento al relativo progetto sulla banca dati di Harvard.
Se ti interessa fare un ripasso di come funziona TensorFlow o vuoi muovere i tuoi primi passi con la libreria di Google, segui questo link
 Andrea D’Agostino
Andrea D’Agostino
Informazioni sul set di dati
Il set di dati originale è costituito dalle immagini HAM10k, acronimo di "Human Against Machine with 10,000 images," disponibile gratuitamente. Le immagini dermoscopiche all'interno del set di dati HAM10k sono state curate e normalizzate in termini di luminosità, colori, risoluzione, eccetera. La diagnosi effettiva è stata convalidata tramite istopatologia (come fonte di verità) in oltre il 50% dei casi, rappresentando il doppio rispetto ai set di dati precedenti sulle lesioni cutanee. Per le restanti lesioni, la diagnosi è stata basata sul consenso dei dermatologi.
Invece di affrontare la classificazione di sette tipi di lesioni cutanee in un insieme fortemente sbilanciato, si è semplificato il compito concentrandosi sulla diagnosi di melanoma rispetto a non melanoma. Riassumendo le categorie sopra menzionate in due gruppi, il risultato è comunque un set di dati sbilanciato con:
- 1113 immagini di melanoma
- 8902 immagini di non melanoma
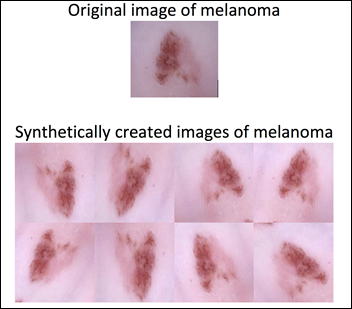
Per affrontare questo squilibrio, è stato applicato l'aumento dei dati al gruppo di melanoma, portando il numero di immagini in modo che fosse simile al gruppo di non melanoma.
L'aumento dei dati consente di esporre il modello a varie modifiche di un'immagine di melanoma. Ciò, a sua volta, permette al modello di apprendere e successivamente generalizzare, ad esempio, che un melanoma che punta a sinistra è comunque un melanoma se punta a destra. Il risultato è un set di dati bilanciato di 17805 immagini dopo l'aumento dei dati nel gruppo di melanoma:
- 8903 immagini di melanoma
- 8902 immagini di non melanoma
Ulteriori dettagli sul processo di potenziamento possono essere trovati sulla pagina Kaggle dedicata al dataset.
Breve introduzione alle convoluzioni e max pooling
Le convoluzioni e il max pooling sono tecniche di elaborazione delle immagini fondamentali per i modelli di computer vision, specialmente nelle reti neurali convoluzionali (CNNs). Questi strumenti aiutano il modello a catturare e enfatizzare le caratteristiche salienti delle immagini, facilitando l'apprendimento di pattern complessi.
Convoluzione: Questo processo coinvolge l'applicazione di un filtro, o kernel, che passa attraverso l'immagine. Immaginate ogni pixel di un'immagine come una cellula in un vasto tessuto di informazioni visive. Un filtro convoluzionale esamina una cellula (pixel) insieme alle sue vicine immediate, calcolando un nuovo valore per la cellula centrale. Questo si ottiene attraverso una griglia, tipicamente di dimensione 3x3, che pesa il valore di ogni pixel e i suoi vicini secondo i valori specificati nel filtro. Il risultato è una trasformazione del pixel centrale che riflette non solo la sua intensità originale ma anche la relazione spaziale con i suoi vicini. Questo processo di filtraggio evidenzia i pattern locali, come bordi o angoli, che sono essenziali per la comprensione visiva.
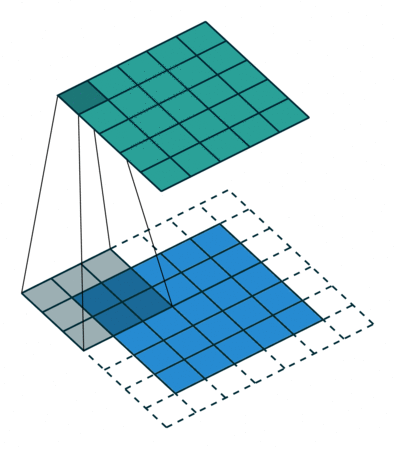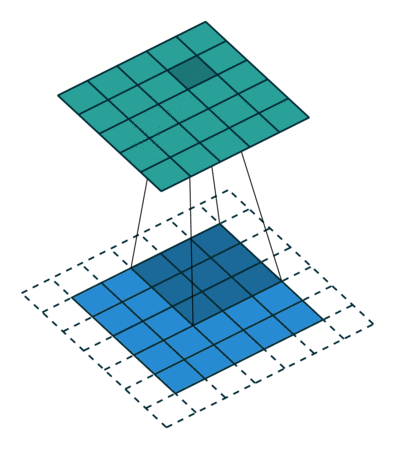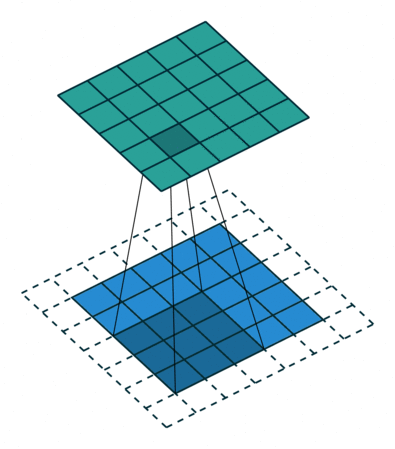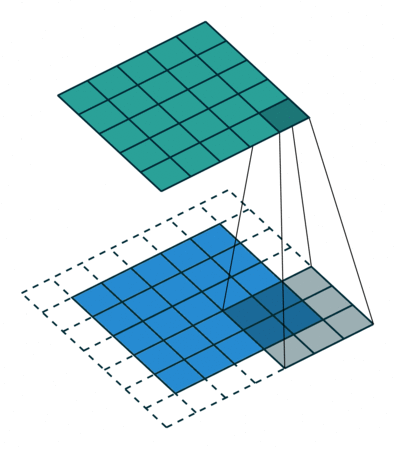
La procedura di convoluzione in elaborazione delle immagini si basa sull'uso di un particolare array, noto come kernel o filtro. Questo kernel, solitamente più piccolo dell'immagine da elaborare, viene fatto scorrere su tutta l'immagine.
Un esempio tipico è un kernel di dimensione 3x3 che si muove su un'immagine 5x5. Durante questo processo, ogni elemento dell'immagine viene combinato con il kernel, producendo una nuova immagine, chiamata mappa delle caratteristiche (o feature map), che qui è illustrata come una matrice 5x5 di colore verde.
