
Tabella dei Contenuti
Non tutte le reti neurali sono uguali: per ottenere risultati ottimali in contesti specifici, sono state sviluppate numerose architetture, ciascuna con i propri punti di forza e peculiarità.
In questo articolo esploreremo alcune delle architetture di reti neurali più iconiche e influenti che hanno segnato la storia del deep learning e della computer vision.
Partiremo con AlexNet, una delle prime reti convolutive che ha gettato le basi per il riconoscimento di immagini, per poi passare a VGG, che ha spinto i limiti della profondità delle reti.
Successivamente, ci concentreremo su ResNet, la quale ha introdotto connessioni residuali, e concluderemo con EfficientNet, un'architettura moderna progettata per massimizzare efficienza e prestazioni.
Attraverso questa panoramica, analizzeremo come ciascuna di queste architetture affronta le sfide legate alla complessità e alla scalabilità, scoprendo come abbiano contribuito a rendere le reti neurali sempre più potenti e versatili.
È possibile trovare una lista di modelli, tra cui questi proposti in questo articolo, al seguente link alla documentazione di TorchVision.
Vuoi sapere cosa è una convoluzione? Leggi di più qui! 👇

AlexNet
AlexNet è una delle architetture di reti neurali più popolari. Fu proposta da Alex Krizhevsky per la competizione ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Nel 2012, Alex Krizhevsky e il suo team pubblicarono l’articolo ImageNet Classification with Deep Convolutional Neural Networks.
La sfida consisteva nello sviluppare una rete neurale convolutiva in grado di classificare 1,2 milioni di immagini ad alta risoluzione presenti nel dataset ImageNet LSVRC-2010 in oltre 1000 categorie diverse.
L'architettura è composta in totale da otto livelli, di cui i primi cinque sono convolutivi e gli ultimi tre sono fully connected. I primi due strati convolutivi sono collegati a strati di max pooling al fine di estrarre il massimo numero di feature. Passando poi al terzo, quarto e quinto strato convolutivo, essi sono collegati direttamente agli strati fully connected.
Tutti gli output degli strati convolutivi e non sono collegati a una funzione di attivazione non lineare ovvero la ReLU. L'ultimo livello di output è collegato a uno strato di attivazione denominato softmax, il quale genera una distribuzione sulle 1000 etichette.
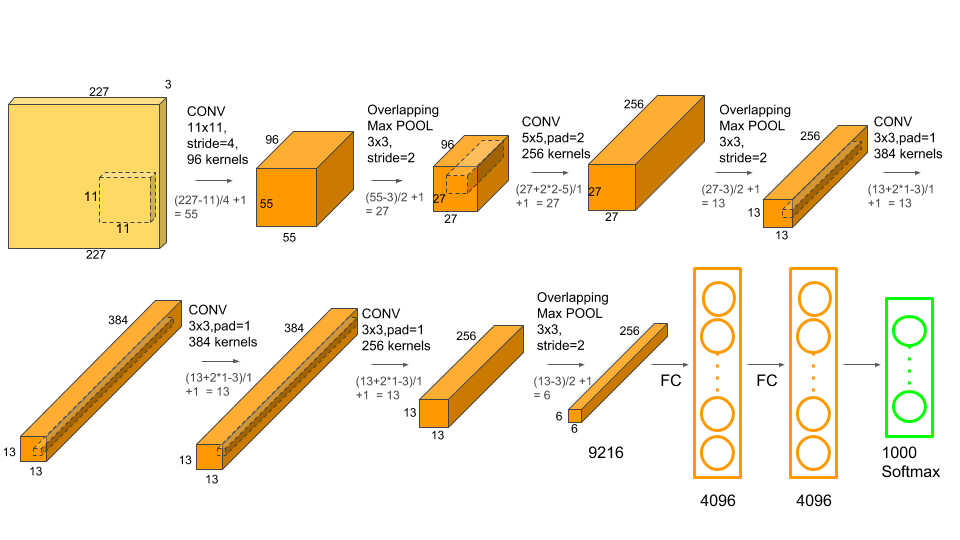
Le dimensioni dell'input della rete sono 256×256×3, il che significa che l'input di AlexNet è un'immagine RGB (3 canali) di 256×256 pixel. L'architettura coinvolge più di 60 milioni di parametri e 650.000 neuroni.
