
Una delle prime fasi del processo di data science è quella della selezione del modello.
Nella stragrande maggioranza dei casi, noi non sapremo quale sarà il modello più performante per il nostro set di dati.
Nasce quindi l'esigenza di poter iterare tra diversi modelli candidati e registrare le performance di ognuno in modo da poter scegliere quale addestrare e migliorare.
In questo articolo, vedremo insieme come utilizzare Python per confrontare e valutare le prestazioni dei modelli di apprendimento automatico.
Utilizzeremo la cross-validazione con Sklearn per testare i modelli e Matplotlib per visualizzare i risultati.
La motivazione principale per fare ciò è quella di avere una comprensione chiara e precisa delle prestazioni dei modelli e quindi di migliorare il processo di selezione del modello.
La cross-validazione è un metodo affidabile per testare i modelli su dati diversi dai dati di training. Ci consente di valutare le prestazioni del modello su dati che non sono stati utilizzati per allenare il modello stesso, il che ci fornisce una stima più precisa delle prestazioni del modello sui dati reali.
Se vuoi leggere di più su cosa è e come funziona la cross-validazione ti consiglio di cliccare sull'articolo qui in basso
 Andrea D’Agostino
Andrea D’Agostino
Useremo un approccio orientato agli oggetti in modo da poterlo riutilizzare per altri progetti di machine learning facilmente. Infatti, questo metodo è altamente replicabile.
- a creare del codice Python per testare modelli predittivi con Sklearn usando OOP (object-oriented programming)
- a fare cross-validazione con Sklearn per valutare le performance del modello sul set di validazione
- a visualizzare i risultati con Matplotlib
La classe Benchmark
Per iniziare, creeremo una classe chiamata Benchmark che avrà la responsabilità di testare i modelli. La classe accetterà un dizionario di modelli, dove la chiave sarà il nome del modello e il valore sarà l'oggetto del modello stesso.
La classe genererà anche i dati di prova utilizzando la funzione make_classification di scikit-learn.
import numpy as np
from sklearn import model_selection
from sklearn import metrics
from sklearn import datasets
import matplotlib.pyplot as plt
class Benchmark:
"""
Questa classe consente di confrontare e
valutare le prestazioni dei modelli di machine learning usando la cross-validation.
Parametri
----------
models : dict
Dizionario di modelli, dove la chiave è il nome del modello e il valore è l'oggetto del modello.
"""
def __init__(self, models):
self.models = models
def test_models(self, X=None, y=None, cv=5):
"""
Testa i modelli utilizzando i dati forniti e cross-validation.
Parametri
----------
X : array o DataFrame Pandas, shape (n_samples, n_features)
Feature per i dati di prova.
y : array o Serie Pandas, shape (n_samples,)
Target per i dati di training.
cv : int
Numero di fold nella cross-validation
Restituisce
-------
best_model : str
Nome del modello con il punteggio più alto.
"""
if X is None or y is None:
X, y = datasets.make_classification(
n_samples=100,
n_features=10,
n_classes=2,
n_clusters_per_class=1,
random_state=0
)
self.results = {}
for name, model in self.models.items():
scores = model_selection.cross_val_score(model, X, y, cv=cv)
self.results[name] = scores.mean()
self.best_model = max(self.results, key=self.results.get)
return f"The best model is: {self.best_model} with a score of {self.results[self.best_model]:.3f}"La funzione principale della classe sarà test_models, che accetterà i dati di prova e utilizzerà la cross-validation per testare i modelli.
La funzione salverà i risultati in una variabile legata all'istanza e restituirà il modello con il punteggio più alto attraverso le varie iterazioni della cross-validation.
Per visualizzare i risultati, aggiungeremo una funzione chiamata plot_cv_results alla classe.
Questa funzione utilizzerà la libreria Matplotlib per creare un grafico a barre che mostra il punteggio di validazione incrociata medio per ogni modello.
def plot_cv_results(self):
plt.figure(figsize=(15,5))
x = np.arange(len(self.results))
plt.bar(x, list(self.results.values()), align='center', color ='g')
plt.xticks(x, list(self.results.keys()))
plt.ylim([0, 1])
plt.ylabel('Cross-Validation Score')
plt.xlabel('Models')
plt.title('Model Comparison')
for index, value in enumerate(self.results.values()):
plt.text(index, value, str(round(value,2)))
plt.show()Infine, per utilizzare la classe, istanzieremo l'oggetto Benchmark passando il dizionario di modelli e chiamando la funzione test_models con i dati di prova. Successivamente, utilizzeremo la funzione plot_cv_results per visualizzare i risultati.
from sklearn import linear_model, ensemble
models = {
'logistic': linear_model.LogisticRegression(),
'randomforest': ensemble.RandomForestClassifier(),
'extratrees': ensemble.ExtraTreesClassifier(),
'gbm': ensemble.GradientBoostingClassifier()
}
benchmark = Benchmark(models)
print(benchmark.test_models())
benchmark.plot_cv_results()E questa è la visualizzazione.