Un dettaglio importante in questo processo è il cosiddetto padding, che è l'aggiunta di bordi extra (qui mostrati in bianco) attorno all'immagine originale. Il padding è usato per mantenere le dimensioni desiderate nell'immagine di output (nella nostra esemplificazione, una matrice 5x5). Senza il padding, l'immagine risultante sarebbe ridotta nelle sue dimensioni (nel nostro caso, a 3x3).
Il padding non è solo una soluzione tecnica per conservare le dimensioni, ma aiuta anche a preservare le informazioni ai bordi dell'immagine, che altrimenti potrebbero essere perse nei livelli successivi di elaborazione.
La concezione fondamentale di una convoluzione si focalizza sull'accentuare specifici attributi di un'immagine, per esempio esaltando i bordi e i contorni per renderli più distinti rispetto allo sfondo ecco un esempio.
Max Pooling: Dopo la convoluzione, spesso segue il pooling, che riduce le dimensioni dell'immagine mantenendo le caratteristiche più prominenti. Il max pooling, in particolare, scorre un filtro attraverso l'immagine e seleziona il valore massimo all'interno di una finestra di valori (ad esempio, all'interno di una griglia 2x2). Questo non solo riduce la complessità computazionale per le operazioni successive ma conserva anche le caratteristiche più rilevanti che sono state evidenziate dalla convoluzione.
Queste operazioni sono essenziali per permettere alle reti neurali di apprendere gerarchie di caratteristiche visive, da semplici texture e forme a oggetti complessi all'interno di immagini.
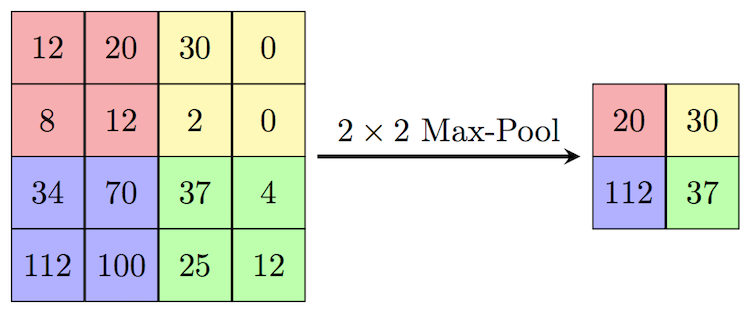
Creazione del modello
È cruciale notare che è fondamentale fornire al modello immagini con dimensioni uniformi. La scelta di queste dimensioni è arbitraria, e per questo specifico modello abbiamo optato per immagini ridimensionate a 150x150 pixel, rendendole così tutte quadrate.
Considerando che lavoriamo con immagini a colori, è essenziale incorporare questa informazione nella nostra progettazione. Pertanto, la forma di input sarà (150, 150, 3), dove il valore 3 rappresenta i tre canali di colore RGB. Successivamente, vedremo come garantire che tutte le nostre immagini siano conformi a questa dimensione quando sfruttiamo ImageDataGenerator.
Ora procediamo con l'implementazione dell'architettura della rete neurale.
Installiamo la libreria opendataset
Scarichiamo il dataset attraverso API di Kaggle. Documentazione per accedervi qui.
Ecco il codice per scrivere l'architettura del modello TensorFlow
import os
# importante rinominare path melanoma/DermMel/train_sep in :
# /content/melanoma/DermMel/train
current_path = '/content/melanoma/DermMel/train_sep'
new_path = '/content/melanoma/DermMel/train'
if not os.path.exists(new_path):
os.rename(current_path, new_path)
print(f"La cartella è stata rinominata da {current_path} a {new_path}")
else:
print(f"Il percorso di destinazione {new_path} esiste già. Non è necessario rinominare la cartella.")
# cartelle di apprendimento e validazione
base_dir = '/content/melanoma/DermMel'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'valid')
# puntiamo alle cartelle di Melanoma e NotMelanoma per il training
train_Melanoma_dir = os.path.join(train_dir, 'Melanoma')
train_NotMelanoma_dir = os.path.join(train_dir, 'NotMelanoma')
# puntiamo alle cartelle di Melanoma e NotMelanoma per la validazione
validation_Melanoma_dir = os.path.join(validation_dir, 'Melanoma')
validation_NotMelanoma_dir = os.path.join(validation_dir, 'NotMelanoma')
import tensorflow as tf
# Creiamo un modello sequenziale
model = tf.keras.models.Sequential([
# Primo strato di convoluzione con 16 filtri 3x3, attivazione ReLU e dimensione dell'input 150x150x3
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
# Strato di MaxPooling 2x2
tf.keras.layers.MaxPooling2D(2,2),
# Secondo strato di convoluzione con 32 filtri 3x3 e attivazione ReLU
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
# Altro strato di MaxPooling 2x2
tf.keras.layers.MaxPooling2D(2,2),
# Terzo strato di convoluzione con 64 filtri 3x3 e attivazione ReLU
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
# Ulteriore strato di MaxPooling 2x2
tf.keras.layers.MaxPooling2D(2,2),
# Appiattiamo il risultato per passarlo ad uno strato denso
tf.keras.layers.Flatten(),
# Strato denso con 512 neuroni e attivazione ReLU
tf.keras.layers.Dense(512, activation='relu'),
# Strato di output con un singolo neurone e attivazione sigmoide
tf.keras.layers.Dense(1, activation='sigmoid')
#output 0 benigno 1 maligno
])
# Visualizziamo una panoramica del modello
model.summary()All'esecuzione di questo codice, vedremo un riassunto con model.summary() che appare così
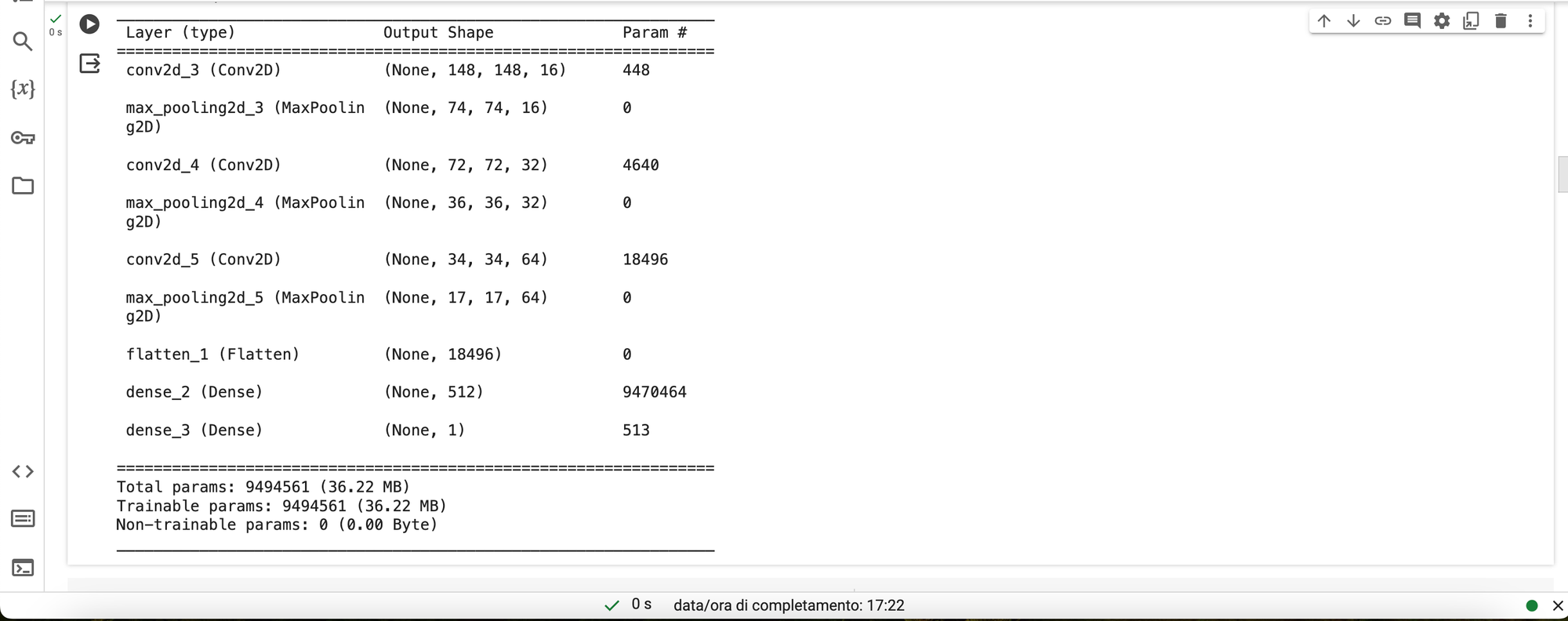
L'immagine in input è di dimensioni 150x150. La riduzione di 1 pixel su ciascun lato dell'immagine durante la convoluzione è dovuta all'utilizzo di un filtro (kernel) di dimensione 3x3. Questo filtro scorre sull'immagine con passi (stride) di default, solitamente 1 pixel alla volta, riducendo così la dimensione dell'output.