Il modello utilizza un'ottimizzatore quale lo stochastic gradient descent con batch size, momentum e weight decay impostati rispettivamente a 128, 0,9 e 0,0005. Tutti i livelli utilizzano un tasso di apprendimento uguale pari a 0,001. Per affrontare l'overfitting durante l'addestramento, AlexNet utilizza sia data augmentation che strati di dropout.
Di seguito sono riportati i risultati ottenuti utilizzando l'architettura di AlexNet:

È possibile importare il modello pre-addestrato usando TorchVision in Python.
import torch
import torchvision.models as models
# Caricare il modello AlexNet pre-addestrato
model = models.alexnet(pretrained=True)
# Mettere il modello in modalità di valutazione
model.eval()
# Visualizzare l'architettura del modello
print(model)AlexNet, nonostante sia un'architettura meno avanzata rispetto ai modelli moderni, può essere ancora utile per diversi task di visione artificiale e riconoscimento di pattern, specialmente quando le risorse computazionali sono limitate o quando il task non richiede modelli estremamente complessi.
VGG-16
L'architettura VGG-16 è una rete neurale convoluzionale (CNN) sviluppata per il riconoscimento di immagini. È caratterizzata dalla semplicità dell'uso di piccoli filtri di convoluzione (3x3) e una struttura a profondità crescente, risultando molto efficace per il riconoscimento di immagini. VGG-16 sta per Visual Geometry Group e deriva dal fatto che è composta da 16 strati convolutivi.
Questa architettura è stata sviluppata da A. Zisserman e K. Simonyan dell'Università di Oxford, come descritto nel loro articolo di ricerca, Very Deep Convolutional Networks for Large-Scale Image Recognition.
L'architettura è composta da:
- Input e primo blocco convoluzionale: VGG-16 riceve un'immagine in input (224x224x3) e applica una serie di convoluzioni 3x3 e ReLU. Nel primo blocco, troviamo due livelli convoluzionali seguiti da un max-pooling.
- Profondità crescente: L'architettura aumenta il numero di filtri convoluzionali a ogni blocco successivo. Il secondo blocco ha anche due strati, mentre i blocchi successivi contengono tre strati ciascuno. I filtri iniziano da 64 e arrivano fino a 512.
- Pooling e strati densi: Ogni blocco è seguito da uno strato di max-pooling, riducendo progressivamente le dimensioni spaziali. Alla fine, si utilizzano strati completamente connessi (densi) per la classificazione. VGG-16 ha tre di questi strati completamente connessi.
- Output: L'ultimo strato denso usa SoftMax per generare le probabilità di classificazione.
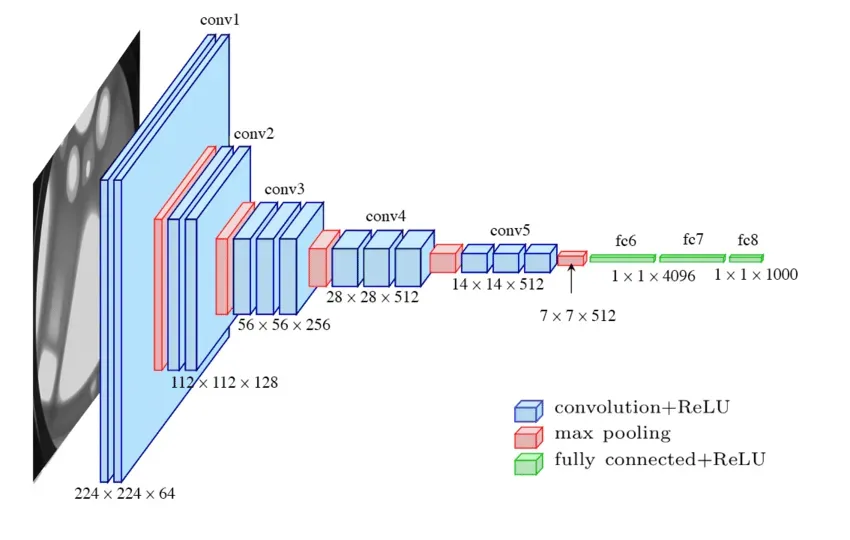
VGG è un modello potente per classificazione e riconoscimento di immagini, facile da adattare grazie alla struttura regolare. La semplicità dei blocchi convoluzionali lo rende intuitivo per l’analisi e l’adattamento a task diversi.