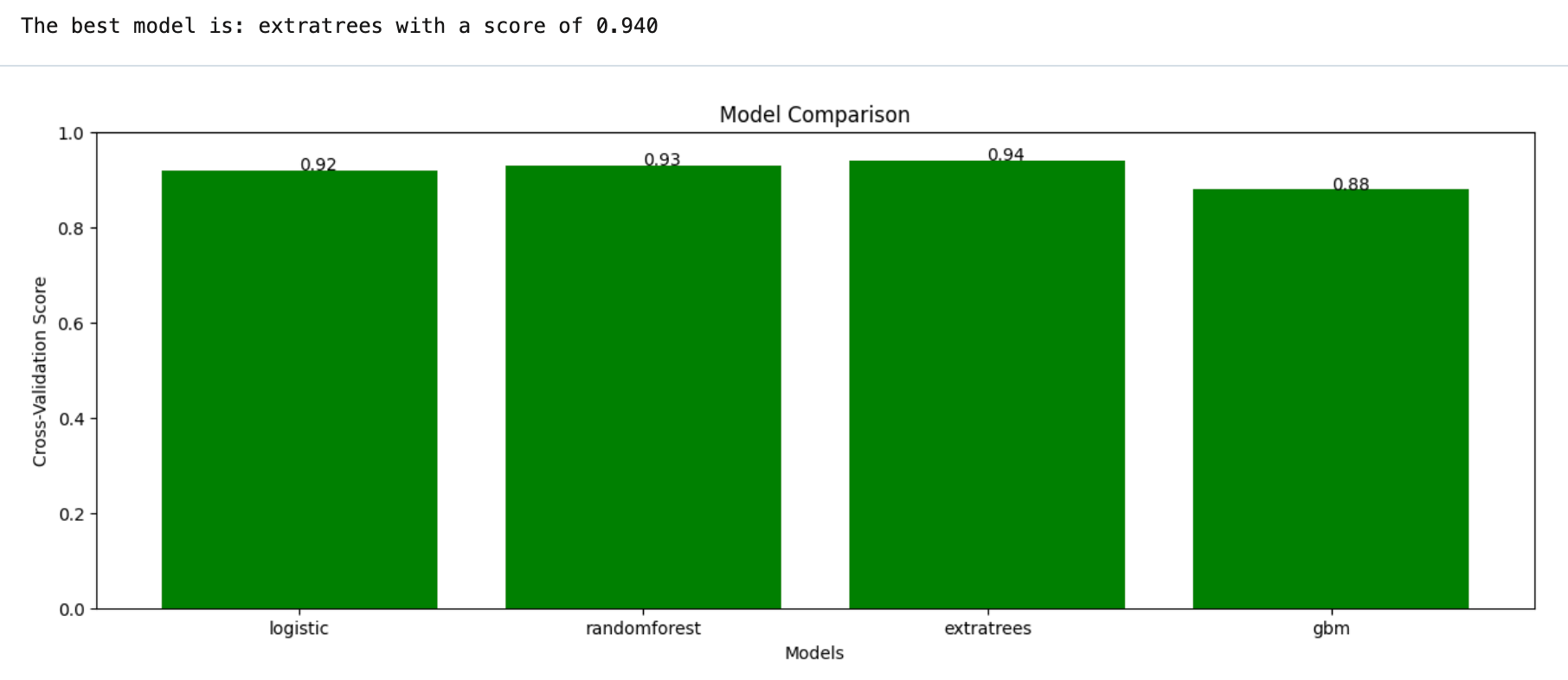
In questo modo, possiamo facilmente confrontare e valutare le prestazioni dei modelli e quindi scegliere il modello che offre le migliori prestazioni per il nostro problema specifico.
In questo esempio abbiamo utilizzato la funzione make_classification per generare i dati di prova, ma naturalmente è possibile utilizzare qualsiasi dataset a proprio piacimento.
Inoltre, la classe Benchmark può essere estesa per includere altre funzionalità, come ad esempio la possibilità di salvare i risultati in un file o di eseguire il test dei modelli su più dataset.
Quali sono i next step?
Seguendo la pipeline usuale del machine learning, il prossimo step sarà quello di fare un tuning degli iperparametri del modello migliore (in questo caso ExtraTreesClassifier). Questo sempre se le nostre feature sono da considerarsi definitive.
Qualora non lo fossero, uno step intermedio sarebbe quello di fare feature selection / engineering, e ripetere lo step di benchmarking ogni volta che si cambiano tali feature.
Ti rimando ad un articolo sulla feature selection, che si sposa bene con l'articolo qui trattato della model selection
Andrea D’Agostino
Conclusione
La classe Benchmark che abbiamo creato è solo un esempio di come è possibile implementare questa tecnica in un progetto, ma può essere facilmente adattato e personalizzato per soddisfare le esigenze specifiche del proprio progetto.
Il principale vantaggio di usare questo approccio è quello di automatizzare il processo di confronto e valutazione dei modelli, il che può risparmiare tempo e ridurre gli errori umani.
Template del codice
Ecco qui l'intera codebase
class Benchmark:
def __init__(self, models):
self.models = models
def test_models(self, X=None, y=None, cv=5):
if X is None or y is None:
X, y = datasets.make_classification(
n_samples=100,
n_features=10,
n_classes=2,
n_clusters_per_class=1,
random_state=0
)
self.results = {}
for name, model in self.models.items():
scores = model_selection.cross_val_score(model, X, y, cv=cv)
self.results[name] = scores.mean()
self.best_model = max(self.results, key=self.results.get)
return f"The best model is: {self.best_model} with a score of {self.results[self.best_model]:.3f}"
def plot_cv_results(self):
plt.figure(figsize=(15,5))
x = np.arange(len(self.results))
plt.bar(x, list(self.results.values()), align='center', color ='g')
plt.xticks(x, list(self.results.keys()))
plt.ylim([0, 1])
plt.ylabel('Cross-Validation Score')
plt.xlabel('Models')
plt.title('Model Comparison')
for index, value in enumerate(self.results.values()):
plt.text(index, value, str(round(value,2)))
plt.show()
from sklearn import linear_model, ensemble
models = {
'logistic': linear_model.LogisticRegression(),
'randomforest': ensemble.RandomForestClassifier(),
'extratrees': ensemble.ExtraTreesClassifier(),
'gbm': ensemble.GradientBoostingClassifier()
}
benchmark = Benchmark(models)
print(benchmark.test_models())
benchmark.plot_cv_results()




Commenti dalla community