Per capire meglio, consideriamo il centro del filtro 3x3. Se immaginiamo questo filtro posizionato sull'immagine, noteremo che il suo centro coincide con un punto sull'immagine. Tuttavia, nei bordi dell'immagine, non c'è spazio sufficiente per posizionare completamente il filtro senza superare i bordi. Quindi, per mantenere la dimensione dell'output compatibile con l'input, perdiamo un pixel su ciascun lato.
Quanto al numero 64 nell'output shape, rappresenta il numero di filtri (o kernel) applicati. Ogni filtro estrae differenti caratteristiche dall'immagine. Quindi, in questo caso, abbiamo 64 filtri convoluzionali applicati all'immagine di input, ognuno dei quali produce un'immagine di output 148x148.
In breve, l'output shape 148x148x64 nel primo strato convoluzionale indica che stiamo ottenendo 64 diverse immagini di output (o feature maps), ciascuna di dimensioni 148x148, applicando filtri 3x3 all'immagine di input di dimensioni 150x150. Questo processo di convoluzione aiuta la rete a identificare e catturare diverse caratteristiche dell'immagine durante le fasi iniziali del processo di apprendimento.
Dopo l'applicazione della prima convoluzione, osserviamo la successiva riduzione delle dimensioni dell'immagine attraverso uno strato di max pooling, che dimezza la sua dimensione. Questo processo continua iterativamente fino a raggiungere lo strato di flatten, il quale prende l'output a quel punto e lo trasforma in un singolo vettore.
Successivamente, questo vettore viene passato attraverso uno strato denso composto da 512 neuroni. Infine, la rete termina con un singolo neurone di output, che produce un valore binario: 0 o 1 (benigno o maligno).
In questo caso, stiamo utilizzando l'ottimizzatore Adam, una funzione di loss di crossentropia binaria e l'accuratezza come metrica di performance.
Compiliamo il modello in questo modo
# Compilazione del modello
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
La funzione di perdita binaria o "binary_crossentropy" è una metrica comune utilizzata nei problemi di classificazione binaria, in cui l'obiettivo è predire se un'istanza appartiene a una delle due classi, di solito etichettate come 0 e 1 (benigno maligno). Questa funzione di perdita è particolarmente adatta per i modelli di machine learning che utilizzano l'output sigmoideo.
Ecco una breve spiegazione dei principali concetti di "binary_crossentropy"
- Problema di Classificazione Binaria: La binary crossentropy è specificamente progettata per problemi di classificazione binaria, in cui ogni esempio di addestramento può appartenere solo a una delle due classi
- Modello Sigmoideo: La binary crossentropy è spesso associata a modelli che utilizzano la funzione di attivazione sigmoidea nell'ultimo strato. La funzione sigmoidea comprime i valori in un intervallo tra 0 e 1, producendo probabilità che possono essere interpretate come la probabilità che un'istanza appartenga alla classe positiva (1)
- Calcolo della Perdita: La binary crossentropy misura la discrepanza tra la distribuzione di probabilità prevista dal modello e la distribuzione di probabilità reale dei dati di addestramento. Per un singolo esempio, la formula della binary crossentropy è:
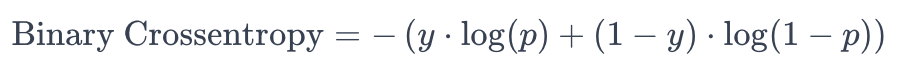
dove:
- \( y \) è l'etichetta reale (0 o 1)
- \( p \) è la probabilità prevista dal modello che l'esempio appartenga alla classe 1
- Ottimizzazione: L'obiettivo durante l'addestramento del modello è minimizzare la binary crossentropy. Questo viene fatto aggiustando i pesi della rete neurale utilizzando tecniche di ottimizzazione come l'algoritmo di ottimizzazione Adam
- Interpretazione: Un valore basso di binary crossentropy indica che le previsioni del modello sono vicine alle etichette reali, mentre un valore alto indica una discrepanza significativa. L'obiettivo è ridurre la perdita durante l'addestramento, migliorando così la capacità del modello di fare previsioni accurate.
In sintesi, la binary crossentropy è una misura della discrepanza tra le previsioni del modello e le etichette reali in problemi di classificazione binaria. Riducendo questa perdita durante l'addestramento, si migliora la capacità del modello di fare previsioni precise.
Preprocessing delle Immagini con ImageDataGenerator in TensorFlow
La fase successiva del processo coinvolge il preprocessing delle immagini per garantire la loro idoneità al modello. Le immagini saranno ridimensionate in modo uniforme, convertite in formato float64 e associate alle rispettive etichette (cioè, "benigno" o "maligno"). Successivamente, queste informazioni verranno fornite al modello.