VGG però richiede molte risorse computazionali e memoria. Questo ne limita l’uso in applicazioni real-time o su dispositivi con risorse limitate.
È possibile importare il modello pre-addestrato usando TorchVision in Python.
import torch
import torchvision.models as models
# Caricare il modello VGG-16 pre-addestrato
model = models.vgg16(pretrained=True)
# Se necessario, modificare il numero di classi nell'ultimo strato per un fine-tuning su un nuovo dataset
# Ad esempio, cambiamo l'ultimo strato per una classificazione a 10 classi
num_classes = 10
model.classifier[6] = torch.nn.Linear(in_features=4096, out_features=num_classes)
# Visualizzare l'architettura del modello modificato
print(model)ResNet
Le reti neurali sono sempre più difficili da addestrare, pertanto accelerare i tempi di addestramento rappresenta un passaggio cruciale al fine di ottimizzare l’intero processo. Questa ricerca è stata pubblicata nell'articolo intitolato Deep Residual Learning for Image Recognition nel 2015 da cui nacque la celebre ResNet, abbreviazione di "Residual Network". Infatti, la domanda che gli autori si sono posti è la seguente: l’addestramento delle reti migliora aggiungendo più strati?
La risposta a questa domanda risiede nel noto problema della esplosione del gradiente.
Durante la fase di addestramento, si arriva ad un punto in cui aumentare la profondità della rete induce ad una saturazione della precisione per poi scaturire in un rapido decadimento. Questo fenomeno mette in evidenza che non tutte le architetture di reti neurali sono altrettanto facili da ottimizzare.
Pertanto, ResNet, utilizza una tecnica chiamata mappatura residuale utile per contrastare tale problematica. Invece di richiedere che ogni serie di strati si adatti direttamente alla mappatura desiderata, la Residual Network consente esplicitamente a questi strati di adattarsi a una mappatura residuale.
Di seguito è riportato il blocco costitutivo di una rete residuale.
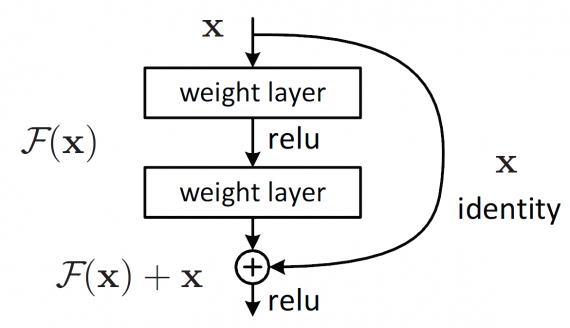
Rispetto alle architetture di reti neurali convolutive, le ResNet sono relativamente facili da comprendere. Di seguito è mostrata l'immagine di una rete VGG, di una rete neurale semplice con 34 strati e di una rete neurale residuale con 34 strati. Nella rete semplice, al fine di ottenere la mappa delle features in uscita, gli strati hanno lo stesso numero di filtri. Se la dimensione delle feature in uscita è dimezzata, il numero di filtri viene raddoppiato, rendendo il processo di addestramento più complesso.