Saranno creati due generatori distinti: uno dedicato all'addestramento e l'altro alla validazione. Ciascun generatore effettuerà la conversione delle immagini in valori numerici normalizzati nell'intervallo compreso tra 0 e 255. Considerando che 255 rappresenta il massimo valore di intensità di un pixel, questo processo comporterà che un pixel con intensità massima di 255 diventerà 1, mentre un pixel "spento" sarà rappresentato da 0. I valori intermedi saranno opportunamente scalati tra 0 e 1.
In TensorFlow, l'utilizzo di ImageDataGenerator semplifica notevolmente queste operazioni. La sua potenza risiede nella capacità di generare automaticamente le etichette per le immagini, basandosi sulla struttura gerarchica e sulla nomenclatura delle cartelle contenenti le immagini.
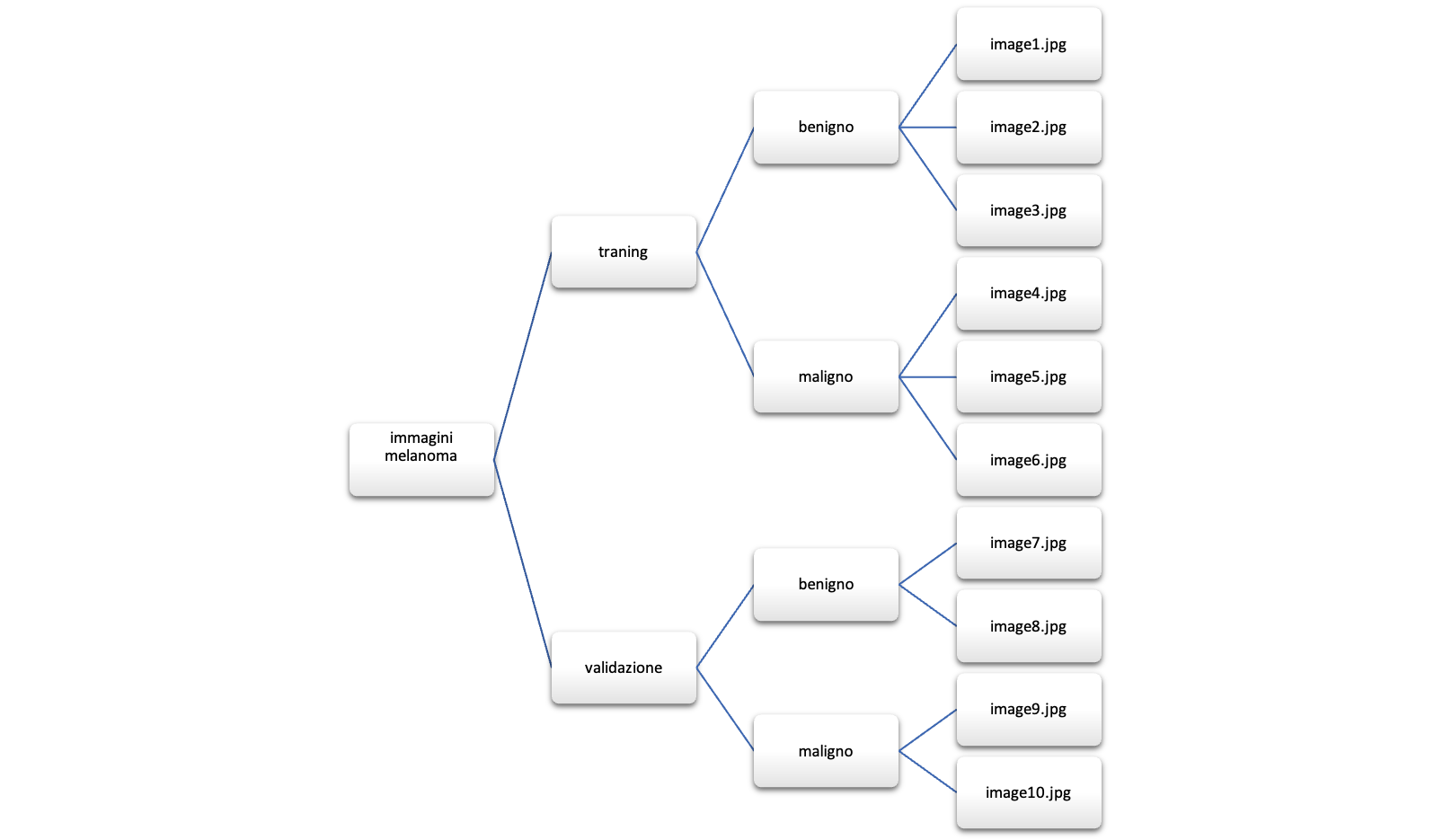
In sintesi, l'intero processo di preprocessing delle immagini si basa su una standardizzazione delle dimensioni, la conversione dei pixel in formato float64 e la normalizzazione dei valori pixel nell'intervallo [0, 1]. ImageDataGenerator svolge un ruolo fondamentale, semplificando ulteriormente il processo grazie alla sua capacità di generare etichette in modo automatico, considerando la struttura delle seguenti cartelle.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# riscaliamo tutte le nostre immagini con il parametro rescale
train_datagen = ImageDataGenerator(rescale = 1.0/255)
test_datagen = ImageDataGenerator(rescale = 1.0/255)
# utilizziamo flow_from_directory per creare un generatore per il training
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
# utilizziamo flow_from_directory per creare un generatore per la validazione
validation_generator = test_datagen.flow_from_directory(
validation_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150)
)Il Viaggio dell'Addestramento: 15 Epoche di Apprendimento Profondo
L'avvincente fase di addestramento del nostro modello ha inizio, con l'obiettivo di plasmare le sue abilità predittive. Questo processo coinvolge 334 steps per epoca, basati sul batch size del nostro generatore di addestramento. Nel corso di 15 epoche, il modello assorbirà le informazioni dal set di 8903 immagini, affinando le sue capacità predittive.
Il codice di addestramento si configura nel seguente modo:
history = model.fit(
train_generator, # Generatore per il training
steps_per_epoch=334, # Numero di steps per epoca basato sul batch size
epochs=15, # Numero di epoche
validation_data=validation_generator, # Generatore per la validazione
validation_steps=111, # Numero di steps per epoca di validazione basato sul batch size
verbose=2 # Livello di verbosità
)
Esplorare le Rappresentazioni Neurali attraverso la Visualizzazione
Un aspetto affascinante nell'analisi delle reti neurali convoluzionali (CNN) è l'osservazione delle informazioni chiave estratte dalle immagini e delle rappresentazioni generate durante il passaggio attraverso i differenti strati della rete. In questo contesto, useremo un modello fornito da Keras per esplorare questo processo, fornendo all'architettura neurale input precedentemente utilizzati per l'addestramento.
L'analisi delle rappresentazioni neurali offre una finestra privilegiata sull'elaborazione delle informazioni all'interno della rete. Ogni strato di una CNN svolge un ruolo specifico nell'identificare pattern e caratteristiche distintive. Possiamo osservare come l'immagine di input viene trasformata e rappresentata in maniera più astratta via via che attraversa i vari strati della rete.
Questo processo di estrazione di feature è fondamentale nel comprendere come una CNN interpreta e categorizza le informazioni visive. Ad esempio, le prime layers possono essere specializzate nel riconoscere bordi e dettagli di basso livello, mentre le layers più profonde catturano feature complesse e astratte come forme e pattern specifici.
Per esplorare ulteriormente le rappresentazioni neurali, possiamo utilizzare tecniche di visualizzazione come mappe di attivazione e filtri convoluzionali. Le mappe di attivazione evidenziano le regioni dell'immagine che hanno contribuito maggiormente all'attivazione di specifici neuroni, mentre i filtri convoluzionali ci permettono di visualizzare cosa la rete ha appreso durante l'addestramento.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image
# Estrai i modelli per gli strati convoluzionali
layer_outputs = [layer.output for layer in model.layers[:4]]
activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)
base_dir = '/content/melanoma/DermMel/valid/Melanoma/AUG_0_1833.jpeg'
# Carica l'immagine da visualizzare
img = image.load_img(base_dir, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255.0
# Calcola le attivazioni
activations = activation_model.predict(img_tensor)
# Funzione per visualizzare le attivazioni
def display_activation(activations, col_size, row_size, act_index):
activation = activations[act_index]
# Ottieni il numero di filtri nello strato
num_filters = activation.shape[-1]
fig, ax = plt.subplots(row_size, col_size, figsize=(row_size*2.5,col_size*1.5))
for row in range(row_size):
for col in range(col_size):
ax[row][col].imshow(activation[0, :, :, row * col_size + col], cmap='viridis')
if row * col_size + col + 1 == num_filters:
# Interrompi se hai raggiunto il numero di filtri
return
# visualizzare le attivazioni
display_activation(activations, col_size=4, row_size=4, act_index=1)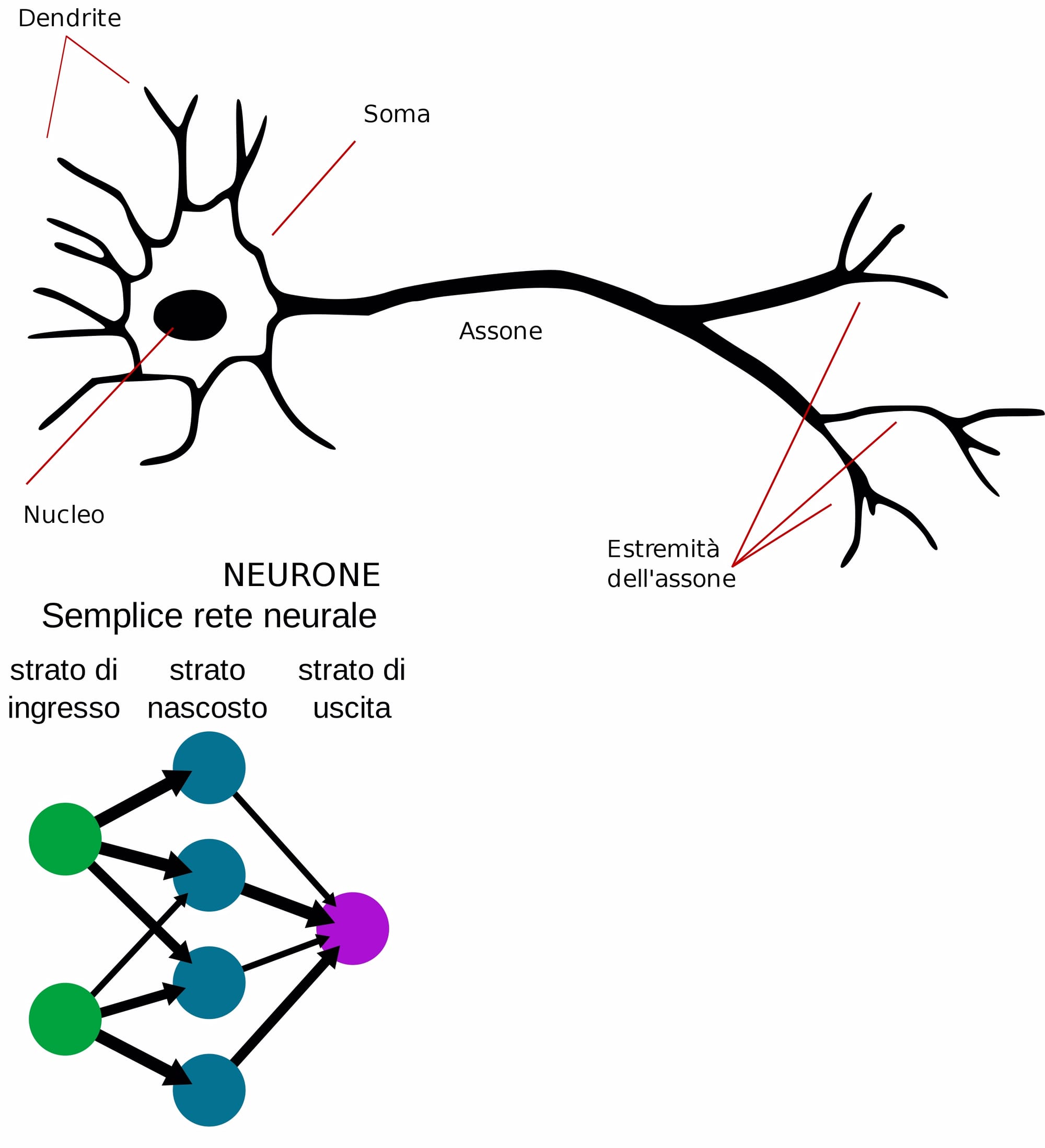
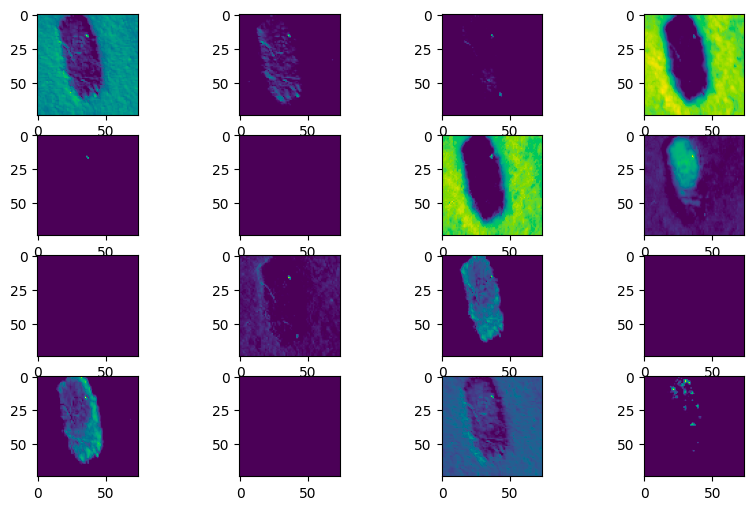
La rete neurale, con la sua sofisticata capacità di analisi, interpreta il melanoma attraverso un intricato sguardo al microscopio digitale, discernendo minuziosamente le caratteristiche morfologiche e pigmentarie, trasformando l'arte della diagnosi dermatologica in un processo tecnologicamente avanzato e preciso.