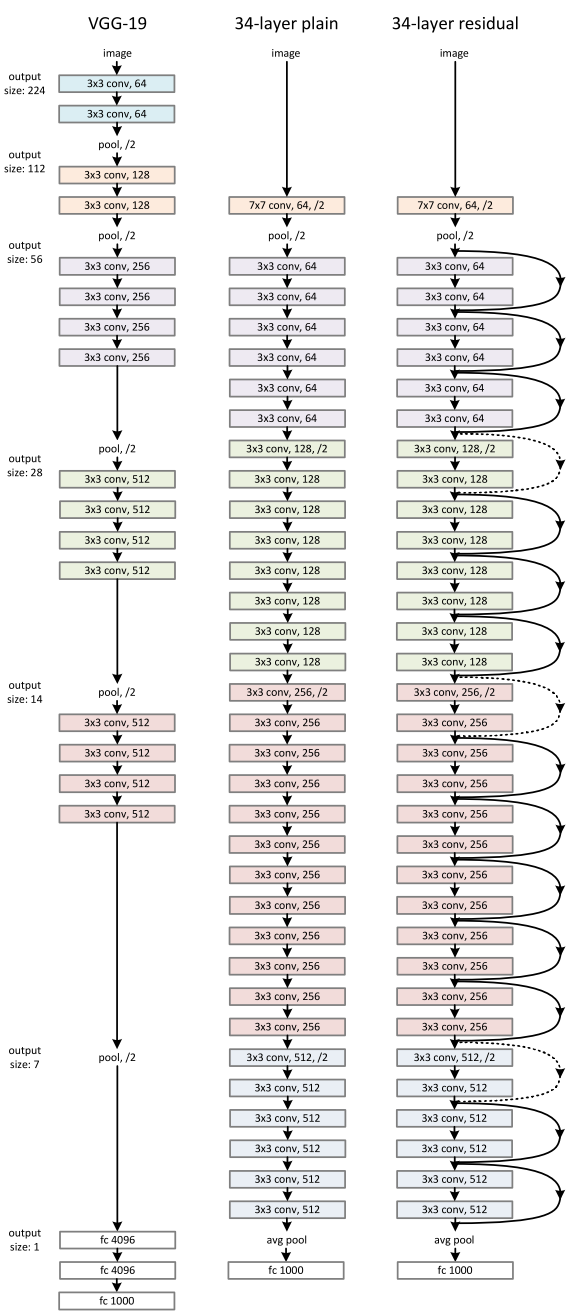
Nella Rete Neurale Residuale, come possiamo vedere, c’è un ridotto numero di filtri e una complessità inferiore durante l’addestramento rispetto alla rete VGG.
Viene aggiunta una connessione scorciatoia la quale trasforma la rete nella sua versione residuale equivalente. Questa connessione scorciatoia esegue una mappatura identitaria, con l’aggiunta di zeri per aumentare le dimensioni, non introducendo parametri aggiuntivi. La scorciatoia di proiezione è rappresentata matematicamente come \( F(x \{ W \} + x) \), utilizzata per adattare le dimensioni calcolate tramite convoluzioni 1×1.
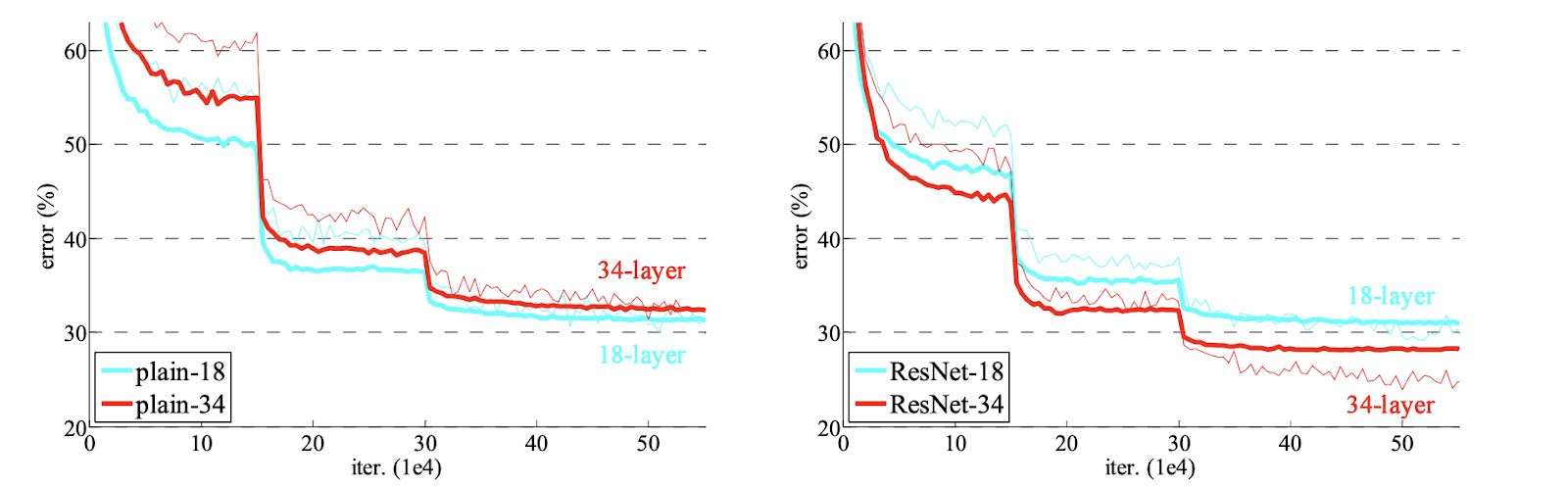
Le ResNet ottengono ottimi risultati con architetture più profonde. Di seguito è mostrata un'immagine che presenta il tasso di errore di due reti neurali, rispettivamente di 18 e 34 strati. A sinistra, il grafico mostra le reti semplici, mentre il grafico a destra mostra le loro equivalenti ResNet. La linea sottile rossa nell’immagine rappresenta l'errore di addestramento, mentre la linea in grassetto rappresenta l'errore di validazione.