Da notare come vengono messi in risalto assimmetria, bordi, colore, diametro.
Queste caratteristiche estratte attraverso gli strati della rete giocano un ruolo cruciale nel consentire alla rete neurale di comprendere e identificare melanomi.
La visualizzazione delle rappresentazioni neurali è una pratica essenziale poiché ci consente di esplorare ciò che viene messo in evidenza durante le convoluzioni e le aggregazioni nei vari strati.
Questo approccio fornisce un insight fondamentale per comprendere come la rete neurale interpreta le informazioni visive legate ai melanomi. La possibilità di individuare eventuali discrepanze o rilevare feature non pertinenti consente di affrontare potenziali errori nella predizione.
Se la rete neurale, ad esempio, mettesse in risalto caratteristiche non rilevanti che contribuiscono a predizioni errate, questa analisi delle rappresentazioni diventa il primo punto di ispezione. In tal caso, è necessario eseguire un'analisi manuale per identificare e correggere queste distorsioni.
In seguito, anche l'ottimizzazione dell'architettura della rete diventa importante per garantire che le rappresentazioni neurali siano in linea con le informazioni salienti per una corretta classificazione dei melanomi.
Valutazione del modello
La valutazione del modello può essere fatta con il seguente pezzo di codice
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
# Plottiamo la accuracy con un grafico
plt.scatter(epochs, acc, label='Training Accuracy')
plt.scatter(epochs, val_acc, label='Validation Accuracy')
plt.title('Accuracy in training e validazione')
plt.legend()
plt.show()
# Creiamo un nuovo grafico per la loss
plt.scatter(epochs, loss, label='Training Loss')
plt.scatter(epochs, val_loss, label='Validation Loss')
plt.title('Loss in training e validazione')
plt.legend()
plt.show()
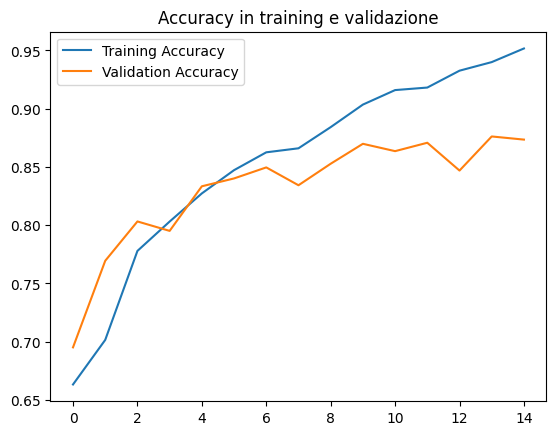
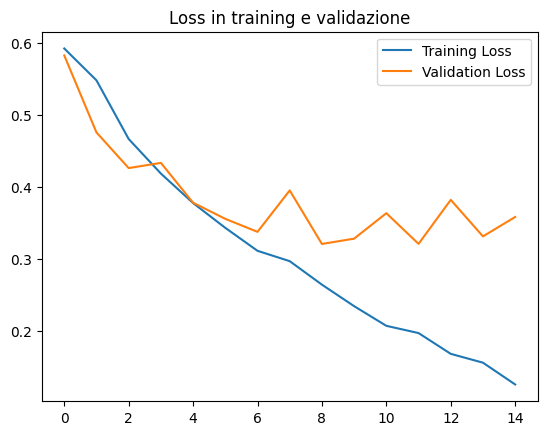
La precisione misura la frazione di previsioni corrette fatte dal modello rispetto al totale delle previsioni effettuate. È una metrica utile per problemi di classificazione, ma può essere ingannevole quando le classi sono sbilanciate. Ad esempio, se hai un set di dati in cui il 95% delle immagini è non maligno e solo il 5% è maligno, un modello che prevede sempre "non maligno" otterrebbe una precisione del 95%, ma non sarebbe molto utile. In tali casi, altre metriche come la sensibilità e la specificità possono essere più informative.
I problemi comuni nella valutazione di modelli di reti neurali includono l'overfitting, che si verifica quando il modello impara i dati di allenamento troppo bene ma non generalizza bene su nuovi dati, e l'underfitting, che si verifica quando il modello non impara abbastanza dai dati di allenamento e non fa previsioni accurate.
Esempio di overfitting
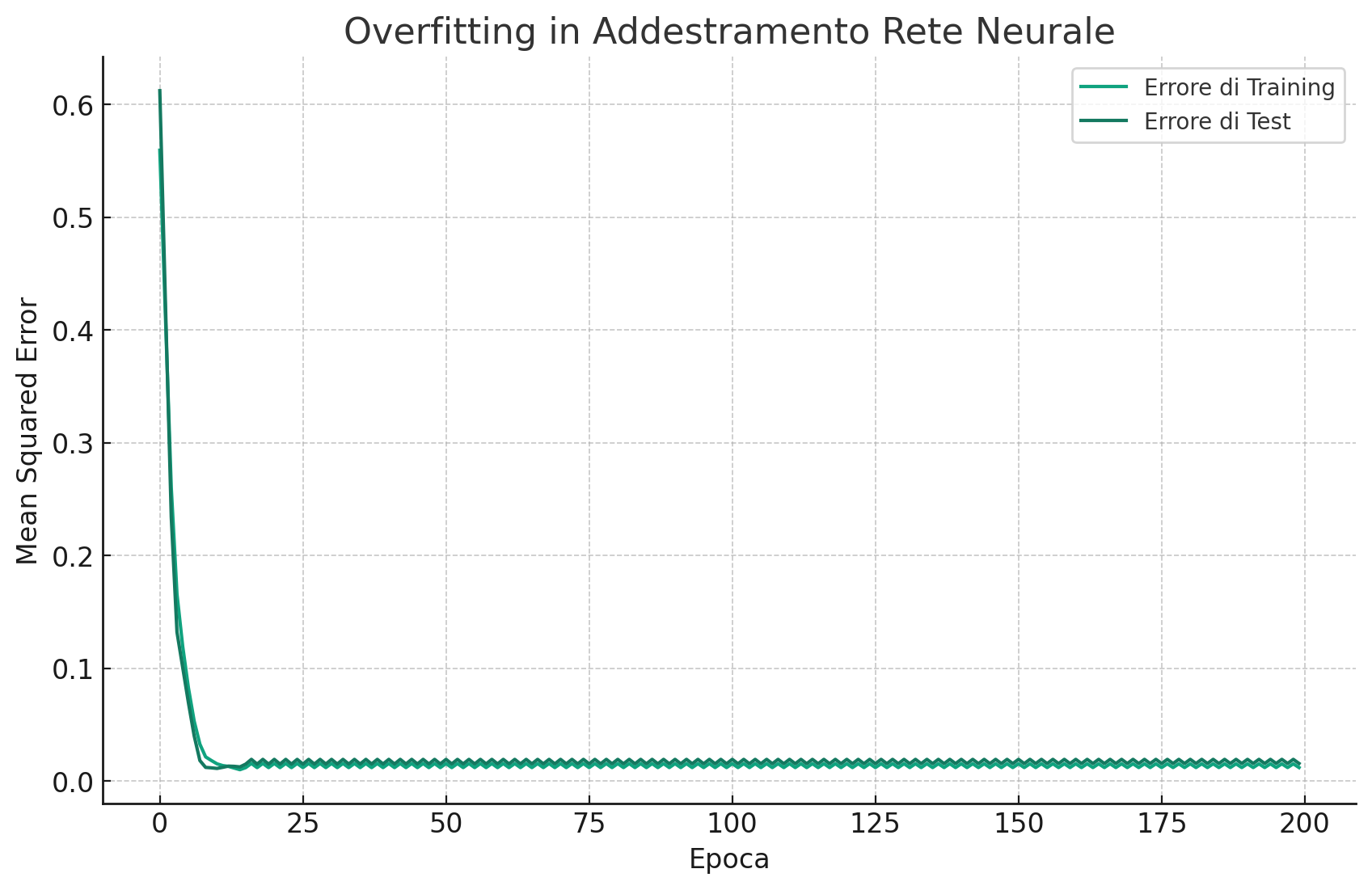
Il grafico mostra l'andamento dell'errore quadratico medio (Mean Squared Error, MSE) sia per il dataset di training che per quello di test, al variare delle epoche di addestramento.