La Wide Residual Networks, è un miglioramento più recente, dove invece di aumentare la profondità di una rete per migliorarne la precisione, è stato dimostrato che una rete può essere meno profonda e più ampia senza comprometterne le prestazioni.
In una rete neurale non c’è garanzia che vengano utilizzati tutti i blocchi residuali; alcuni potrebbero essere bypassati, o solo pochi blocchi potrebbero contribuire ad estrarre informazioni utili. Questo problema potrebbe essere risolto disattivando blocchi casuali, un concetto simile al dropout. Seguendo questa idea, gli autori di Wide ResNet hanno dimostrato che una rete residuale ampia può ottenere prestazioni migliori di una profonda.
Come per la VGG, è possibile utilizzare TorchVision per l'import della rete.
import torch
import torchvision.models as models
# Caricare il modello ResNet-50 pre-addestrato
model = models.resnet50(pretrained=True)
# Modificare l'ultimo strato se necessario (ad esempio, per adattarlo a un nuovo numero di classi)
num_classes = 10 # Imposta il numero di classi secondo il tuo dataset
model.fc = torch.nn.Linear(in_features=model.fc.in_features, out_features=num_classes)
# Visualizzare l'architettura del modello modificato
print(model)ResNet è stata sviluppata principalmente per il task di classificazione su larga scala, come nel dataset ImageNet. Grazie ai blocchi residuali, ResNet può essere estesa a reti molto profonde (fino a 152 o 200 strati), ottenendo ottimi risultati nella classificazione di immagini complesse.
ResNet è comunemente usata anche come backbone in modelli di segmentazione semantica. L'architettura residuale permette di catturare dettagli sia a livello globale che locale, migliorando le prestazioni dei modelli di segmentazione.
Machine Learning Engineering
Andriy Burkov
Questo è IL libro di IA applicata più completo in circolazione. È pieno di best practice e modelli di progettazione per la creazione di soluzioni di apprendimento automatico affidabili e scalabili.

Inception
L'architettura Inception, introdotta per la prima volta con il modello GoogLeNet e poi evoluta con varianti come Inception v3 e Inception-ResNet, è progettata per affrontare il problema dell'efficienza computazionale nei modelli di deep learning. Questa architettura si basa sul concetto di Inception module, che permette di utilizzare kernel di diverse dimensioni in parallelo, migliorando la capacità del modello di catturare dettagli diversi e di adattarsi a oggetti di varie scale.
Rispetto a VGG, le Reti Inception si sono rivelate più efficienti dal punto di vista computazionale, sia in termini di numero di parametri generati dalla rete che del costo economico sostenuto. Dovendo apportare modifiche a una rete Inception, è necessario prestare attenzione a non perdere i vantaggi computazionali. Pertanto, l'adattamento di una rete Inception per casi d'uso diversi si rivela essere un problema a causa dell'incertezza sull'efficienza della nuova rete.
Nel modello Inception-v3 sono state suggerite diverse tecniche per ottimizzare la rete, allo scopo di allentare i vincoli per un adattamento più semplice del modello. Le tecniche includono convoluzioni fattorizzate, regolarizzazione, riduzione dimensionale e computazioni parallelizzate.