All'inizio, entrambi gli errori diminuiscono man mano che la rete impara dai dati. Tuttavia, dopo un certo numero di epoche, l'errore di test inizia a peggiorare mentre quello di training continua a diminuire. Questo è un classico segnale di overfitting: la rete neurale sta imparando perfettamente i dettagli (e anche il rumore) del dataset di training a discapito della sua capacità di generalizzare su dati non visti (il dataset di test).
L'overfitting è un problema comune nell'addestramento di modelli di machine learning, soprattutto in presenza di reti neurali profonde e complesse. Combatte l'overfitting richiede strategie come l'early stopping, la regolarizzazione (ad esempio, L1/L2), il dropout, o l'ottenimento di più dati di training.
Esempio di underfitting
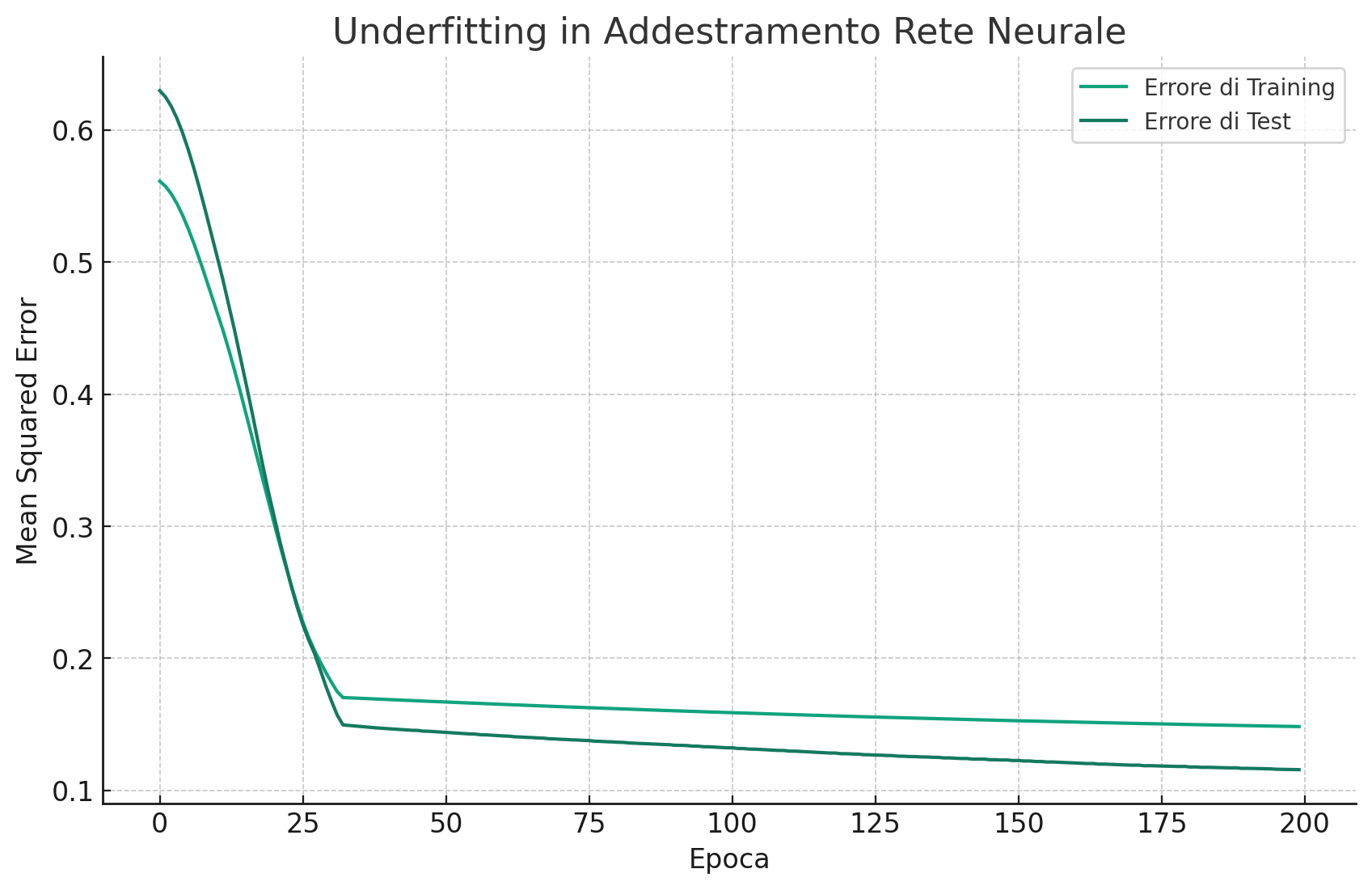
Il grafico illustra l'underfitting durante l'addestramento di una rete neurale. In questo scenario, sia l'errore di training che quello di test rimangono elevati e non migliorano significativamente con l'aumentare delle epoche. Questo suggerisce che il modello è troppo semplice per catturare la complessità dei dati.
L'underfitting è evidente quando un modello non riesce a ridurre l'errore di training, indicando che non sta imparando adeguatamente dai dati. A differenza dell'overfitting, dove il modello impara troppo bene i dati di training a scapito della generalizzazione, nell'underfitting il modello non riesce nemmeno a imparare i dati di training in modo efficace.
Per affrontare l'underfitting, potremmo considerare l'uso di un modello più complesso con più neuroni o strati, l'aggiunta di più feature che possono aiutare il modello a imparare meglio dai dati, o la revisione del preprocessing dei dati per assicurarsi che non stiamo perdendo informazioni importanti.
Per un approfondimento del seguente argomento leggi l'articolo di Andrea D'Agostino
Andrea D’Agostino
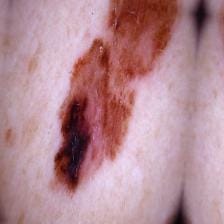
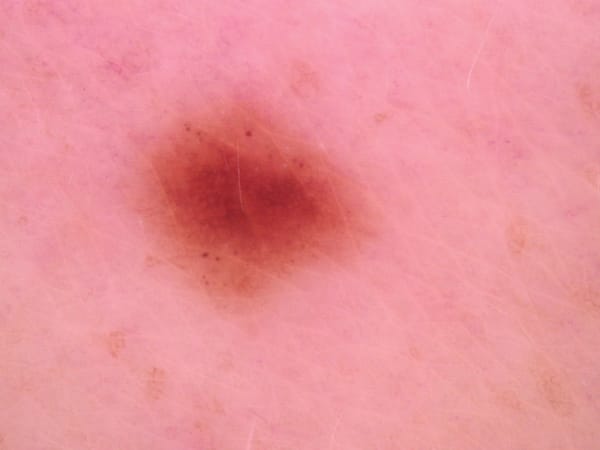
Fare predizioni sui melanomi
Ora possiamo passare una immagine di test di melanoma benigno o maligno per la predizione, in questo caso passo l'immagine di melanoma maligno come test.
import numpy as np
from keras.preprocessing import image
import tensorflow as tf
# Inserimento manuale del percorso dell'immagine
path = input("Inserisci il percorso dell'immagine: ")
# Caricamento e preparazione dell'immagine
img = image.load_img(path, target_size=(150, 150)) # Scala l'immagine alla dimensione target
x = image.img_to_array(img) # Converte l'immagine in un array
x /= 255 # Normalizza i valori dei pixel
x = np.expand_dims(x, axis=0) # Aggiungi una dimensione per adattarsi all'input del modello
model_path = '/content/save_model/rete-neurale_model.h5'
# model = load_model('/content/save_model/rete-neurale_model.h5')
model = tf.keras.models.load_model(model_path)
# Esecuzione della predizione
classes = model.predict(x, batch_size=10)
print(classes[0])
# Interpretazione del risultato
if classes[0] > 0.5:
print(path.split("/")[-1] + " è benigno!")
else:
print(path.split("/")[-1] + " è maligno!")
Output
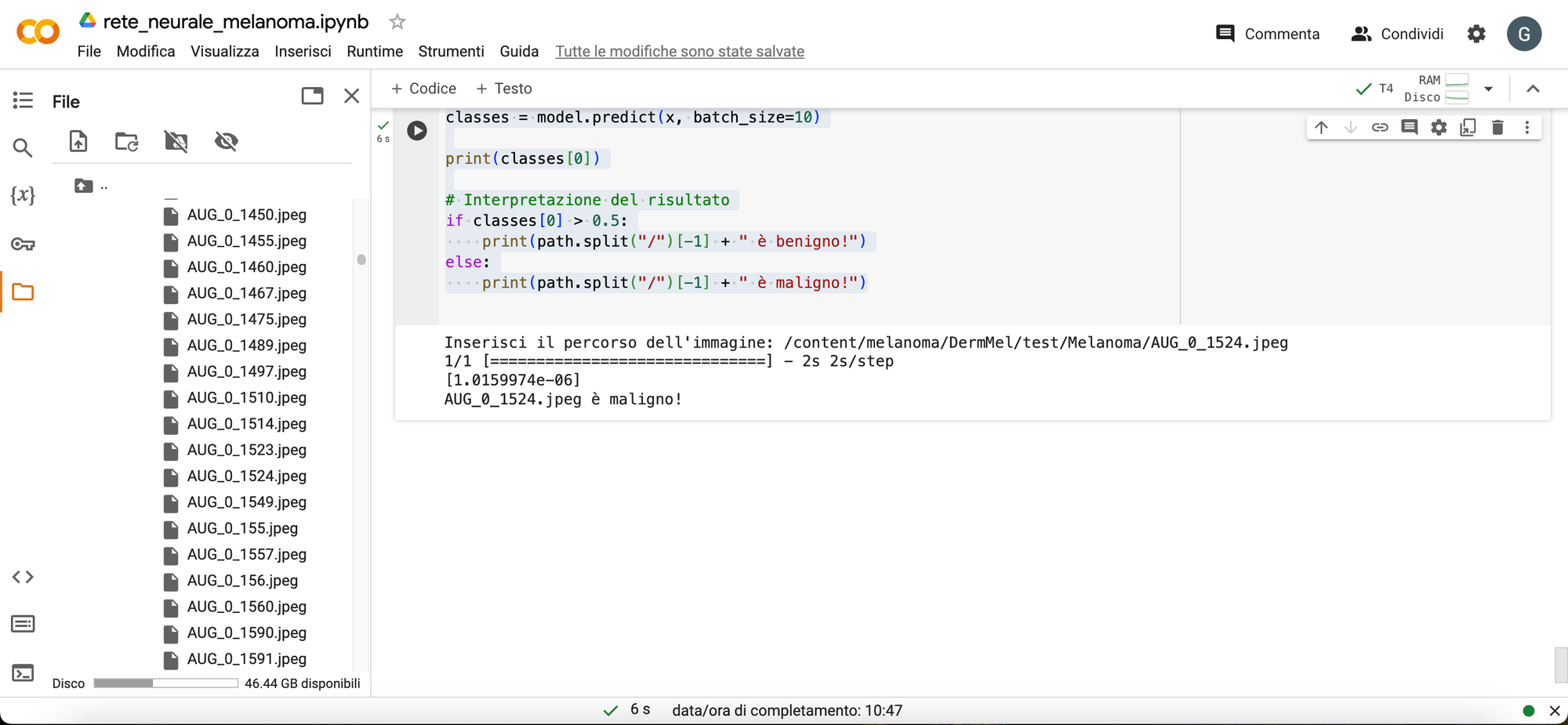
Secondo test
Seconda immagine di test melanoma benigno.
Output
Siamo giunti alla conclusione dell'articolo e desidero mettere a disposizione il repository GitHub per coloro che desiderano contribuire o apportare miglioramenti al codice.
 GiaStra92
GiaStra92




Commenti dalla community