L'architettura di una rete Inception-v3 viene costruita progressivamente, passo dopo passo, come spiegato di seguito:
- Convoluzioni fattorizzate: questo aiuta a ridurre l'efficienza computazionale, poiché diminuisce il numero di parametri coinvolti nella rete. Inoltre, mantiene sotto controllo l'efficienza della rete.
- Convoluzioni più piccole: sostituire convoluzioni più grandi con convoluzioni più piccole porta sicuramente a un allenamento più veloce. Ad esempio, un filtro 5 × 5 ha 25 parametri; due filtri 3 × 3 che sostituiscono una convoluzione 5 × 5 hanno solo 18 parametri.
- Convoluzioni asimmetriche: Una convoluzione 3×3 potrebbe essere sostituita da una convoluzione 1×3 seguita da un’altra 3×1. Se una convoluzione 3×3 viene rimpiazzata da una 2x2, il numero di parametri sarà leggermento più alto rispetto l’asimettrica convoliuzione proposta.
- Classificazioni ausiliarie: un classificatore ausiliario è una piccola CNN inserita tra gli strati durante l’addestramento agendo da regolizzatore.
Architettura finale:
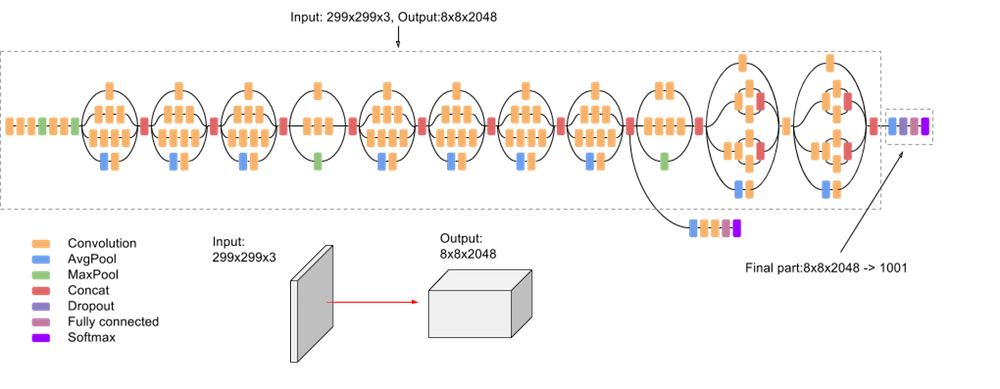
L'architettura Inception è particolarmente utile per task complessi di visione artificiale in cui è necessario bilanciare efficienza computazionale e capacità di rappresentazione profonda.
In Python, si importa come gli altri modelli.
import torch
import torchvision.models as models
# Importare il modello Inception v5 pre-addestrato
model = models.inception_v5(pretrained=True)
# Mettere il modello in modalità di valutazione
model.eval()
# Visualizzare l'architettura del modello
print(model)EfficientNet
EfficientNet è una famiglia di modelli di reti neurali convoluzionali introdotta da Google nel 2019. L'innovazione principale di EfficientNet risiede nel suo approccio al dimensionamento (scaling) delle reti neurali chiamato compound scaling, rendendole più efficienti sia in termini di accuratezza che di costo computazionale rispetto ai modelli precedenti.
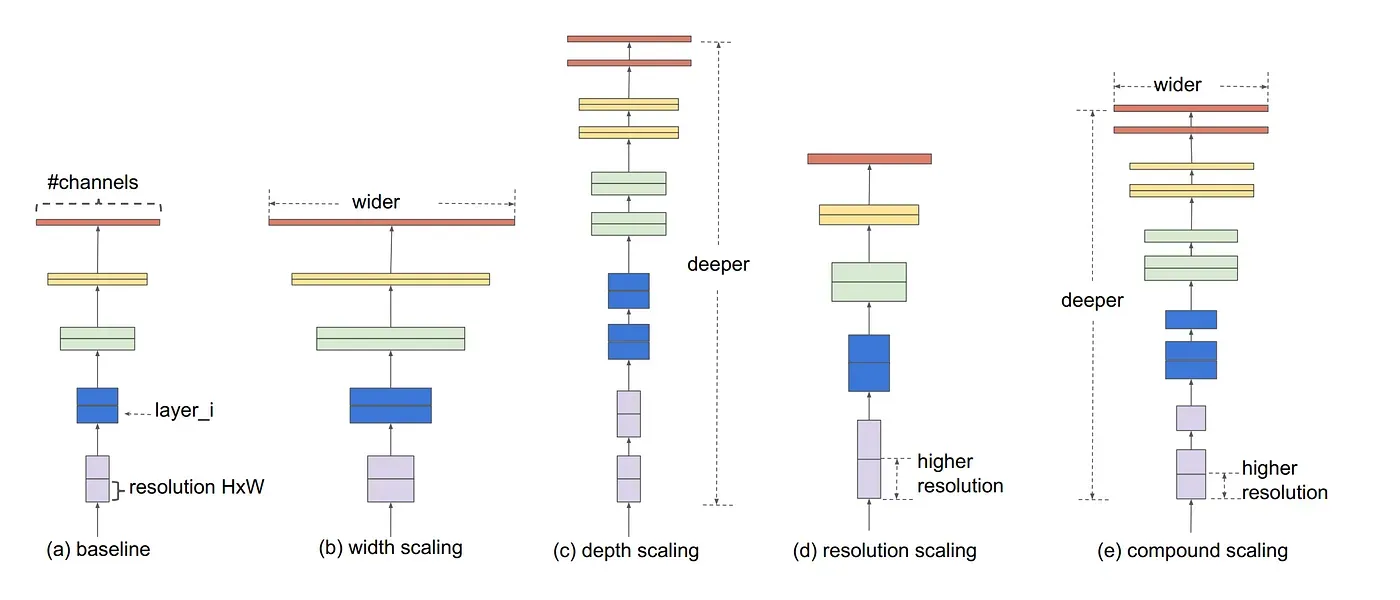
Il compound scaling permette alle reti neurali in modo equilibrato ed efficiente. Invece di aumentare singolarmente la profondità (numero di strati), la larghezza (numero di canali per strato) o la risoluzione dell'immagine in input, il compound scaling scala simultaneamente questi tre aspetti utilizzando un fattore di scaling comune.
Questo approccio permette di espandere la capacità del modello in modo armonioso, mantenendo un equilibrio tra complessità computazionale e accuratezza. In pratica, ottimizza le dimensioni della rete neurale per massimizzare le prestazioni, evitando inefficienze che possono sorgere potenziando solo uno dei parametri strutturali.
Il metodo del compound scaling è mostrato nella figura :
Per importare EfficientNet v2 in PyTorch, utilizziamo ancora il modulo torchvision.models, che include varianti di EfficientNet v2 come EfficientNet v2-S, v2-M, e v2-L. Queste varianti migliorano l'efficienza e la precisione rispetto alla prima versione di EfficientNet.
import torch
import torchvision.models as models
# Caricare il modello EfficientNet v2-S pre-addestrato
model = models.efficientnet_v2_s(pretrained=True)
# Mettere il modello in modalità di valutazione
model.eval()
# Visualizzare l'architettura del modello
print(model)
Conclusioni
Abbiamo visto come diverse architetture di reti neurali abbiano giocato un ruolo fondamentale nello sviluppo e nel progresso del deep learning. Ogni architettura da AlexNet, pioniera del riconoscimento di immagini, a EfficientNet, che ottimizza l'efficienza senza sacrificare le prestazioni ha rappresentato una risposta a sfide specifiche, adattandosi alle esigenze di ogni epoca e spingendo sempre più in là i confini delle applicazioni dell'intelligenza artificiale.
Ciò che emerge chiaramente è che non esiste una “taglia unica” nel mondo delle reti neurali. Ogni modello è il risultato di un compromesso tra complessità, accuratezza e velocità di calcolo. La continua evoluzione di queste architetture dimostra come l'innovazione sia alla base del progresso tecnologico, portando a soluzioni sempre più sofisticate per problemi reali.
Con la continua espansione delle capacità computazionali e la disponibilità di dati sempre più ampi, possiamo solo immaginare quali nuove architetture emergeranno in futuro, rendendo possibile ciò che oggi consideriamo irrealizzabile.





Commenti dalla community